python将一行多字符转换为多行单字符方法
笔者这次是第一次写东西,主要是想把在运用中的一些实例给记录下来,分享给那些和笔者有同样需求的人。可能分享的方法有些累赘或者不准确,还望各位大佬勿喷,因为笔者也是python小白,这些都是通过搜索汇总得出来的。
需求:
原数据格式:

我们要变成下面的样子:(这里是做了分组和求和)
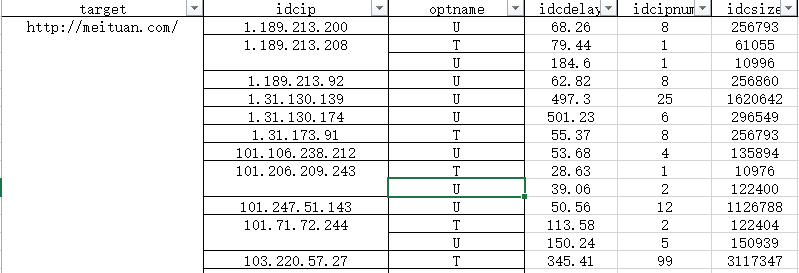
解决需求:
#数据是直接从数据库中查出来的,所以直接导入excel的数据,也可以直接连数据进行查询。
import pandas as pd
info_new2=pd.read_excel("E:/路径/文件名.xlsx", sheet_name='sheet名')
#将网站和运营商设置为索引
info_1 = info_new2.set_index(['target','optname'])
print(info_1)
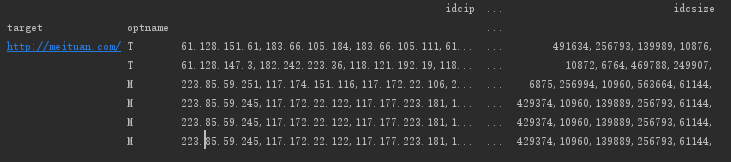
#筛选出IP字段
ip = info_1['idcip']
#将idcip列以‘,’分开,分成多列
ipdf = ip.str.split(',',expand = True)
#将列转换为行
ip = ipdf.stack()
#将最后一级索引删除
ip = ip.reset_index(drop=True,level=-1)
#再调用一次reset_index,会自动进行笛卡尔乘积
ipdf = ip.reset_index()
#将自动生成的0列进行重命名
ipdf = ipdf.rename(columns={0:'idcip'})
print(ipdf)
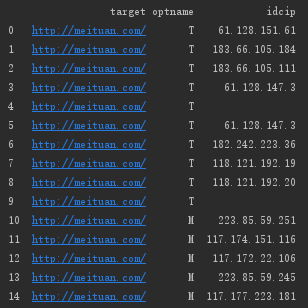
#后面将idcsize,idcdelay,idcipnum进行同样的操作。只是这三个字段在后面会求和计算,需要将类型转换为数字型。
#将时延列有文本转为数字型
info_delay= pd.to_numeric(delaydf['idcdelay'],errors='coerce')
#合并,按照网站和运营商和IP合并
info_two=pd.concat([ipdf,info_delay,info_ipnum,info_size],axis=1)
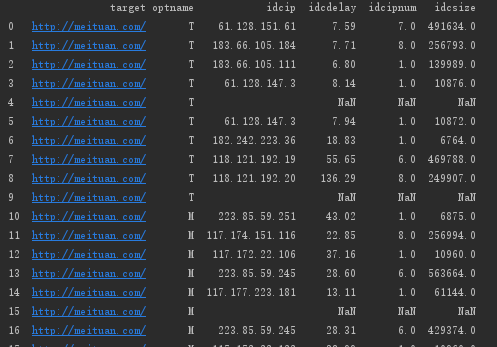
#去除idcdelay列为空的行
info_two = info_two[info_two['idcdelay'].notna()]
#按照'target','idcip','optname'分组,'idcdelay','idcipnum','idcsize'分别求和
info_he=info_two.groupby(['target','idcip','optname'])['idcdelay','idcipnum','idcsize'].sum()
#写入excel
info_he.to_excel("E:\\地址\\文件名.xlsx", sheet_name=sheet名)
大功告成!(第一次发表,希望大家多多包涵!)
python将一行多字符转换为多行单字符方法的更多相关文章
- opencv 车牌字符分割 ANN网络识别字符
最近在复习OPENCV的知识,学习caffe的深度神经网络,正好想起以前做过的车牌识别项目,可以拿出来研究下 以前的环境是VS2013和OpenCV2.4.9,感觉OpenCV2.4.9是个经典版本啊 ...
- python全栈开发从入门到放弃之字符编码
一 了解字符编码的知识储备 1. 计算机基础知识(三幅图) 2. 文本编辑器存取文件的原理(nodepad++,pycharm,word) 打开编辑器就打开了启动了一个进程,是在内存中 ...
- 视频转字符动画-Python-60行代码
更新:2018-5-21 注意: 最后一步播放字符动画使用了只支持类 unix 系统的模块 curses, 因此在windows上是播放不了的... 解决方法: 1. 最近好像有一个移植 https: ...
- 入门Python,看完这篇就行了!
转载请注明出处️ 作者:测试蔡坨坨 原文链接:caituotuo.top/3bbc3146.html 你好,我是测试蔡坨坨. 众所周知,Python语法简洁.功能强大,通过简单的代码就能实现很多实用. ...
- Python基于共现提取《釜山行》人物关系
Python基于共现提取<釜山行>人物关系 一.课程介绍 1. 内容简介 <釜山行>是一部丧尸灾难片,其人物少.关系简单,非常适合我们学习文本处理.这个项目将介绍共现在关系中的 ...
- 基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于python语言的tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的 ...
- python 存储引擎 mysql(库,表, 行) 单表多表操作 (foreign key) sql_mode pymysql模块讲解
##################总结############### mysql 常用数据类型 整型:tinyint int(42亿条左右) bigint 小数:float double dec ...
- python的str,unicode对象的encode和decode方法, Python中字符编码的总结和对比bytes和str
python_2.x_unicode_to_str.py a = u"中文字符"; a.encode("GBK"); #打印: '\xd6\xd0\xce\xc ...
- 把字符转换为 HTML 实体
把字符转换为HTML实体:htmlentities() 把HTML实体转换回字符:html_entity_decode() 把预定义的字符 "<" (小于)和 "& ...
- 如何利用java把文件中的Unicode字符转换为汉字
有些文件中存在Unicode字符和非Unicode字符,如何利用java快速的把文件中的Unicode字符转换为汉字而不影响文件中的其他字符呢, 我们知道虽然java 在控制台会把Unicode字符直 ...
随机推荐
- 这玩意也太猛了!朋友们,我在此严正呼吁大家:端好饭碗,谨防 AI!
你好呀,我是歪歪. 最近几天大火的 ChatGPT 你玩了吗? 如果你不知道它是个什么东西,那么我让它给你来个自我介绍: 说白了,就是一个可以对话的人工智能. 我开始以为就是一个升级版的"小 ...
- gulp报错The following tasks did not complete
代码如下: //引用gulp模块 const gulp = require('gulp'); //使用gulp.task()建立任务 gulp.task('first', () => { con ...
- DHorse日志收集原理
实现原理 基于k8s的日志收集主要有两种方案,一是使用daemoset,另一种是基于sidecar.两种方式各有优缺点,目前DHorse是基于daemoset实现的.如图1所示: 图1 在每个k8s集 ...
- adb环境配置及常用命令
一.adb环境配置 1.下载并安装adb驱动 2.下载adb工具platform-tools.rar,解压放在某个文件夹下 3.右击此电脑->属性->高级系统设置->环境变量-> ...
- linux挖矿处置
挖矿的类型 主动挖矿:用户在个人电脑或服务器使用挖矿程序进行CPU,GPU计算,获取虚拟货币. 被动挖矿:挖矿病毒通过系统漏洞,恶意程序,弱口令等方式入侵服务器,设备感染挖矿病毒后会开始挖掘虚拟货币. ...
- 【Java】线程池梳理
[Java]线程池梳理 前言 线程池:本质上是一种对象池,用于管理线程资源.在任务执行前,需要从线程池中拿出线程来执行.在任务执行完成之后,需要把线程放回线程池.通过线程的这种反复利用机制,可以有效地 ...
- cmd/批处理常用命令
启动新窗口执行命令 ::执行完毕以后,新开的窗口不会自动关闭 start cmd /k echo 123 ::执行完毕以后,新开的窗口会自动关闭 start cmd /C "echo 123 ...
- Redux与前端表格施展“组合拳”,实现大屏展示应用的交互增强
Redux 是 JavaScript 状态容器,提供可预测化的状态管理.它可以用在 react.angular.vue 等项目中, 但与 react 配合使用更加方便一些. Redux 原理图如下,可 ...
- [cocos2d-x]我发现的内存管理机制的一些问题
之前看过的一些文章中关于内存的管理机制讲的非常好,但是我发现它们在谈到每一帧都会创建一个新的内存池的时候,我发现源码并不是这样: PoolManager* PoolManager::getInstan ...
- P5687 [CSP-S2019 江西] 网格图
题面 给定一个 \(n\times m\) 的网格图,行从 \(1\sim n\) 编号,列从 \(1\sim m\) 编号,每个点可用它所在的行编号 \(r\) 与所在的列编号 \(c\) 表示为 ...