Python爬虫:原来微博上的视频下载链接在这啊
最近看了一下网页版的微博,觉得那上面的视频不错,想获取它上面的下载链接,于是就写了这篇博文。
1. 几个视频播放平台的下载链接的实现
1. 西瓜视频
西瓜视频这个平台上面的视频下载链接一开始就存在于视频播放界面,电脑键盘F12键查看源码,按Ctrl+F搜索script标签,依次点击,可以发现其中一个script标签下有一段json数据,而当前播放的视频的下载链接就在这个json数据中,只不过下载视频进行了加密,根本看不懂,需要找到相应的解密函数即可。(感兴趣的读者可以去看看小编的这篇文章:Python爬虫:从js逆向了解西瓜视频的下载链接的生成)
2.斗鱼视频
斗鱼视频这个平台上的视频下载,使用了ajax技术,在当前播放界面可以找到一个ajax请求,在这个请求里面可以找到当前视频的m3u8文件下载链接(但是这个ajax请求是一个post请求,且请求参数进行了加密,需要模拟加密才能进行访问),之后根绝这个m3u8文件可以下载当前视频的一些ts文件,最后把ts文件合并称mp4文件即可.(感兴趣的读者可以去看看小编的这篇文章:Python爬虫:通过js逆向我发现了斗鱼视频请求参数的加密原理)
3.快手视频
快手视频这个平台上的视频下载和斗鱼类似,但比斗鱼简单很多.(感兴趣的读者可以去看看小编的这篇文章:Python爬虫:给我一个链接,快手视频随便下载)
2. 实现原理
实现原理和斗鱼视频、快手视频的原理一样,找到相应的ajax请求链接即可(这又是一个post请求)
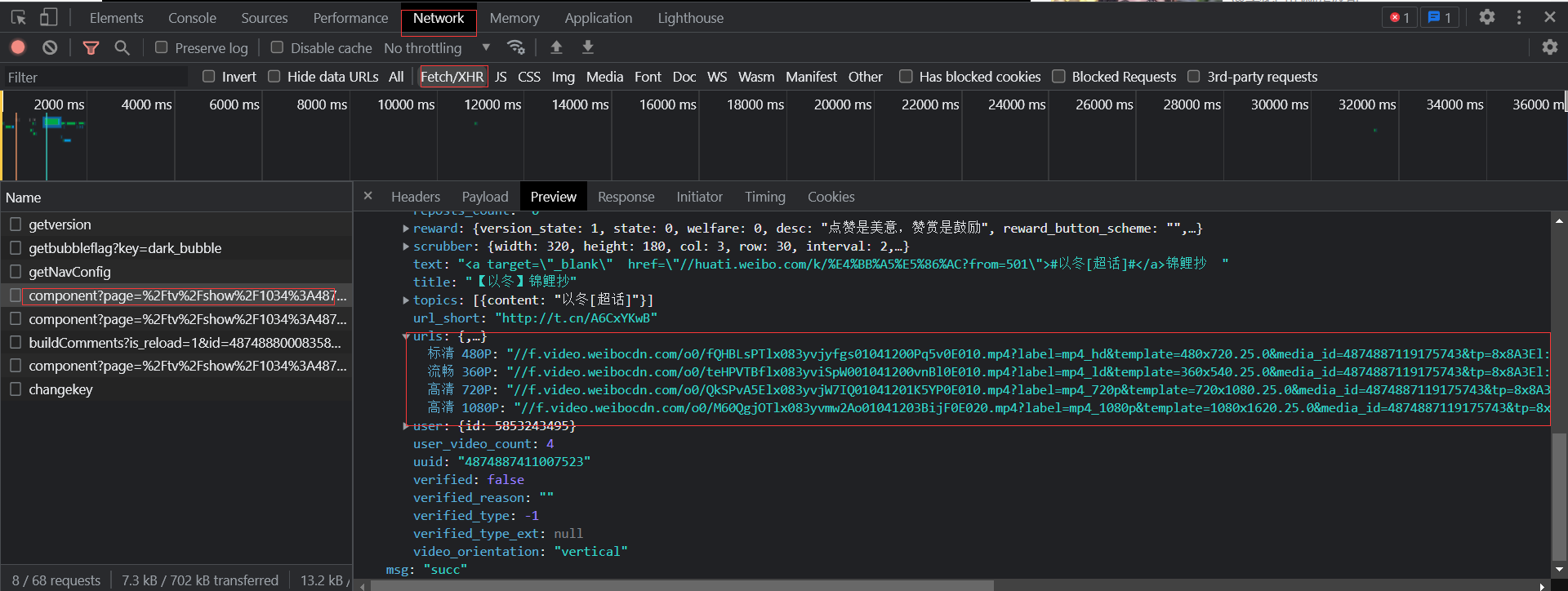
但是如果要使用Python爬虫来得到这个数据,请求头需要添加一些字段,比如cookie、user-agent等字段。

但是不知道小编这个post请求data这个参数是不是写错了(requests模块),还是这个链接存在一定问题,反正试了很多方法,总是获取不到完整数据,最后把post请求改成get请求才最终成功获取。
3. 运行结果
[video(video-fHqZMMbf-1677750262052)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=865253588)(image-https://img-blog.csdnimg.cn/img_convert/ab51fed4277a57c7dca4fa877db89738.jpeg)(title-Python爬虫:抓取微博上的视频下载链接)]
{kind=link}
参考代码如下:
import requests
import json
import re
# https://weibo.com/tv/show/1034:4857185377910909?mid=4857186621067064
video_url = input('输入:')
id = re.findall('https://weibo.com/tv/show/(\d*:\d*)?.*',video_url)[0]
url = 'https://weibo.com/tv/api/component?page=/tv/show/{0}&data={1}'
data_str = '{%22Component_Play_Playinfo%22:{%22oid%22:%22' + id + '%22}}'
url = url.format(id, data_str)
headers = {
"cookie": "SINAGLOBAL=1642093035151.6916.1590980167697; UOR=news.huse.edu.cn,widget.weibo.com,www.baidu.com; SCF=AoITVZf4HS3L4qWC3iYin9ewmWRQdnQsEsKnkUAKVrhUGsrSuJsFtN6Puc1jeCHZyLFnsESBUt7YCk5DWM4I86o.; SUBP=0033WrSXqPxfM72wWs9jqgMF55529P9D9W5yXxXxcVnl70-8qPgRKnCg5JpVF02ReK-E1hMReKep; SUB=_2AkMU3QDBdcPxrAVSmvsVxGnqbYtH-jynCGk3An7uJhMyAxh87n0PqSVutBF-XEV4WnRTgvv_qqEol-0DEUdZBTB_; UPSTREAM-V-WEIBO-COM=b09171a17b2b5a470c42e2f713edace0; _s_tentry=-; Apache=2882565213456.4116.1677573461765; ULV=1677573461958:47:1:1:2882565213456.4116.1677573461765:1669435390809; XSRF-TOKEN=KLbhVzQdbXXP_F7laqGMs0xt; WBPSESS=Dt2hbAUaXfkVprjyrAZT_FgOH_8DbGpQMRQSA1lwg1qH-m_kdZLq1PmsYPFYeK6IewUd4GmxAOEZC3rK48r1iqi82kid-HnqOCAwipsM3hrg5LtskejSkGEhijD2kFHQ8CBnf3q1vzJpVpquSnhK5Q==",
"origin": "https://weibo.com",
"page-referer": "/tv/show/1034:4857185377910909",
"referer": "https://weibo.com/tv/show/1034:4857185377910909?mid=4857186621067064",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4507.400",
}
rsp = requests.get(url=url, headers=headers)
dict2 = json.loads(rsp.text)
urls_dict = dict2['data']['Component_Play_Playinfo']['urls']
for key in urls_dict:
print(key,f'https:{urls_dict.get(key)}')
Python爬虫:原来微博上的视频下载链接在这啊的更多相关文章
- Python 爬虫 Vimeo视频下载链接
python vimeo_d.py https://vimeo.com/228013581 在https://vimeo.com/上看到稀罕的视频 按照上面加上视频的观看地址运行即可获得视频下载链接 ...
- 【Python项目】简单爬虫批量获取资源网站的下载链接
简单爬虫批量获取资源网站的下载链接 项目链接:https://github.com/RealIvyWong/GotDownloadURL 1 由来 自己在收集剧集资源的时候,这些网站的下载链接还要手动 ...
- 获取youku视频下载链接(wireshark抓包分析)
随便说两句 前两天写了一个python脚本,试图以分析网页源码的方式得到优酷视频的下载地址,结果只得到视频的纯播放地址,下载纯播放地址得到的文件也无法正常播放视频. 这里共享一下播放地址得到的方法(想 ...
- 使用python+xpath 获取https://pypi.python.org/pypi/lxml/2.3/的下载链接
使用python+xpath 获取https://pypi.python.org/pypi/lxml/2.3/的下载链接: 使用requests获取html后,分析html中的标签发现所需要的链接在& ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- Python——操作smb文件服务器(上传和下载)
最近在做上传和下载,然后文件比较大和多,就用到了文件服务器,文件服务器是实体机 ,不是在本地, 然后用python 通过pysmb模块就可以直接进行操作 mac选择前往.连接服务器去查看文件服务器里都 ...
- python爬虫实践——爬取“梨视频”
一.爬虫的基本过程: 1.发送请求(请求库:request,selenium) 2.获取响应数据()服务器返回 3.解析并提取数据(解析库:re,BeautifulSoup,Xpath) 4.保存数据 ...
- 【Python学习 】Python实现的FTP上传和下载功能
一.背景 最近公司的一些自动化操作需要使用Python来实现FTP的上传和下载功能.因此参考网上的例子,撸了一段代码来实现了该功能,下面做个记录. 二.ftplib介绍 Python中默认安装的ftp ...
- Python爬虫:微博粉丝列表
前言 本来打算做一个关于微博粉丝列表的爬虫,可以统计一下某个微博账号的粉丝里面,僵尸粉(水军)的数量,大V数量. 结果写完爬虫才发现,现在微博只给人看粉丝列表的前5页.......哈哈,好吧.挺无奈的 ...
随机推荐
- Rust学习之旅(读书笔记):枚举 (Enum)
Rust学习之旅(读书笔记):枚举 (Enum) C 语言的枚举类型很弱,不如后来的语言,也不如之前的语言.在 C 语言里面枚举量就是一个名字,更方便的定义常量.今天读了<The Rust Pr ...
- 记一次 .NET 某工控MES程序 崩溃分析
一:背景 1.讲故事 前几天有位朋友找到我,说他的程序出现了偶发性崩溃,已经抓到了dump文件,Windows事件日志显示的崩溃点在 clr.dll 中,让我帮忙看下是怎么回事,那到底怎么回事呢? 上 ...
- JavaScript:立即执行函数
想象一下,如果我希望某个代码块,只执行一次,就不再执行,应该怎么办? 代码块肯定是用函数来表示,执行肯定是调用函数,但是确保只执行一次,该怎么办? 我们为什么可以多次调用函数,因为函数名指向了函数的内 ...
- java计算器༼༎ຶᴗ༎ຶ༽༼༎ຶᴗ༎ຶ༽༼༎ຶᴗ༎ຶ༽༼༎ຶᴗ༎ຶ༽,又是掉发的一天
题目: 给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值. 注意:不允许使用任何将字符串作为数学表达式计算的内置函数,比如 eval() . 示例 1: 输入:s = " ...
- Spring学习笔记 - 第三章 - AOP与Spring事务
原文地址:Spring学习笔记 - 第三章 - AOP与Spring事务 Spring 学习笔记全系列传送门: Spring学习笔记 - 第一章 - IoC(控制反转).IoC容器.Bean的实例化与 ...
- 道长的算法笔记:KMP算法及其各种变体
(一)如何优化暴力算法 Waiting... (二)KMP模板 KMP 算法的精髓在于 \(next\) 数组,\(next[i]=j\) 代表 \(p[1,j]=p[i-j+1,i]\),\(nex ...
- 通过Docker启动DB2,并在Spring Boot整合DB2
1 简介 DB2是IBM的一款优秀的关系型数据库,简单学习一下. 2 Docker安装DB2 为了快速启动,直接使用Docker来安装DB2.先下载镜像如下: docker pull ibmcom/d ...
- github下载后的文件,winrar打开中文是乱码
是因为编码问题,通过7Z解压后正常
- ChatGPT 背后的“功臣”——RLHF 技术详解
OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮,它面对多种多样的问题对答如流,似乎已经打破了机器和人的边界.这一工作的背后是大型语言模型 (Large Language Mode ...
- html内容超宽后,缩小可视区域后,会引起部分背景色宽度出现显示异常情况,解决如下: