python信息检索实验之向量空间模型与布尔检索
import numpy as np
import pandas as pd
import math
def bool_retrieval(string):
if string.count('and')*string.count('or') > 0:
a = string[:string.find('or')]
b = string[string.find('or')+3:]
bool_retrieval(a)
bool_retrieval(b)
elif 'or' in string:
key = string.split(' or ')
for i in range(len(documentbase)):
for j in range(len(key)):
if key[j] in documentbase[i]:
print('D%d:'%(i+1),documentbase[i])
elif 'and' in string:
key = string.split(' ')
del key[key.index('and')]
for i in range(len(documentbase)):
flag = 1
for j in range(len(key)):
if key[j] not in documentbase[i]:
flag = 0
break
if(flag):
print('D%d:'%(i+1),documentbase[i])
#统计词项tj在文档Di中出现的次数,也就是词频。
def computeTF(wordSet,split):
tf = dict.fromkeys(wordSet, 0)
for word in split:
tf[word] += 1
return tf
#计算逆文档频率IDF
def computeIDF(tfList):
idfDict = dict.fromkeys(tfList[0],0) #词为key,初始值为0
N = len(tfList) #总文档数量
for tf in tfList: # 遍历字典中每一篇文章
for word, count in tf.items(): #遍历当前文章的每一个词
if count > 0 : #当前遍历的词语在当前遍历到的文章中出现
idfDict[word] += 1 #包含词项tj的文档的篇数df+1
for word, Ni in idfDict.items(): #利用公式将df替换为逆文档频率idf
idfDict[word] = round(math.log10(N/Ni),4) #N,Ni均不会为0
return idfDict #返回逆文档频率IDF字典
#计算tf-idf(term frequency–inverse document frequency)
def computeTFIDF(tf, idfs): #tf词频,idf逆文档频率
tfidf = {}
for word, tfval in tf.items():
tfidf[word] = tfval * idfs[word]
return tfidf
def length(key_list):
num = 0
for i in range(len(key_list)):
num = num + key_list[i][1]**2
return round(math.sqrt(num), 2)
def main():
split1 = D1.split(' ')
split2 = D2.split(' ')
split3 = D3.split(' ')
split4 = D2.split(' ')
split5 = D3.split(' ')
wordSet = set(split1).union(split2,split3,split4,split5) #通过set去重来构建词库
#print(wordSet)
tf1 = computeTF(wordSet,split1)
tf2 = computeTF(wordSet,split2)
tf3 = computeTF(wordSet,split3)
tf4 = computeTF(wordSet,split4)
tf5 = computeTF(wordSet,split5)
#print('tf1:\n',tf1)
idfs = computeIDF([tf1, tf2, tf3, tf4, tf5])
tfidf1 = computeTFIDF(tf1, idfs)
tfidf2 = computeTFIDF(tf2, idfs)
tfidf3 = computeTFIDF(tf3, idfs)
tfidf4 = computeTFIDF(tf4, idfs)
tfidf5 = computeTFIDF(tf5, idfs)
tfidf_list = [tfidf1, tfidf2, tfidf3, tfidf4, tfidf5]
tfidf = pd.DataFrame([tfidf1, tfidf2, tfidf3, tfidf4, tfidf5])
#print(tfidf)
key_tfidf1 = sorted(tfidf1.items(),key=lambda d: d[1], reverse=True)[:keynumber]
key_tfidf2 = sorted(tfidf2.items(),key=lambda d: d[1], reverse=True)[:keynumber]
key_tfidf3 = sorted(tfidf3.items(),key=lambda d: d[1], reverse=True)[:keynumber]
key_tfidf4 = sorted(tfidf4.items(),key=lambda d: d[1], reverse=True)[:keynumber]
key_tfidf5 = sorted(tfidf5.items(),key=lambda d: d[1], reverse=True)[:keynumber]
key_tfidf_list = [key_tfidf1, key_tfidf2, key_tfidf3, key_tfidf4, key_tfidf5]
print('****************通过TDIDF权重排序选取的关键词****************')
for i in range(len(key_tfidf_list)):
print('文档D%d:'%(i+1),key_tfidf_list[i])
#print(key_tfidf_list)
#5.查询与文档Q最相似的文章
q = 'gold silver car'
split_q = q.split(' ') #分词
tf_q = computeTF(wordSet,split_q) #计算Q的词频
tfidf_q = computeTFIDF(tf_q, idfs) #计算Q的tf_idf(构建向量)
key_query = sorted(tfidf_q.items(),key=lambda d: d[1], reverse=True)[:keynumber]
len_key_query = length(key_query)
# vector space
df = pd.DataFrame([tfidf1, tfidf2, tfidf3, tfidf4, tfidf5, tfidf_q])
i = 0
while i < len(df.columns):
if any(df.values.T[i])==0:
df = df.drop(columns=df.columns[i],axis=1)
else:
i = i + 1
print('**************************向量空间***************************')
print(df)
#计算余弦相似度并排序
result = []
for i in range(len(key_tfidf_list)):#对于每篇文档
num = 0
for j in range(len(key_query)):#对于查询式中的每个词
for k in range(len(key_tfidf_list[i])):#对于每篇文档中的每个关键词
if key_query[j][0] == key_tfidf_list[i][k][0]:
num = num + key_query[j][1] * key_tfidf_list[i][k][1]
result.append((i+1,round(num/math.sqrt(len_key_query * length(key_tfidf_list[i])),4)))
result = sorted(result,key=lambda d: d[1], reverse=True)
print('**************************文档排序***************************')
print('按照Query和文档Di的余弦相似度从高到低排序为:')
for i in range(len(result)):
print('cos<D%d,Query> = %.3f'%(result[i][0],result[i][1]))
print('************************************************************')
if __name__=="__main__":
keynumber = 3
#1.声明文档 分词 去重合并
D1 = 'Delivery of gold damaged in a fire'
D2 = 'Delivery of silver arrived in a silver car'
D3 = 'Delivery of gold arrived in a car'
D4 = 'Delivery of gold arrived in a gold ship damaged in a fire'
D5 = 'Delivery of silver arrived in a silver car made of silver'
documentbase = [D1,D2,D3,D4,D5]
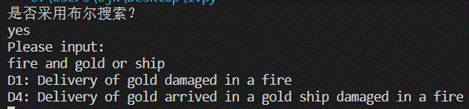
print('是否采用布尔搜索?')
if(input()=='yes'):
print('Please input:')
bool_retrieval(input())
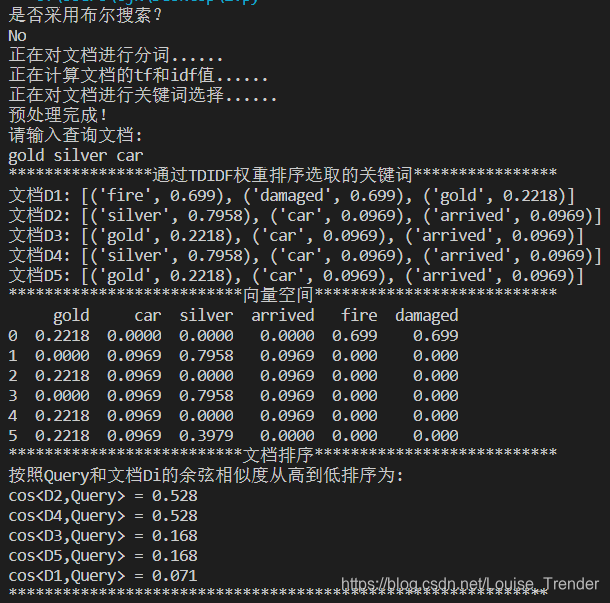
else:
print('正在对文档进行分词......\n正在计算文档的tf和idf值......\n正在对文档进行关键词选择......\n预处理完成!\n请输入查询文档:\ngold silver car')
main()
1、实验环境
Python 3.6.4 、Visual Studio Code
2、实验目的和要求
2.1实验目的:
基于向量空间模型理论,构造一定数量的文本库,采用TFIDF权重进行关键词排序选择,并采用向量夹角余弦判断检索词和文本库中文本的相似度。
2.2基本要求:
①构造一组文本库、关键词、检索内容
②将文本库和检索内容根据关键词转化向量表示
③采用向量夹角余弦判断检索词和文本库中文本的相似度
④按照相似度大小将检索出的内容进行排序
⑤在上述基本要求之上可以整合布尔检索、过滤推送和倒排文档等功能。
3、文档库,查询内容,解题思路
3.1文档库
D1 = 'Delivery of gold damaged in a fire'
D2 = 'Delivery of silver arrived in a silver car'
D3 = 'Delivery of gold arrived in a car'
D4 = 'Delivery of gold arrived in a gold ship damaged in a fire'
D5 = 'Delivery of silver arrived in a silver car made of silver'
3.2查询内容
q = 'gold silver car'
q = 'fire and gold or ship'(布尔检索)
3.3解题思路
(1)向量空间检索
①在已构建的文本库中进行分词,构建词库,然后计算各个文档的tf值和idf值,并用tfidf值对各个关键词进行排序,选出权值最大的3个关键词
②输入查询文档,将其和各文本库文档进行向量空间表示,通过夹角余弦值大小判断相似度并排序
(2)在此基础上进行布尔检索
①若查询表达式中存在多个and和or,即此表达式存在多层嵌套,找出其中的or,将该文档截取成两部分,然后进行递归,直至子文档中不同时存在and和or,进行第二步
②若查询表达式中连接词为or,进行遍历查找,若找到其中一个即输出;若查询表达式中连接词为and,进行遍历查找,若其中一个不存在即退出遍历,直至最后一个必需关键词被查找到,则输出该文档;
4、实验步骤
4.1输入:
①是否采用布尔搜索
②输入查询文档或布尔表达式
4.2输出:
5、讨论和分析
①向量空间算法是根据关键词进行判断的,对于本实验中的一词多义问题难以处理(gold既指金色也指黄金)
②构建的布尔搜索模型较为原始,仅能处理简单的多层嵌套布尔表达式,对于复杂逻辑的多层嵌套布尔表达式并不适用。
③由于文本库所含文档数较少以及文档长度较短,可能存在相似度并列的情况。
python信息检索实验之向量空间模型与布尔检索的更多相关文章
- Jackcard类似度和余弦类似度(向量空间模型)的java实现
版权声明:本文为博主原创文章,地址:http://blog.csdn.net/napoay,转载请留言. 总结Jackcard类似度和余弦类似度. 一.集合的Jackcard类似度 1.1Jackca ...
- Solr相似度名词:VSM(Vector Space Model)向量空间模型
最近想学习下Lucene ,以前运行的Demo就感觉很神奇,什么原理呢,尤其是查找相似度最高的.最优的结果.索性就直接跳到这个问题看,很多资料都提到了VSM(Vector Space Model)即向 ...
- 向量空间模型(Vector Space Model)
搜索结果排序是搜索引擎最核心的构成部分,很大程度上决定了搜索引擎的质量好坏.虽然搜索引擎在实际结果排序时考虑了上百个相关因子,但最重要的因素还是用户查询与网页内容的相关性.(ps:百度最臭名朝著的“竞 ...
- 向量空间模型(Vector Space Model)的理解
1. 问题描述 给你若干篇文档,找出这些文档中最相似的两篇文档? 相似性,可以用距离来衡量.而在数学上,可使用余弦来计算两个向量的距离. \[cos(\vec a, \vec b)=\frac {\v ...
- 向量空间模型(VSM)在文档相似度计算上的简单介绍
C#实现在: http://blog.csdn.net/Felomeng/archive/2009/03/25/4023990.aspx 向量空间模型(VSM:Vector space model)是 ...
- [信息检索] 第一讲 布尔检索Boolean Retrieval
第一讲 布尔检索Boolean Retrieval 主要内容: 信息检索概述 倒排记录表 布尔查询处理 一.信息检索概述 什么是信息检索? Information Retrieval (IR) is ...
- 基于Python的信用评分卡模型分析(二)
上一篇文章基于Python的信用评分卡模型分析(一)已经介绍了信用评分卡模型的数据预处理.探索性数据分析.变量分箱和变量选择等.接下来我们将继续讨论信用评分卡的模型实现和分析,信用评分的方法和自动评分 ...
- Python web前端 04 盒子模型
Python web前端 04 盒子模型 盒子模型是由内容(content).内边距(padding).外边距(margin).边框(border)组成的 一.边框 border #border 边框 ...
- java web应用调用python深度学习训练的模型
之前参见了中国软件杯大赛,在大赛中用到了深度学习的相关算法,也训练了一些简单的模型.项目线上平台是用java编写的web应用程序,而深度学习使用的是python语言,这就涉及到了在java代码中调用p ...
随机推荐
- Luogu1083 借教室 (线段树)
当根都<0,就不行了 #include <iostream> #include <cstdio> #include <cstring> #include &l ...
- Luogu5019 铺设道路 (贪心)
水题,水得好无语 #include <iostream> #include <cstdio> #include <cstring> #include <alg ...
- 我写的蓝宝石留言本php版 v4.5
蓝宝石留言本php版v4.5采用原生php编写,在php5.6~php7.x下调试通过.本留言本使用了utf-8编码. include/config1.php是数据库连接参数的配置文件, includ ...
- 刷题记录:Codeforces Round #739 (Div. 3)
Codeforces Round #739 (Div. 3) 20210907.网址:https://codeforces.com/contest/1560. --(叹). A 不希望出现带" ...
- 【java】学习路线5-public和private、构造方法、this关键字、封装对象、static关键字、main方法结构解析
//一个教务管理系统//知识点清单/*public & private 的区别一个是公开的,一个是私有的,作用域不一样,访问的权限不一样咯如果是用private修饰,则调用者只可以是在当前的作 ...
- 被一位读者赶超,手摸手 Docker 部署 ELK Stack
被一位读者赶超,容器化部署 ELK Stack 你好,我是悟空. 被奇幻"催更" 最近有个读者,他叫"老王",外号"茴香豆泡酒",找我崔更 ...
- Springboot连接数据库(解决报错2)
好家伙, 新建项目,不出意外的话总是会出点意外的 第一天正常运行,第二天就炸了. 1.看报错 百度一下找解决方案 试着将 application.properties中的 com.mysql.jdbc ...
- docker-compose入门--翻译
在这一页,你将学习到如何构建一个简单的python的web应用,并通过Docker compose来运行.这个应用程序使用的是Flask框架,并维护着一个存储在reids里的点击计数器.由于这个案例使 ...
- 如何结合整洁架构和MVP模式提升前端开发体验(二) - 代码实现篇
上一篇文章介绍了整体架构,接下来说说怎么按照上图的分层结构实现下面的增删改查的功能. 代码结构 vue userManage └── List ├── api.ts ├── EditModal │ ├ ...
- C# 常见面试问题
C# 常见面试问题 EntityFramework 数据持久化 C#中的委托是什么?事件是不是一种委托? C#中的委托是一种引用类型,表示具有相同方法签名的方法的引用.类似于函数指针,也就是说它们是指 ...