使用 SpeechT5 进行语音合成、识别和更多功能
我们很高兴地宣布,SpeechT5 现在可用于 Transformers (一个开源库,提供最前沿的机器学习模型实现的开源库)。
SpeechT5 最初见于微软亚洲研究院的这篇论文 SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing。论文作者发布的 官方仓库 可在 Hugging Face Hub 上找到。
如果您想直接尝试,这里有一些在 Spaces 上的演示:
介绍
SpeechT5 不是一种,也不是两种,而是一种架构中的三种语音模型。
它可以做:
- 语音到文本,用于自动语音识别或说话人识别;
- 文本转语音,用于合成音频;
- 语音到语音,用于在不同语音之间进行转换或执行语音增强。
SpeechT5 背后的主要思想是在文本到语音、语音到文本、文本到文本和语音到语音数据的混合体上预训练单个模型。这样,模型可以同时从文本和语音中学习。这种预训练方法的结果是一个模型,该模型具有由文本和语音共享的隐藏表示的 统一空间。
SpeechT5 的核心是一个常规的 Transformer 编码器 - 解码器 模型。就像任何其他 Transformer 一样,编码器 - 解码器网络使用隐藏表示对序列到序列的转换进行建模。这个 Transformer 骨干对于所有 SpeechT5 任务都是一样的。
为了使同一个 Transformer 可以同时处理文本和语音数据,添加了所谓的 pre-nets 和 post-nets。 per-nets 的工作是将输入文本或语音转换为 Transformer 使用的隐藏表示。 post-nets 从 Transformer 获取输出并将它们再次转换为文本或语音。
下图展示了 SpeechT5 的架构 (摘自 原始论文)。
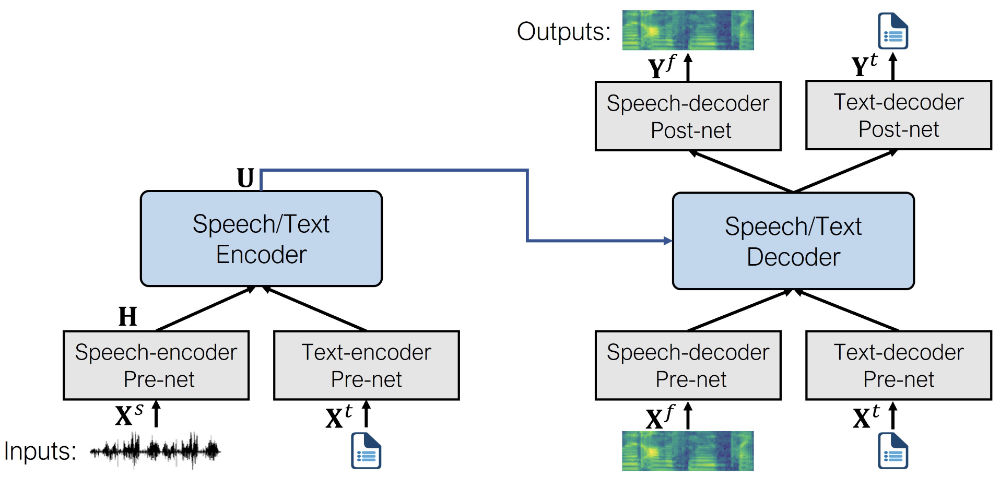
在预训练期间,同时使用所有的 per-nets 和 post-nets 。预训练后,整个编码器 - 解码器主干在单个任务上进行微调。这种经过微调的模型仅使用特定于给定任务的 per-nets 和 post-nets 。例如,要将 SpeechT5 用于文本到语音转换,您需要将文本编码器 per-nets 交换为文本输入,将语音解码器 per-nets 和 post-nets 交换为语音输出。
注意: 即使微调模型一开始使用共享预训练模型的同一组权重,但最终版本最终还是完全不同。例如,您不能采用经过微调的 ASR 模型并换掉 per-nets 和 post-nets 来获得有效的 TTS 模型。 SpeechT5 很灵活,但不是 那么 灵活。
文字转语音
SpeechT5 是我们添加到 Transformers 的 第一个文本转语音模型,我们计划在不久的将来添加更多的 TTS 模型。
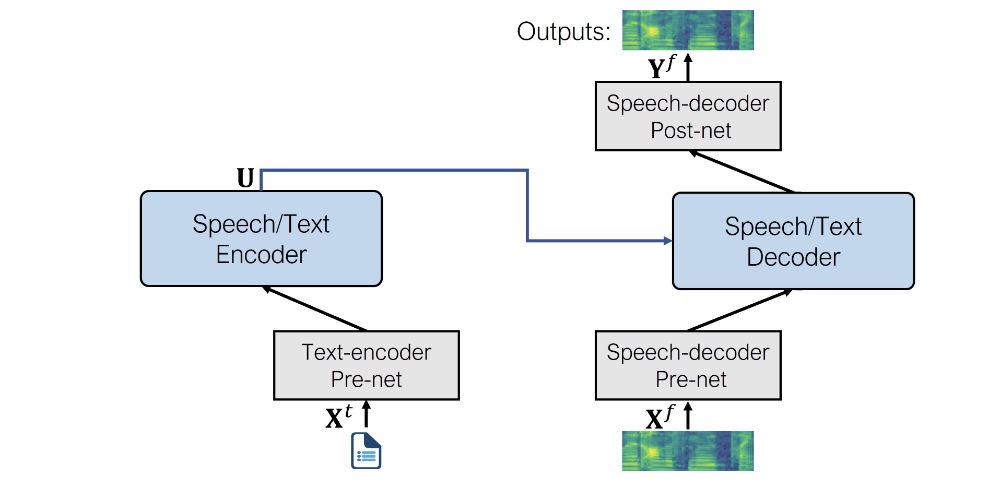
对于 TTS 任务,该模型使用以下 per-net 和 post-net:
- 文本编码器 per-net 。一个文本嵌入层,将文本标记映射到编码器期望的隐藏表示。类似于 BERT 等 NLP 模型中发生的情况。
- 语音解码器 per-net 。这将对数梅尔频谱图作为输入,并使用一系列线性层将频谱图压缩为隐藏表示。此设计取自 Tacotron 2 TTS 模型。
- 语音解码器 post-net 。这预测了一个残差以添加到输出频谱图中并用于改进结果,同样来自 Tacotron 2。
微调模型的架构如下所示。
以下是如何使用 SpeechT5 文本转语音模型合成语音的完整示例。您还可以在 交互式 Colab 笔记本 中进行操作。
SpeechT5 在最新版本的 Transformers 中尚不可用,因此您必须从 GitHub 安装它。还要安装附加的依赖语句,然后重新启动运行。
pip install git+https://github.com/huggingface/transformers.git
pip install sentencepiece
首先,我们从 Hub 加载 微调模型,以及用于标记化和特征提取的处理器对象。我们将使用的类是 SpeechT5ForTextToSpeech。
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
接下来,标记输入文本。
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")
SpeechT5 TTS 模型不限于为单个说话者创建语音。相反,它使用所谓的 Speaker Embeddings来捕捉特定说话者的语音特征。我们将从 Hub 上的数据集中加载这样一个 Speaker Embeddings。
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
Speaker Embeddings 是形状为 (1, 512) 的张量。这个特定的 Speaker Embeddings 描述了女性的声音。使用 此脚本 从 CMU ARCTIC 数据集获得嵌入 /utils/prep_cmu_arctic_spkemb.py,任何 X-Vector 嵌入都应该有效。
现在我们可以告诉模型在给定输入标记和 Speaker Embeddings 的情况下生成语音。
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
这会输出一个形状为 (140, 80) 的张量,其中包含对数梅尔谱图。第一个维度是序列长度,它可能在运行之间有所不同,因为语音解码器 per-net 总是对输入序列应用 dropout。这为生成的语音增加了一些随机变化。
要将预测的对数梅尔声谱图转换为实际的语音波形,我们需要一个 声码器。理论上,您可以使用任何适用于 80-bin 梅尔声谱图的声码器,但为了方便起见,我们在基于 HiFi-GAN 的 Transformers 中提供了一个。 此声码器的权重,以及微调 TTS 模型的权重,由 SpeechT5 的原作者友情提供。
加载声码器与任何其他 Transformers 模型一样简单。
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
要从频谱图中制作音频,请执行以下操作:
with torch.no_grad():
speech = vocoder(spectrogram)
我们还提供了一个快捷方式,因此您不需要制作频谱图的中间步骤。当您将声码器对象传递给 generate_speech 时,它会直接输出语音波形。
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
最后,将语音波形保存到文件中。 SpeechT5 使用的采样率始终为 16 kHz。
import soundfile as sf
sf.write("tts_example.wav", speech.numpy(), samplerate=16000)
输出听起来像这样 (下载音频)
这就是 TTS 模型!使这个声音好听的关键是使用正确的 Speaker Embeddings。
您可以在 Spaces 上进行 交互式演示。
语音转语音的语音转换
从概念上讲,使用 SpeechT5 进行语音转语音建模与文本转语音相同。只需将文本编码器 per-net 换成语音编码器 per-net 即可。模型的其余部分保持不变。
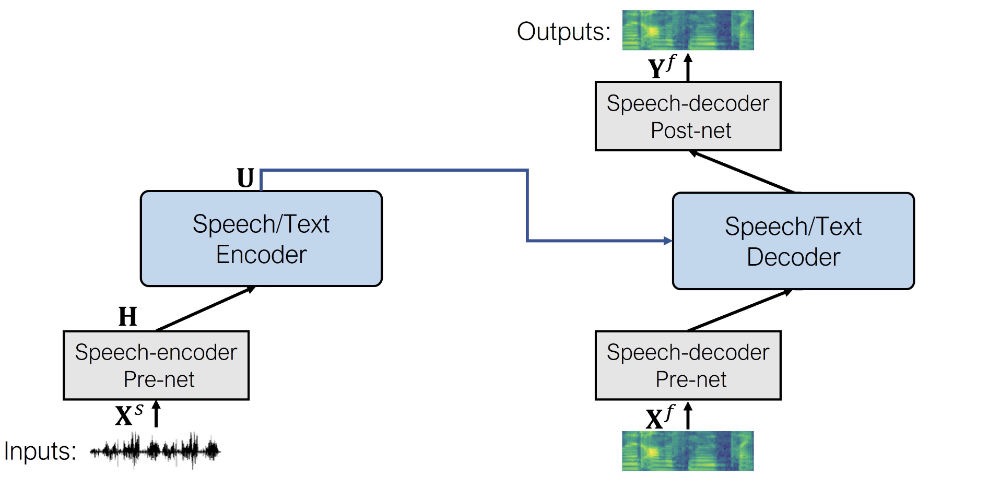
语音编码器 per-net 与 wav2vec 2.0 中的特征编码模块相同。它由卷积层组成,这些卷积层将输入波形下采样为一系列音频帧表示。
作为语音到语音任务的示例,SpeechT5 的作者提供了一个 微调检查点 用于进行语音转换。要使用它,首先从 Hub 加载模型。请注意,模型类现在是 SpeechT5ForSpeechToSpeech。
from transformers import SpeechT5Processor, SpeechT5ForSpeechToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_vc")
model = SpeechT5ForSpeechToSpeech.from_pretrained("microsoft/speecht5_vc")
我们需要一些语音音频作为输入。出于本示例的目的,我们将从 Hub 上的小型语音数据集加载音频。您也可以加载自己的语音波形,只要它们是单声道的并且使用 16 kHz 的采样率即可。我们在这里使用的数据集中的样本已经采用这种格式。
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset = dataset.sort("id")
example = dataset[40]
接下来,对音频进行预处理,使其采用模型期望的格式。
sampling_rate = dataset.features["audio"].sampling_rate
inputs = processor(audio=example["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
与 TTS 模型一样,我们需要 Speaker Embeddings。这些描述了目标语音听起来像什么。
import torch
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
我们还需要加载声码器以将生成的频谱图转换为音频波形。让我们使用与 TTS 模型相同的声码器。
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
现在我们可以通过调用模型的 generate_speech 方法来执行语音转换。
speech = model.generate_speech(inputs["input_values"], speaker_embeddings, vocoder=vocoder)
import soundfile as sf
sf.write("speech_converted.wav", speech.numpy(), samplerate=16000)
更改为不同的声音就像加载新的 Speaker Embeddings 一样简单。您甚至可以嵌入自己的声音!
原始输入下载 (下载)
转换后的语音 (下载)
请注意,此示例中转换后的音频在句子结束前被切断。这可能是由于两个句子之间的停顿导致 SpeechT5 (错误地) 预测已经到达序列的末尾。换个例子试试,你会发现转换通常是正确的,但有时会过早停止。
您可以进行 交互式演示。
用于自动语音识别的语音转文本
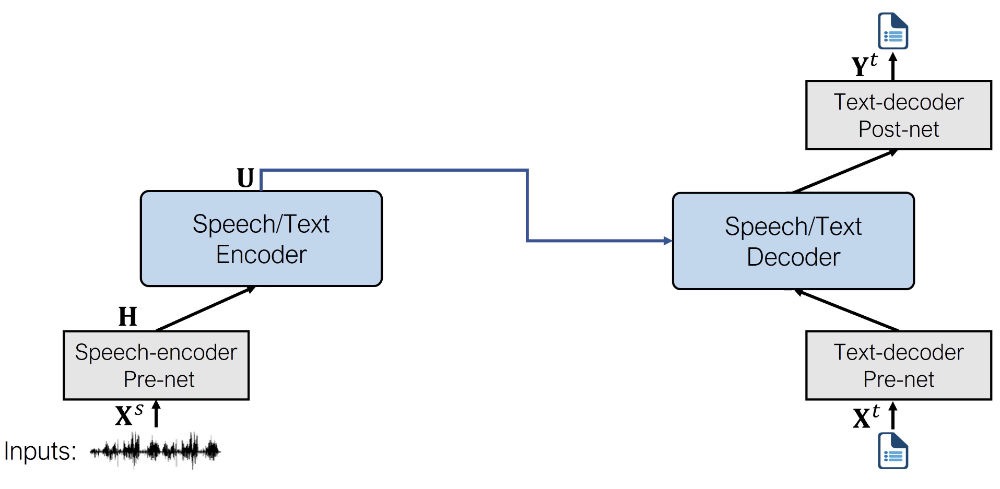
ASR 模型使用以下 pre-nets 和 post-net:
- 语音编码器 per-net。这是语音到语音模型使用的相同预网,由来自 wav2vec 2.0 的 CNN 特征编码器层组成。
- 文本解码器 per-net。与 TTS 模型使用的编码器预网类似,它使用嵌入层将文本标记映射到隐藏表示中。 (在预训练期间,这些嵌入在文本编码器和解码器预网之间共享。)
- 文本解码器 post-net。这是其中最简单的一个,由一个线性层组成,该层将隐藏表示投射到词汇表上的概率。
微调模型的架构如下所示。
如果您之前尝试过任何其他 Transformers 语音识别模型,您会发现 SpeechT5 同样易于使用。最快的入门方法是使用流水线。
from transformers import pipeline
generator = pipeline(task="automatic-speech-recognition", model="microsoft/speecht5_asr")
作为语音音频,我们将使用与上一节相同的输入,任何音频文件都可以使用,因为流水线会自动将音频转换为正确的格式。
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset = dataset.sort("id")
example = dataset[40]
现在我们可以要求流水线处理语音并生成文本转录。
transcription = generator(example["audio"]["array"])
打印转录给出:
a man said to the universe sir i exist
听起来完全正确! SpeechT5 使用的分词器非常基础,是字符级别工作。因此,ASR 模型不会输出任何标点符号或大写字母。
当然也可以直接使用模型类。首先,加载 微调模型 和处理器对象。该类现在是 SpeechT5ForSpeechToText。
from transformers import SpeechT5Processor, SpeechT5ForSpeechToText
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_asr")
model = SpeechT5ForSpeechToText.from_pretrained("microsoft/speecht5_asr")
预处理语音输入:
sampling_rate = dataset.features["audio"].sampling_rate
inputs = processor(audio=example["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
最后,告诉模型从语音输入中生成文本标记,然后使用处理器的解码功能将这些标记转换为实际文本。
predicted_ids = model.generate(**inputs, max_length=100)
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
播放 语音到文本任务 的交互式演示。
结论
SpeechT5 是一个有趣的模型,因为与大多数其他模型不同,它允许您使用相同的架构执行多项任务。只有 per-net 和 post-net 发生变化。通过在这些组合任务上对模型进行预训练,它在微调时变得更有能力完成每个单独的任务。
目前我们只介绍了语音识别 (ASR)、语音合成 (TTS) 和语音转换任务,但论文还提到该模型已成功用于语音翻译、语音增强和说话者识别。如此广泛的用途,前途不可估量!
原文: Speech Synthesis, Recognition, and More With SpeechT5
作者: Mathijs Hollemans
译者: innovation64 (李洋)
审校、排版: zhongdongy (阿东)
使用 SpeechT5 进行语音合成、识别和更多功能的更多相关文章
- Android 上拉加载更多功能
前几天看了github上面的例子,参照它的实现,自己又稍微改了一点,往项目里面增加了一个上拉加载更多功能.具体的实现如下: 首先要重写ListView: import android.content. ...
- jQuery+php+Ajax文章列表点击加载更多功能
jQuery+php+Ajax实现的一个简单实用的文章列表点击加载更多功能,点击加载更多按钮,文章列表加载更多数据,加载中有loading动画效果. js部分: <script type=&qu ...
- React-Native 之 GD (十一)加载更多功能完善 及 跳转详情页
1.加载更多功能完善 GDHome.js /** * 首页 */ import React, { Component } from 'react'; import { StyleSheet, Text ...
- (数据科学学习手札134)pyjanitor:为pandas补充更多功能
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 pandas发展了如此多年,所包含的功能已 ...
- 分页插件思想:pc加载更多功能和移动端下拉刷新加载数据
感觉一个人玩lol也没意思了,玩会手机,看到这个下拉刷新功能就写了这个demo! 这个demo写的比较随意,咱不能当做插件使用,基本思想是没问题的,要用就自己封装吧! 直接上代码分析下吧! 布局: & ...
- 语音合成,语音播报功能(系统)-b
第一次接触语音合成,只实现了很简单的功能,记录一下,以后免得去网上四处找资料 最近在做高德地图导航的时候有个语音播报的功能,高德sdk已经提供了要语音的字符串.我要做的就是把这些字符串读出声音来即可. ...
- 内核调试神器SystemTap — 更多功能与原理(三)
a linux trace/probe tool. 官网:https://sourceware.org/systemtap/ 用户空间 SystemTap探测用户空间程序需要utrace的支持,3.5 ...
- flask 第六章 人工智能 百度语音合成 识别 NLP自然语言处理+simnet短文本相似度 图灵机器人
百度智能云文档链接 : https://cloud.baidu.com/doc/SPEECH/index.html 1.百度语音合成 概念: 顾名思义,就是将你输入的文字合成语音,例如: from a ...
- Android 开发 上拉加载更多功能实现
实现思维 开始之前先废话几句,Android系统没有提供上拉加载的控件,只提供了下拉刷新的SwipeRefreshLayout控件.这个控件我们就不废话,无法实现上拉刷新的功能.现在我们说说上拉加载更 ...
- 微信小程序——收起和查看更多功能
项目中做一些列表的时候,可能会需要做到 查看更多 及 收起功能,如下图所示: 大概的需求就是默认只显示2条,点击[查看更多]显示全部,点击[收起]还原. 实现的方法千万种.我来讲一下我的实现思路: 1 ...
随机推荐
- mysql5.7主从多线程同步
数据库复制的主要性能问题就是数据延时 为了优化复制性能,Mysql 5.6 引入了 "多线程复制" 这个新功能 但 5.6 中的每个线程只能处理一个数据库,所以如果只有一个数据库, ...
- 物联网5G工业网关的特点和应用场景
BMG5100 系列产品,是一款工业级 5G 千兆物联网网关.集数据管理.智能采集.多种协议 转换.5G/4G 无线通信.数据处理转发.VPN 虚拟专网.本地存储.WIFI 覆盖等功能于一体. 产品特 ...
- bzoj 3669
思想基本同bzoj 2594,但是多了一步 首先我们发现这时的边有两个属性了,因此我们考虑先去掉其中一者的限制 我们把所有边按$a$大小排序,然后从小到大加入维护的最小生成树 每次加边时都按照$b$的 ...
- Mybatis配置报错:Failed to configure a DataSource: 'url' attribute is not specified and no embe...
问题分析及解决方案 问题原因: Mybatis没有找到合适的加载类,其实是大部分spring - datasource - url没有加载成功,分析原因如下所示. DataSourceAutoConf ...
- 【闫式dp分析法】
- requests模块之post请求传参json和data区别
post请求参数到底是传data还是json,此时要看请求头里的content-type类型 请求头中content-type为application/json, 为json形式,post请求使用js ...
- 调试以及Linq查询
1.调试的步骤 调试快捷键: F10逐过程(不会进入函数内部,直接获取函数运行结果) F11逐语句(会进入函数) F5执行,如果调试中多个断点,按F5执行到下一个断点 出现黄色箭头表示执行到这一句,但 ...
- StringIO 和 BytesIO
StringIO 要把 str 字符串写入内存中,我们需要创建一个 StringIO 对象,然后像文件一样对读取内容.其中 StringIO 中多了一个 getvalue() 方法,目的是用于获取写入 ...
- RKO组——冲刺随笔(2)
这个作业属于哪个课程 至诚软工实践F班 这个作业要求在哪里 第五次团队作业:项目冲刺 这个作业的目标 记录冲刺计划.要求包括当天会议照片.会议内容以及项目燃尽图(项目进度) 1.昨日进展 已开始着手模 ...
- UG二次开发-CAM-获取修改路径参数
项目中要获取路径参数,网上大多是C++的例子,而本项目是用C#写的,探索了下,记录下. 以获取某条路径的刀具号为例,其他参数依此类推. using System; using System.Colle ...