记录NLTK安装使用全过程--python
前言
之前做实验用到了情感分析,就下载了一下,这篇博客记录使用过程。
下载安装到实战详细步骤
NLTK下载安装
先使用pip install nltk 安装包
然后运行下面两行代码会弹出如图得GUI界面,注意下载位置,然后点击下载全部下载了大概3.5G。
import nltk
nltk.download()!
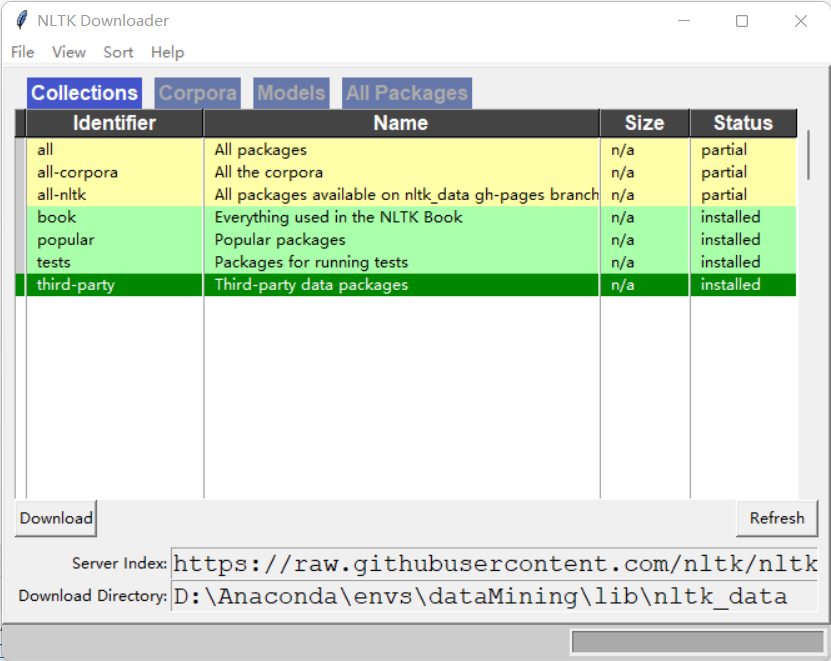
- 注意点:可能由于网络原因访问github卡顿导致,不能正常弹出GUI进行下载,可以自己去github下载
网址:https://github.com/nltk/nltk_data/tree/gh-pages/packages
下载成功后查看是否可以使用,运行下面代码看看是否可以调用brown中的词库
from nltk.corpus import brown
print(brown.categories()) # 输出brown语料库的类别
print(len(brown.sents())) # 输出brown语料库的句子数量
print(len(brown.words())) # 输出brown语料库的词数量
'''
结果为:
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies',
'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance',
'science_fiction']
57340
1161192
'''
这时候有可能报错,说在下面文件夹中没有找到nltk_data
把下载好的文件解压在复制到其中一个文件夹位置即可,注意文件名,让后就能正常使用!

实战:运用自己的数据进行操作
一、使用自己的训练集训练和分析
可以看到我的训练集和代码的结构是这样的: pos和neg里面是txt文本
pos和neg里面是txt文本
链接:https://pan.baidu.com/s/1GrNg3ziWJGhcQIWBCr2PMg
提取码:1fb8
import nltk.classify.util
from nltk.classify import NaiveBayesClassifier
import os
from nltk.corpus import stopwords
import pandas as pd
def extract_features(word_list):
return dict([(word, True) for word in word_list])
#停用词
stop = stopwords.words('english')
stop1 = ['!', ',' ,'.' ,'?' ,'-s' ,'-ly' ,' ', 's','...']
stop = stop1+stop
print(stop)
#读取txt文本
def readtxt(f,path):
data1 = ['microwave']
# 以 utf-8 的编码格式打开指定文件
f = open(path+f, encoding="utf-8")
# 输出读取到的数据
#data = f.read().split()
data = f.read().split()
for i in range(len(data)):
if data[i] not in stop:
data[i] = [data[i]]
data1 = data1+data[i]
# 关闭文件
f.close()
del data1[0]
return data1
if __name__ == '__main__':
# 加载积极与消极评论 这些评论去掉了一些停用词,是在readtxt韩硕里处理的,
#停用词如 i am you a this 等等在评论中是非常常见的,有可能对结果有影响,应该事先去除
positive_fileids = os.listdir('pos') # 积极 list类型 42条数据 每一条是一个txt文件
print(type(positive_fileids), len(positive_fileids)) # list类型 42条数据 每一条是一个txt文件
negative_fileids = os.listdir('neg')#消极 list类型 22条数据 每一条是一个txt文件自己找的一些数据
print(type(negative_fileids),len(negative_fileids))
# 将这些评论数据分成积极评论和消极评论
# movie_reviews.words(fileids=[f])表示每一个txt文本里面的内容,结果是单词的列表:['films', 'adapted', 'from', 'comic', 'books', 'have', ...]
# features_positive 结果为一个list
# 结果形如:[({'shakesp: True, 'limit': True, 'mouth': True, ..., 'such': True, 'prophetic': True}, 'Positive'), ..., ({...}, 'Positive'), ...]
path = 'pos/'
features_positive = [(extract_features(readtxt(f,path=path)), 'Positive') for f in positive_fileids]
path = 'neg/'
features_negative = [(extract_features(readtxt(f,path=path)), 'Negative') for f in negative_fileids]
# 分成训练数据集(80%)和测试数据集(20%)
threshold_factor = 0.8
threshold_positive = int(threshold_factor * len(features_positive)) # 800
threshold_negative = int(threshold_factor * len(features_negative)) # 800
# 提取特征 800个积极文本800个消极文本构成训练集 200+200构成测试文本
features_train = features_positive[:threshold_positive] + features_negative[:threshold_negative]
features_test = features_positive[threshold_positive:] + features_negative[threshold_negative:]
print("\n训练数据点的数量:", len(features_train))
print("测试数据点的数量:", len(features_test))
# 训练朴素贝叶斯分类器
classifier = NaiveBayesClassifier.train(features_train)
print("\n分类器的准确性:", nltk.classify.util.accuracy(classifier, features_test))
print("\n五大信息最丰富的单词:")
for item in classifier.most_informative_features()[:5]:
print(item[0])
# 输入一些简单的评论
input_reviews = [
"works well with proper preparation.",
]
#运行分类器,获得预测结果
print("\n预测:")
for review in input_reviews:
print("\n评论:", review)
probdist = classifier.prob_classify(extract_features(review.split()))
pred_sentiment = probdist.max()
# 打印输出
print("预测情绪:", pred_sentiment)
print("可能性:", round(probdist.prob(pred_sentiment), 2))
print("结束")
运行结果:这里的准确性有点高,这是因为我选取的一些数据是非常明显的表达积极和消极的所以处理结果比较难以相信
<class 'list'> 42
<class 'list'> 22
训练数据点的数量: 50
测试数据点的数量: 14
分类器的准确性: 1.0
五大信息最丰富的单词:
microwave
product
works
ever
service
预测:
评论: works well with proper preparation.
预测情绪: Positive
可能性: 0.77
结束
二、使用自带库分析
import pandas as pd
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# 分析句子的情感:情感分析是NLP最受欢迎的应用之一。情感分析是指确定一段给定的文本是积极还是消极的过程。
# 有一些场景中,我们还会将“中性“作为第三个选项。情感分析常用于发现人们对于一个特定主题的看法。
# 定义一个用于提取特征的函数
# 输入一段文本返回形如:{'It': True, 'movie': True, 'amazing': True, 'is': True, 'an': True}
# 返回类型是一个dict
if __name__ == '__main__':
# 输入一些简单的评论
#data = pd.read_excel('data3/microwave1.xlsx')
name = 'hair_dryer1'
data = pd.read_excel('../data3/'+name+'.xlsx')
input_reviews = data[u'review_body']
input_reviews = input_reviews.tolist()
input_reviews = [
"works well with proper preparation.",
"i hate that opening the door moves the microwave towards you and out of its place. thats my only complaint.",
"piece of junk. got two years of use and it died. customer service says too bad. whirlpool dishwasher died a few months ago. whirlpool is dead to me.",
"am very happy with this"
]
#运行分类器,获得预测结果
for sentence in input_reviews:
sid = SentimentIntensityAnalyzer()
ss = sid.polarity_scores(sentence)
print("句子:"+sentence)
for k in sorted(ss):
print('{0}: {1}, '.format(k, ss[k]), end='')
print()
print("结束")
结果:
句子:works well with proper preparation.
compound: 0.2732, neg: 0.0, neu: 0.656, pos: 0.344,
句子:i hate that opening the door moves the microwave towards you and out of its place. thats my only complaint.
compound: -0.7096, neg: 0.258, neu: 0.742, pos: 0.0,
句子:piece of junk. got two years of use and it died. customer service says too bad. whirlpool dishwasher died a few months ago. whirlpool is dead to me.
compound: -0.9432, neg: 0.395, neu: 0.605, pos: 0.0,
句子:am very happy with this
compound: 0.6115, neg: 0.0, neu: 0.5, pos: 0.5,
结束
结果解释:
compound就相当于一个综合评价,主要和消极和积极的可能性有关
neg:消极可能性
pos:积极可能性
neu:中性可能性
记录NLTK安装使用全过程--python的更多相关文章
- Ubuntu14.04 Django Mysql安装部署全过程
Ubuntu14.04 Django Mysql安装部署全过程 一.简要步骤.(阿里云Ubuntu14.04) Python安装 Django Mysql的安装与配置 记录一下我的部署过程,也方便 ...
- Ubuntu 14.04下Django+MySQL安装部署全过程
一.简要步骤.(Ubuntu14.04) Python安装 Django Mysql的安装与配置 记录一下我的部署过程,也方便一些有需要的童鞋,大神勿喷~ 二.Python的安装 由于博主使用的环境是 ...
- 基础知识:编程语言介绍、Python介绍、Python解释器安装、运行Python解释器的两种方式、变量、数据类型基本使用
2018年3月19日 今日学习内容: 1.编程语言的介绍 2.Python介绍 3.安装Python解释器(多版本共存) 4.运行Python解释器程序两种方式.(交互式与命令行式)(♥♥♥♥♥) 5 ...
- LinuxMint上安装redis和python遇到的一些问题
今天在安装Redis和Python上遇到了些问题,解决后记录下来. 环境:LinuxMint 18.3 安装redis sudo wget http://download.redis.io/relea ...
- window 安装gdal和python
进入 http://www.gisinternals.com/release.php 中下载下图(也可以不是这个版本但是下载的python和gdal一定要版本对应) 1.点击下图中release-17 ...
- 【转】Ubuntu 14.04下Django+MySQL安装部署全过程
一.简要步骤.(阿里云Ubuntu14.04) Python安装 Django Mysql的安装与配置 记录一下我的部署过程,也方便一些有需要的童鞋,大神勿喷~ 二.Python的安装 由于博主使用的 ...
- 编程语言、Python介绍及其解释器安装、运行Python解释器的两种方式、变量、内存管理
一.编程语言介绍 1.1 机器语言:直接用计算机能理解的二进制指令来编写程序,直接控制硬件. 1.2 汇编语言:在机器语言的基础上,用英文标签取代二进制指令来编写程序,本质上也是直接控制硬件. 以上2 ...
- 【python】pyenv与virtualenv安装,实现python多版本多项目管理
踩了很多坑,记录一下这次试验,本次测试环境:Linux centos7 64位. pyenv是一个python版本管理工具,它能够进行全局的python版本切换,也可以为单个项目提供对应的python ...
- Windows安装多个python解释器
Windows安装多个python解释器 在windows10系统下安装两个不同版本的的python解释器,在通常情况下编译执行文件都是没问题的,但是加载或下载包的时候pip的使用就会出现问题,无 ...
随机推荐
- figlet 一个在linux生成字符串图案的玩具
figlet官网 figlet官方字体库 figlet字体样例 安装方法 centos/redhat/fedora 发行版 yum install -y figlet debian/ubuntu 发行 ...
- php 利用 fsockopen GET/POST 提交表单及上传文件
1.GET get.php <?php$host = 'demo.fdipzone.com';$port = 80;$errno = '';$errstr = '';$timeout = 30; ...
- pytest(5)-断言
前言 断言是完整的测试用例中不可或缺的因素,用例只有加入断言,将实际结果与预期结果进行比对,才能判断它的通过与否. unittest 框架提供了其特有的断言方式,如:assertEqual.asser ...
- 【缓存】CPU高速缓存 之MESI 性协议 Gif 动画
CPU缓存架构 不同的CPU厂商的架构也有些不同,在这里只介绍流行的缓存架构 缓存一致性可以分为三个点: 在进程每个写入运算时都立刻采取措施保证资料一致性 每个独立的运算,假如它造成资料值的改变,所有 ...
- 【C# 锁】 SpinLock锁 详细分析(包括内部代码)
OverView 同步基元分为用户模式和内核模式 用户模式:Iterlocked.Exchange(互锁).SpinLocked(自旋锁).易变构造(volatile关键字.volatile类.Thr ...
- Visual Studio 的快捷不能用时候,我们只要选择重置就可以用了。
当发现Visual Studio 的快捷不能用时候,我们只要选择重置就可以用了.
- Debian 11 配置优化指南
原文地址: Debian 11 配置优化指南 - WindSpiritIT 0x00 简介 本文仅适用于配置 Debian 11 Bullseye 文中同时包含 Gnome 桌面和 KDE 桌面配置, ...
- JavaBean , EJB , spring , POJO
1996年 , 发布了java bean 1.00-A 当时的java bean有什么用呢 javaBean最初是为Java GUI的可视化编程实现的.你拖动IDE构建工具创建一个GUI 组件(如多 ...
- kubebuilder operator的运行逻辑
kubebuilder 的运行逻辑 概述 下面是kubebuilder 的架构图.可以看到最外层是通过名为Manager的组件驱动的,Manager中包含了多个组件,其中Cache中保存了gvk和in ...
- Qt:QTimer
1.说明 QTimer类代表计时器,为了正确使用计时器,可以构造一个QTimer,将它的timeout()信号connect到合适的槽,之后调用start().然后,这个QTimer就会每隔inter ...