深度学习之PyTorch实战(5)——对CrossEntropyLoss损失函数的理解与学习
其实这个笔记起源于一个报错,报错内容也很简单,希望传入一个三维的tensor,但是得到了一个四维。
RuntimeError: only batches of spatial targets supported (3D tensors) but got targets of dimension: 4
查看代码报错点,是出现在pytorch计算交叉熵损失的代码。其实在自己手写写语义分割的代码之前,我一直以为自己是对交叉熵损失完全了解的。但是实际上还是有一些些认识不足,所以这里打算复习一下,将其重新梳理一下,才算是透彻的理解了,特地记录下来。
1,交叉熵损失的定义理解
交叉熵是信息论中的一个概念,要想完全理解交叉熵的本质,需要从基础的概念学习。
1.1 信息量
信息量与事件发生的概率有关,某件事情越不可能发生,我们获取的信息量就越大,越可能发生,我们获取的信息量就越小。
假设X是一个离散型随机变量,其取值集合为x,概率分布函数 p(x)=Pr(X=x),则定义事件 X=x0的信息量为:
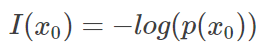
由于是概率,所以P(x0)的取值范围是[0, 1],绘图如下:
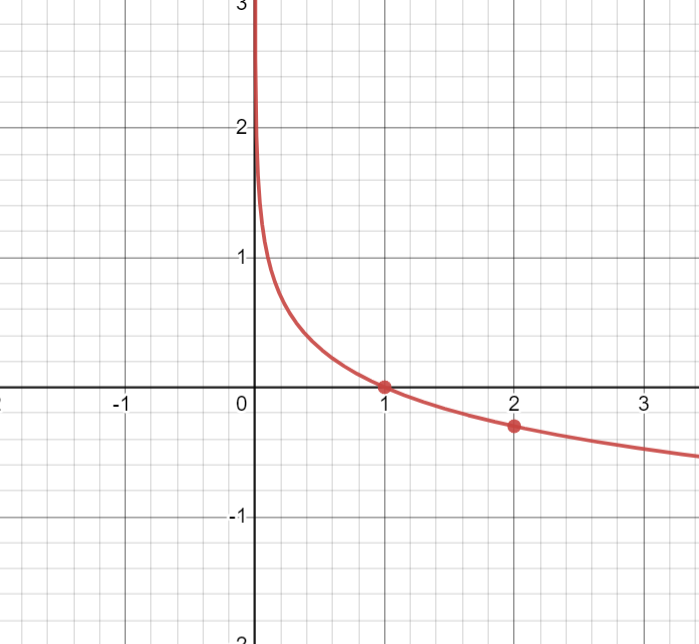
从图像可知,函数符合我们对信息量的直觉,概率越大,信息量越小。
1.2 熵
对于某个事件来说,有多种可能性,每一种可能性都有一个概率 p(Xi),这样就可能计算出某一种可能性的信息量。因为我们上面定义了信息量的定义,而熵就是表达所有信息量的期望,即:
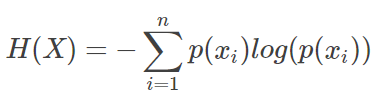
而有一类比较特殊的分布问题,就是0-1分布,对于这类问题你,熵的计算方式可以简化为图下算式:
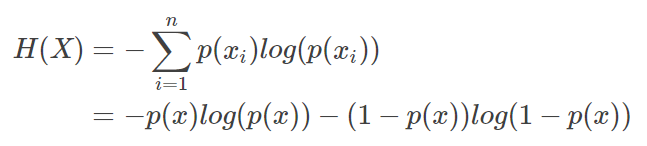
1.3 相对熵(KL散度)
如果我们对同一个随机变量X有两个单独的概率分布 P(x) 和 Q(x)(在机器学习中,P往往是用来表示样本的真实分布,而Q是表示模型预测的分布。),我们可以使用KL散度来衡量这两个分布的差异。计算公式如下:
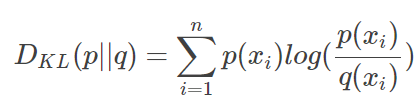
n 为事件的所有可能性,Dkl的值越小,表示P和Q的分布越接近。
1.4 交叉熵
对上式变形可以得到:
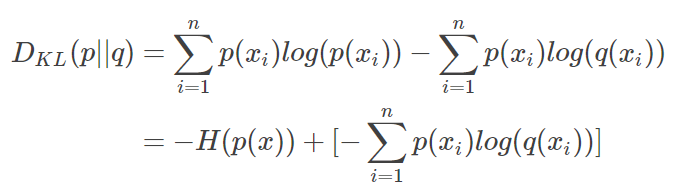
等式的前一部分是p的熵,后一部分是交叉熵:
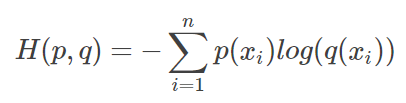
在机器学习中,我们需要评估label和predict之间的差距,使用KL散度刚刚好。由于KL散度的前一部分 -H(y)不变,故在优化过程中,只需要关注交叉熵就可以了,所以一般在机器学习中直接用交叉熵做loss,评估模型。因为交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小(相对熵的值越小),两个概率分布越接近。
1.5 交叉熵在单标签分类问题的使用
这里的单标签分类,就是深度学习最基本的分类问题,每个图像只有一个标签,只能是label1或者label2。
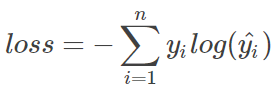
上图是一个样本loss的计算方式,n代表n种label,yi表示真实结果, yihat表示预测概率。如果是一个batch,则需要除以m(m为当前batch的样本数)。
1.6 交叉熵在多标签分类问题的使用
这里的多标签分类是指,每一张图像样本可以有多个类别,多分类标签是n-hot,值得注意的是,这里的pred不再用softmax计算了,采用的是Sigmoid了。将每一个节点的输出归一化到0-1之间。所以pred的值的和也不再是1。比如我们的语义分割,每个像素的label都是独立分布的,相互之间没有任何影响,所以交叉熵在这里是单独对每一个节点进行计算,每一个节点只有两种可能性,所以是一个二项分布。(上面有简化后交叉熵的公式)
每个样本的loss即为 loss = loss1 + loss2 + ... lossn。
每一个batch的loss就是:
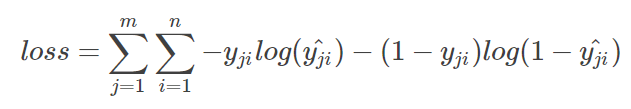
其中m为当前batch的样本量,n为类别数。
2,Pytorch中CrossEntropy的形式
语义分割的本质是对像素的分类。因此语义分割也是使用这个损失函数。首先看代码定义:
def cross_entropy(input, target, weight=None, size_average=None, ignore_index=-100,
reduce=None, reduction='mean'):
# type: (Tensor, Tensor, Optional[Tensor], Optional[bool], int, Optional[bool], str) -> Tensor if size_average is not None or reduce is not None:
reduction = _Reduction.legacy_get_string(size_average, reduce)
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
从上面代码可知:input和target是Tensor格式,并且先计算log_softmax,再计算nll_loss。(实际上softmax计算+ log计算 + nll_loss 计算== 直接使用CrossEntropyLoss计算)
2.1 通过softmax+log+nll_loss 计算CrossEntropyLoss
我们直接在语义分割中应用:
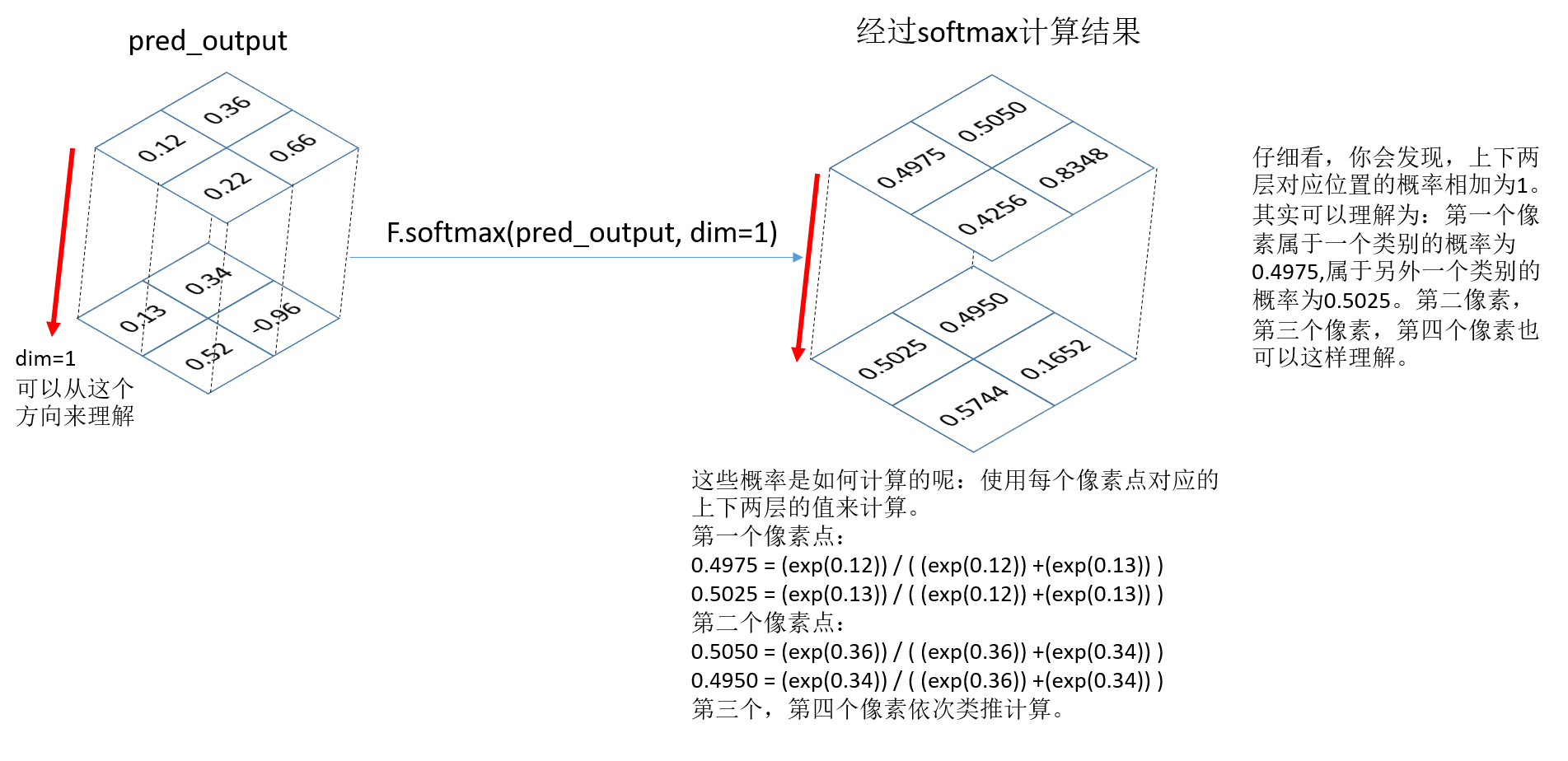
下面softmax函数肯定输出的是网络的输出预测图像,假设维度为(1,2,2,2),从左到右dim依次为0,1,2,3,也就是说类别数所在的维度表示dim=1应在的维度上计算概率。所以dim=1
temp1 = F.softmax(pred_output,dim=1)
print("temp1:",temp1)
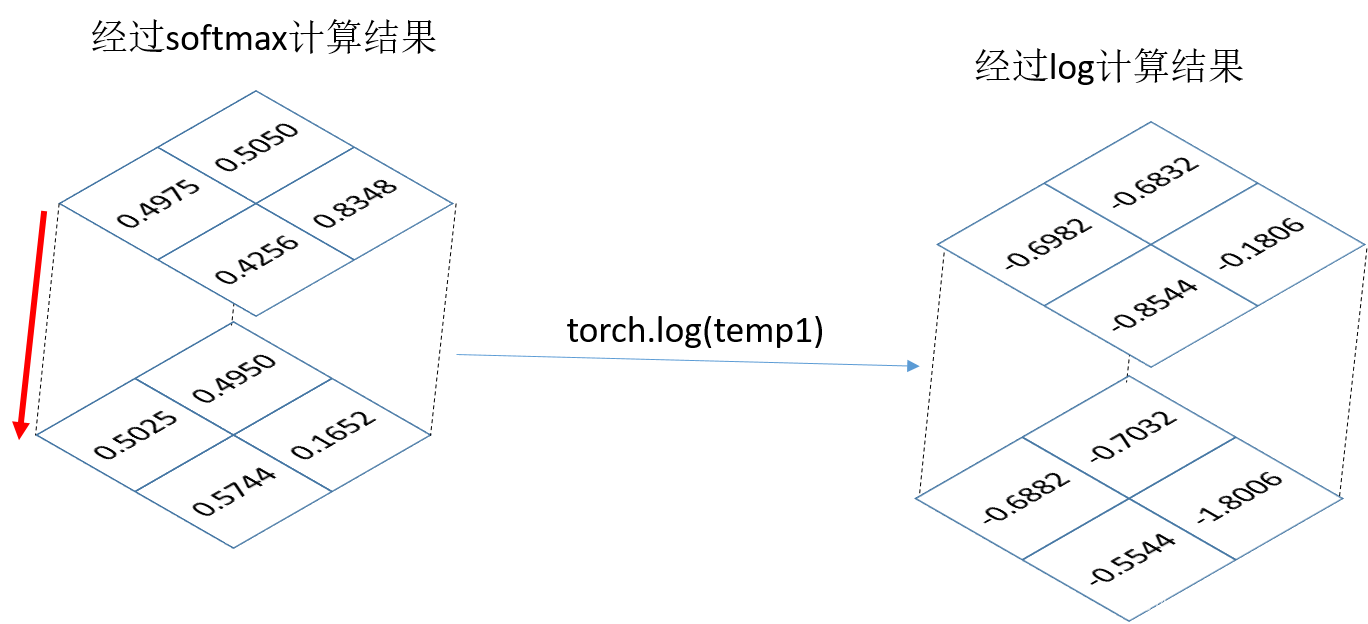
log函数:就是对输入矩阵的每个元素求对数,默认底数为e,也就是In函数
temp3 = torch.log(temp1)
print("temp3:",temp3)
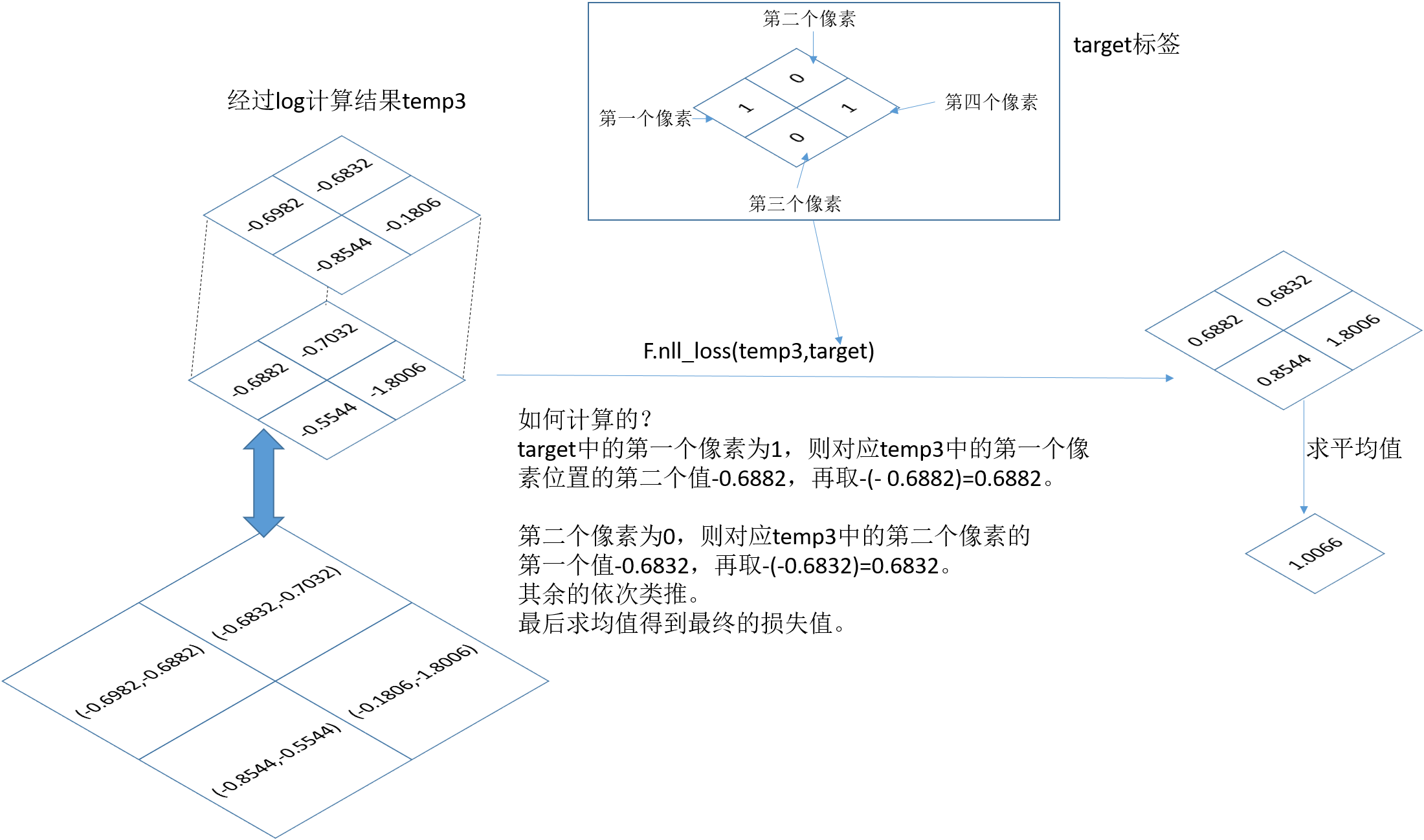
nll_loss函数:这个函数的目的是把标签图像的元素值,作为索引值,在上面选择相应的值求平均。
target = target.long()
loss1 = F.nll_loss(temp3,target)
print('loss1: ', loss1)
2.2 直接使用交叉熵损失计算
直接使用交叉熵损失计算:
loss2 = nn.CrossEntropyLoss()
result2 = loss2(pred_output, target)
print('result2: ', result2)
对比结果可以发现 通过 对CrossEntropyLoss函数分解并分步计算的结果,与直接使用CrossEntropyLoss函数计算的结果一致。
2.3 pytorch 和 tensorflow在损失函数计算方面的差异
pytorch和tensorflow在损失函数计算方面有细微的差别的,为啥对比pytorch和tensorflow的差异,因为一个更符合人的想法,一个稍微有一些阉割的问题,导致我们按照常理写代码,会遇到问题。
tensorflow的模型训练:
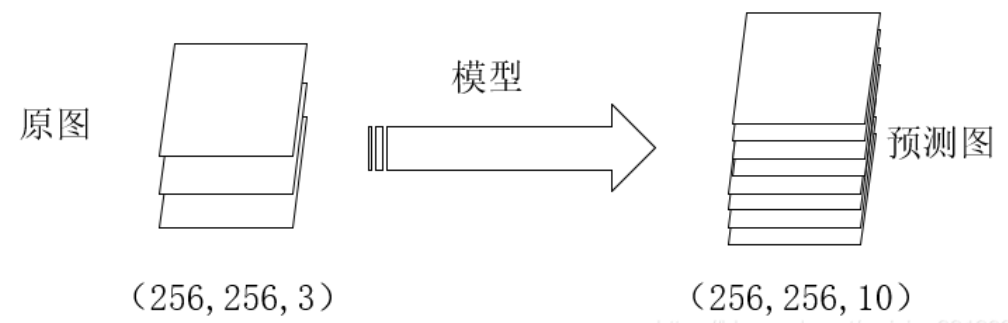
one-hot编码:
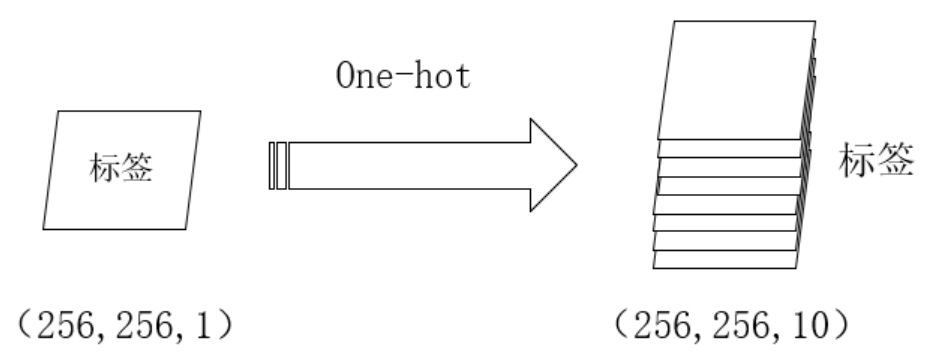
通过这两步骤,我们就可以计算标签和模型产生的预测结果之间的损失了。而在pytorch中,我们不需要对标签进行one-hot编码,且需要将通道这一维度压缩。即标签中的值为对应的类别数。
具体在代码中,如果是一个类别,就特别要注意(因为我就是没注意,所以就有开头的错):
masks_pred = model(images)
if model.n_classes == 1:
loss = criterion(masks_pred.squeeze(1), true_masks.float())
loss += dice_loss(F.sigmoid(masks_pred.squeeze(1)), true_masks.float(), multiclass=False)
else:
loss = criterion(masks_pred, true_masks)
loss += dice_loss(
F.softmax(masks_pred, dim=1).float(),
F.one_hot(true_masks, model.n_classes).permute(0, 3, 1, 2).float(),
multiclass=True
)
3,Pytorch中,nn与nn.functional的相同点和不同点
3.1 相同点
首先两者的功能相同,nn.xx与nn.functional.xx的实际功能是相同的,只是一个是包装好的类,一个是可以直接调用的函数。
比如我们这里学习的Crossentropy函数:
在torch.nn中定义如下:
class CrossEntropyLoss(_WeightedLoss):
__constants__ = ['ignore_index', 'reduction', 'label_smoothing']
ignore_index: int
label_smoothing: float def __init__(self, weight: Optional[Tensor] = None, size_average=None, ignore_index: int = -100,
reduce=None, reduction: str = 'mean', label_smoothing: float = 0.0) -> None:
super(CrossEntropyLoss, self).__init__(weight, size_average, reduce, reduction)
self.ignore_index = ignore_index
self.label_smoothing = label_smoothing def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.cross_entropy(input, target, weight=self.weight,
ignore_index=self.ignore_index, reduction=self.reduction,
label_smoothing=self.label_smoothing)
在torch.nn.functional中定义如下:
def cross_entropy(
input: Tensor,
target: Tensor,
weight: Optional[Tensor] = None,
size_average: Optional[bool] = None,
ignore_index: int = -100,
reduce: Optional[bool] = None,
reduction: str = "mean",
label_smoothing: float = 0.0,
) -> Tensor:
if has_torch_function_variadic(input, target, weight):
return handle_torch_function(
cross_entropy,
(input, target, weight),
input,
target,
weight=weight,
size_average=size_average,
ignore_index=ignore_index,
reduce=reduce,
reduction=reduction,
label_smoothing=label_smoothing,
)
if size_average is not None or reduce is not None:
reduction = _Reduction.legacy_get_string(size_average, reduce)
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
可以看到torch.nn下面的CrossEntropyLoss类在forward时调用了nn.functional下的cross_entropy函数,当然最终的计算是通过C++编写的函数计算的。
3.2 不同点
不同点1:在使用nn.CrossEntropyLoss()之前,需要先实例化,再输入参数,以函数调用的方式调用实例化的对象并传入输入数据:
import torch.nn as nn loss = torch.nn.CrossEntropyLoss()
output = loss(x, y)
使用 F.cross_entropy()直接可以传入参数和输入数据,而且由于F.cross_entropy() 得到的是一个向量也就是对batch中每一个图像都会得到对应的交叉熵,所以计算出之后,会使用一个mean()函数,计算其总的交叉熵,再对其进行优化。
import torch.nn.functional as F loss = F.cross_entropy(input, target).mean()
不同点2:而且 nn.xxx 继承于nn.Module,能够很好的与nn.Sequential结合使用,而nn.functional.xxx 无法与nn.Sequential结合使用。举个例子:
layer = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Dropout(0.2)
)
不同点3:nn.xxx 不需要自己定义和管理weight;而nn.functional.xxx需要自己定义weight,每次调用的时候都需要手动传入weight,不利于代码复用。其实如果我们只保留了nn.functional下的函数的话,在训练或者使用时,我们就需要手动去维护weight, bias, stride 这些中间量的值;而如果只保留nn下的类的话,其实就牺牲了一部分灵活性,因为做一些简单的计算都需要创建一个类,这也与PyTorch的风格不符。
比如使用nn.xxx定义一个网络,如下:
import torch
import torch.nn as nn
import torch.nn.functional as F class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
以一个最简单的五层网络为例。需要维持状态的,主要是两个卷积和三个线性变换,所以在构造Module是,定义了两个Conv2d和三个nn.Linear对象,而在计算时,relu之类不需要保存状态的可以直接使用。
参考地址(这个只是个人笔记,不做商业):
https://blog.csdn.net/tsyccnh/article/details/79163834
https://www.zhihu.com/question/66782101
https://blog.csdn.net/weixin_39190382/article/details/114433884)
https://blog.csdn.net/Fcc_bd_stars/article/details/105158215
深度学习之PyTorch实战(5)——对CrossEntropyLoss损失函数的理解与学习的更多相关文章
- 深度学习之PyTorch实战(1)——基础学习及搭建环境
最近在学习PyTorch框架,买了一本<深度学习之PyTorch实战计算机视觉>,从学习开始,小编会整理学习笔记,并博客记录,希望自己好好学完这本书,最后能熟练应用此框架. PyTorch ...
- 参考《深度学习之PyTorch实战计算机视觉》PDF
计算机视觉.自然语言处理和语音识别是目前深度学习领域很热门的三大应用方向. 计算机视觉学习,推荐阅读<深度学习之PyTorch实战计算机视觉>.学到人工智能的基础概念及Python 编程技 ...
- 深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
上一篇博客先搭建了基础环境,并熟悉了基础知识,本节基于此,再进行深一步的学习. 接下来看看如何基于PyTorch深度学习框架用简单快捷的方式搭建出复杂的神经网络模型,同时让模型参数的优化方法趋于高效. ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 【新生学习】深度学习与 PyTorch 实战课程大纲
各位20级新同学好,我安排的课程没有教材,只有一些视频.论文和代码.大家可以看看大纲,感兴趣的同学参加即可.因为是第一次开课,大纲和进度会随时调整,同学们可以随时关注.初步计划每周两章,一个半月完成课 ...
- 对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码
PyTorch是一个基于Python的深度学习平台,该平台简单易用上手快,从计算机视觉.自然语言处理再到强化学习,PyTorch的功能强大,支持PyTorch的工具包有用于自然语言处理的Allen N ...
- 深度学习框架PyTorch一书的学习-第五章-常用工具模块
https://github.com/chenyuntc/pytorch-book/blob/v1.0/chapter5-常用工具/chapter5.ipynb 希望大家直接到上面的网址去查看代码,下 ...
- 人工智能深度学习框架MXNet实战:深度神经网络的交通标志识别训练
人工智能深度学习框架MXNet实战:深度神经网络的交通标志识别训练 MXNet 是一个轻量级.可移植.灵活的分布式深度学习框架,2017 年 1 月 23 日,该项目进入 Apache 基金会,成为 ...
- 【深度学习】Pytorch学习基础
目录 pytorch学习 numpy & Torch Variable 激励函数 回归 区分类型 快速搭建法 模型的保存与提取 批训练 加速神经网络训练 Optimizer优化器 CNN MN ...
- 《深度学习框架PyTorch:入门与实践》的Loss函数构建代码运行问题
在学习陈云的教程<深度学习框架PyTorch:入门与实践>的损失函数构建时代码如下: 可我运行如下代码: output = net(input) target = Variable(t.a ...
随机推荐
- React中的CSS模块
CSS模块 使用步骤: 1.新建一个XXX.moudle.css文件 2.在组件中引入css impor classes(变量) fro ...
- MySql 字符串时间转换
MySql中经常遇到字符串格式时间转换成时间类型的情况: SELECT STR_TO_DATE('Jul 20 2013 7:49:14:610AM','%b %d %Y %h:%i:%s:%f%p' ...
- mssql实现Split
create function Fun_Split( @SourceSql varchar ( 8000 ), @StrSeprate varchar ( 10 )) returns @temp ta ...
- centos7查看ip地址
centos7查看ip地址 1.centos7进入终端 安装的centos7虚拟机(无图形界面):输入账号密码进入centos7 2.命令行输入 ip addr 查看 ip地址
- [C#]接口Interface快速Demo
参考代码1: using System; namespace InterfaceDemo { /// <summary> /// 定义一个爬树接口 /// </summary> ...
- C/S 架构 和 B/S 架构
C/S架构的理解: 官方称:clinet-server 客户端需要下载的软件: 今日头条,爱奇艺等 能在手机和浏览器打开的软件 B/S架构的理解: 官方称:web-server 客户端为浏览器的: ...
- c语言数据结构 树的基本操作
树的基本操作有创建,插入,删除,以及各种遍历的应用,如:利用后序遍历求高度,利用前序遍历求层数的结点 基本算法思路:创建二叉树函数参数必须接受二级指针!如果使用同级指针,无法返回创建后的结果,利用递归 ...
- ffmpeg均匀分割视频命令
ffmpeg -y -i input.wav -f segment -segment_time 5 output-%d.wav -segment_time 分割视频片段大小 -segmenet_lis ...
- mysql替换空格制表符换行
update ztbdb_pro set pro=REPLACE(pro,CHAR(10),''); update ztbdb_pro set pro=REPLACE(pro,CHAR(13),'') ...
- 【Leetcode】 剑指offer:栈与队列 --Day01
写在前面 2023届秋招形势严峻,作为2024届本科生倍感压力.时间紧迫,需要加快脚步. 计划之一是在未来的36天时间里通关Leetcode的剑指offer系列算法题.这一系列的学习周期为31天,也就 ...