论文笔记 - An Explanation of In-context Learning as Implicit Bayesian Inference
这位更是重量级。这篇论文对于概率论学的一塌糊涂的我简直是灾难。
由于 prompt 的分布与预训练的分布不匹配(预训练的语料是自然语言,而 prompt 是由人为挑选的几个样本拼接而成,是不自然的自然语言),作者设预训练的分布为 $p$ 而 prompt 的分布设为 $p_{prompt}$,因此作者认为这两种分布的不符可能是造成 inference 效果不佳的重要原因($S_n$ 为 context):
$$argmax_{y}\;p(y|S_n,\;x_{test})\;\neq argmax_{y}\;p_{prompt}(y|x_{test})$$
但是这种不匹配造成可以通过设置更好的 prompt 减弱,进而提出了 $singal$ 的概念,$singal$ 可以认为是一种任务的明确程度,$singal$ 越大代表任务越明确,得到的结果也准确,例如:一般情况下,One-shot 的效果要比 Few-shot 和 Zero-shot 都要差,例如下面的prompt :
> Albert Einstein was a German. Marie Curie was <token to infer>
这个 context 根本没有明确任务是什么!按照 prompt 的分布这里应该生成的是 Polish,但是按照预训练的分布这里完全可以填 brilliant 什么的,也就是两种分布不匹配的程度被大大放大了。但是如果换成 Few-shot 呢:
> Albert Einstein was German. Mahatma Gandhi was Indian. Karl Heinrich Marx was German. Marie Curie was <token to infer>
这个 context 就很好的描述了任务的目的:判断这些人所属的国家。因此,作为 context 的样本数量增加可以有效增加 $singal$,缩小两种分布的不匹配程度,进而改善效果。
作者进一步总结了几个对 $singal$ 有影响的因素
样本数量
如上文所述,样本越多任务描述越清晰,$singal$ 越大。
输入空间
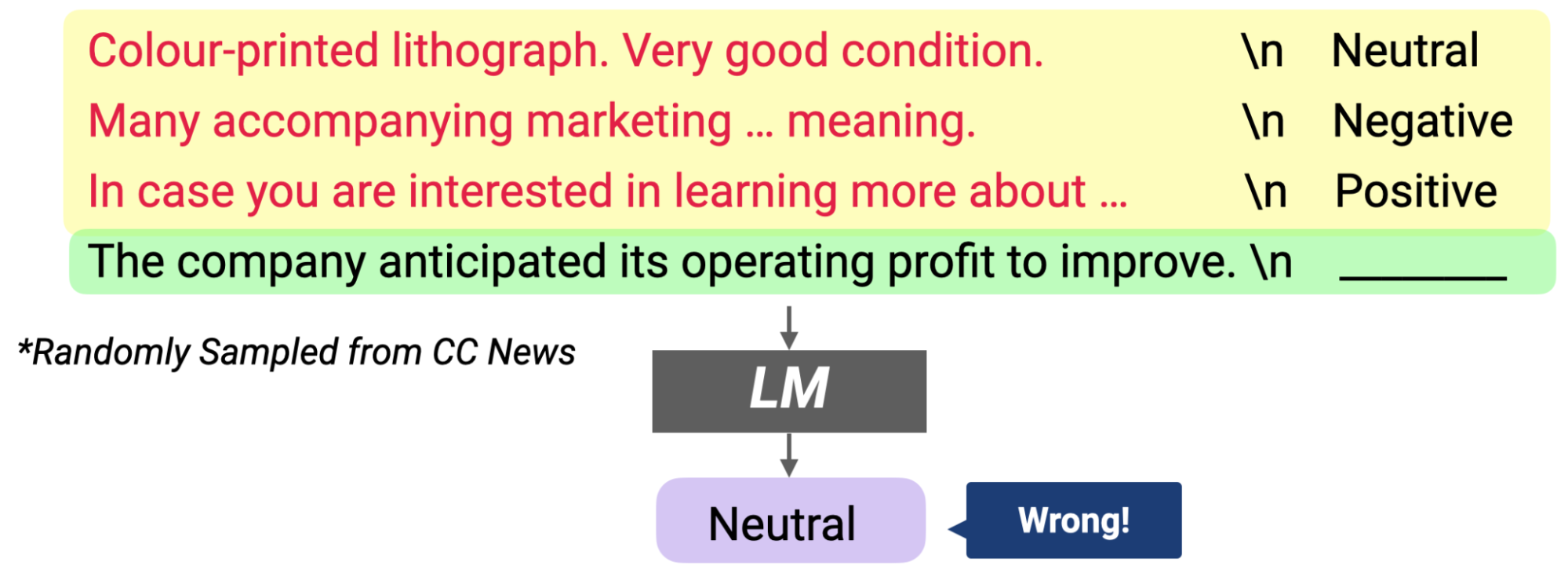
x 随便选的话会使准确率大幅度降低。
输出空间

y 随便选的话也会使准确率大幅度降低。
输入输出的对应关系
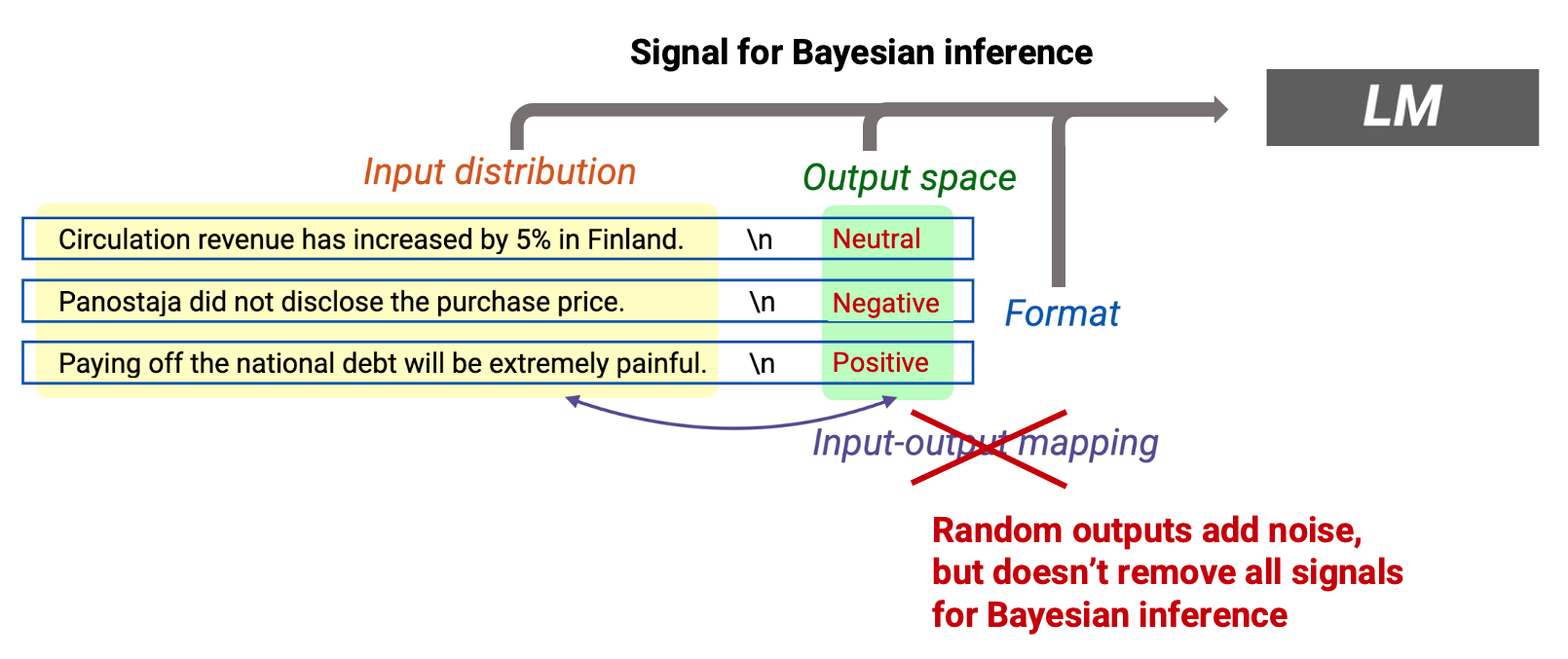
输出的标签在输出空间里面随机选取,对准确率有影响但是没有想象中那么大,进而证明了对 in-context learning 更重要的因素是任务描述,而不是提供的 prompt 是否正确(因为答案错误并没有影响这个任务的目的:情感分类)。
为了使用数学工具进行分析,作者将前文中提到的任务描述定义为 $\theta$,一篇自然语言预料可能包含多个不同的 $\theta \in \Theta$,而一个 prompt 只包含一个 $\theta^*$(例如你考虑你正在写一篇任务传记,你的任务顺序可能是:名字 $\to$ 国籍 $\to$ 职业 $\to$ 成就等包含多个任务,但是在 prompt 中任务顺序是:名字 $\to$ 国籍 $\to$ 名字 $\to$ 国籍 $\to$ 名字 $\to$ 国籍...,只在重复进行一个任务)(国籍 $\to$ 名字这个就是前文提到的分布不匹配,因为自然语言不会出现这样的分布,这种不匹配可以被有利因素补偿),同时我们认为 $\theta^* \in \Theta$(我们认为 icl 要做的任务一定在预训练的语料中出现过了)。
$$p(y|S_n,x_{test})=\int_{\theta} p(y|S_n,\;x_{test},\;\theta)p(\theta | S_n,\;x_{test})\, \mathrm{d}x$$
$$\propto\;\int_{\theta} p(y|S_n,\;x_{test},\;\theta)p(S_n,\;x_{test} | \theta)p(\theta)\, \mathrm{d}x \;\;\;\;(Bayes'\;rule,\;drop\;the\;constant\;\frac{1}{p(S_n,\;x_{test})})$$
$$\propto\; \int_{\theta} p(y|S_n,\;x_{test},\;\theta) \frac{p(S_n,\;x_{test} | \theta)}{p(S_n,\;x_{test} | \theta^*)} p(\theta)\, \mathrm{d}x\;\;\;\;(divided\;by\;a\;constant)$$
待补充。。。
论文笔记 - An Explanation of In-context Learning as Implicit Bayesian Inference的更多相关文章
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- 论文笔记《Spatial Memory for Context Reasoning in Object Detection》
好久不写论文笔记了,不是没看,而是很少看到好的或者说值得记的了,今天被xinlei这篇paper炸了出来,这篇被据老大说xinlei自称idea of the year,所以看的时候还是很认真的,然后 ...
- 论文笔记:A Review on Deep Learning Techniques Applied to Semantic Segmentation
A Review on Deep Learning Techniques Applied to Semantic Segmentation 2018-02-22 10:38:12 1. Intr ...
- 论文笔记 — MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching
论文:https://github.com/ei1994/my_reference_library/tree/master/papers 本文的贡献点如下: 1. 提出了一个新的利用深度网络架构基于p ...
- (论文笔记Arxiv2021)Walk in the Cloud: Learning Curves for Point Clouds Shape Analysis
目录 摘要 1.引言 2.相关工作 3.方法 3.1局部特征聚合的再思考 3.2 曲线分组 3.3 曲线聚合和CurveNet 4.实验 4.1 应用细节 4.2 基准 4.3 消融研究 5.总结 W ...
- 论文笔记 Spatial contrasting for deep unsupervised learning
在我们设计无监督学习模型时,应尽量做到 网络结构与有监督模型兼容 有效利用有监督模型的基本模块,如dropout.relu等 无监督学习的目标是为有监督模型提供初始化的参数,理想情况是"这些 ...
- 论文笔记之:DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation 2017-06-12 21:29:06 引言部分: 本文提出 ...
- 【论文笔记】多任务学习(Multi-Task Learning)
1. 前言 多任务学习(Multi-task learning)是和单任务学习(single-task learning)相对的一种机器学习方法.在机器学习领域,标准的算法理论是一次学习一个任务,也就 ...
- 论文笔记——NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING
论文地址:https://arxiv.org/abs/1611.01578 1. 论文思想 强化学习,用一个RNN学一个网络参数的序列,然后将其转换成网络,然后训练,得到一个反馈,这个反馈作用于RNN ...
随机推荐
- jsp获取下拉框组件的值
jsp获取下拉框组件的值 1.首先,写一个带有下拉框的前台页 1 <%@ page language="java" contentType="text/html; ...
- 未关中断情况下的hardlock
最近遇到一例crash,3.10内核,hardlock,查看对应的堆栈,中断是使能的. 查看对应的hrtimer_interrupts和hrtimer_interrupt_save的值,发现确实相等. ...
- NOI 2019 省选模拟赛 T1【JZOJ6082】 染色问题(color) (多项式,数论优化)
题面 一根长为 n 的无色纸条,每个位置依次编号为 1,2,3,-,n ,m 次操作,第 i 次操作把纸条的一段区间 [l,r] (l <= r , l,r ∈ {1,2,3,-,n})涂成颜色 ...
- XYX错误集
(频数递减) # 数据范围:没开Long Long (*inf^2) # while 打成了 if ,if 打成了 while(*inf^2) # 换根DP:两个dfs调用错误 (*inf) # ZK ...
- iOS WebRTC 点对点实时音视频流程介绍
前言 公司某个项目需要接入音视频即时通讯, 功能类似微信的拨打视频通话,语音通话的场景.那么对于音视频通讯会用到什么技术呢?没错,它就是 WebRTC . 什么是WebRTC WebRTC,名称源自网 ...
- KingbaseESV8R6临时表和全局临时表
临时表概述 临时表用于存放只存在于事务或会话期间的数据.临时表中的数据对会话是私有的,每个会话只能看到和修改自己会话的数据. 您可以创建全局(global)临时表或本地(locall)临时表. 下表列 ...
- 小结event.target与this
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <t ...
- 【读书笔记】C#高级编程 第三章 对象和类型
(一)类和结构 类和结构实际上都是创建对象的模板,每个对象都包含数据,并提供了处理和访问数据的方法. 类和结构的区别:内存中的存储方式.访问方式(类是存储在堆上的引用类型,结构是存储在栈的值类型)和它 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- 大家都在用MySQL count(*)统计总数,到底有什么问题?
在日常开发工作中,我经常会遇到需要统计总数的场景,比如:统计订单总数.统计用户总数等.一般我们会使用MySQL 的count函数进行统计,但是随着数据量逐渐增大,统计耗时也越来越长,最后竟然出现慢查询 ...