【Hadoop】三句话告诉你 mapreduce 中MAP进程的数量怎么控制?
1、果断先上结论
看了很多博客,感觉没有一个说的很清楚,所以我来整理一下。
先看一下这个图
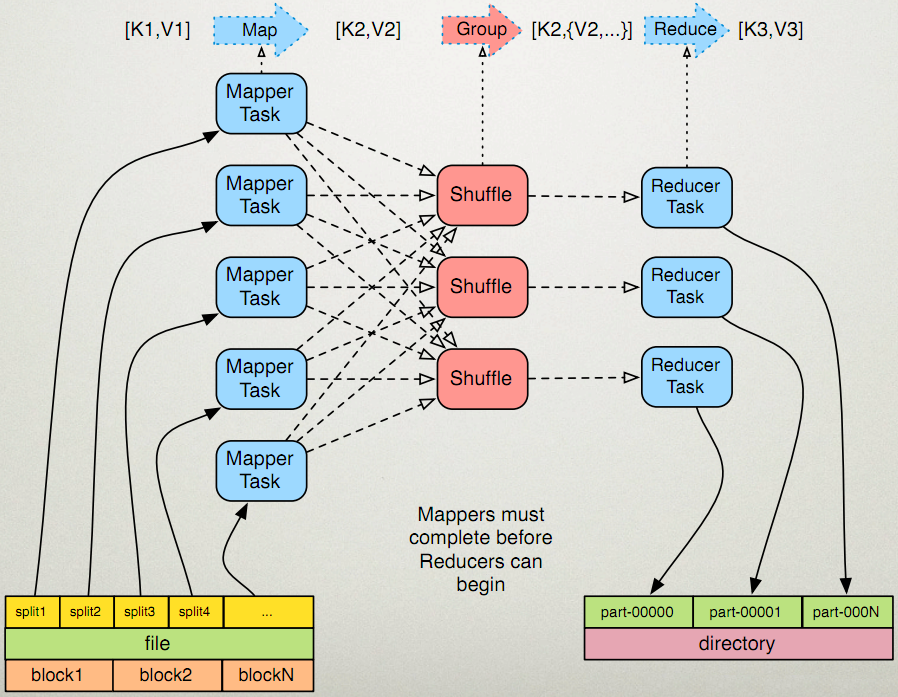
输入分片(Input Split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
Hadoop 2.x默认的block大小是128MB,Hadoop 1.x默认的block大小是64MB,可以在hdfs-site.xml中设置dfs.block.size,注意单位是byte。
分片大小范围可以在mapred-site.xml中设置,mapred.min.split.size mapred.max.split.size,minSplitSize大小默认为1B,maxSplitSize大小默认为Long.MAX_VALUE = 9223372036854775807
那么分片到底是多大呢?
minSize=max{minSplitSize,mapred.min.split.size}
maxSize=mapred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
我们再来看一下源码

所以在我们没有设置分片的范围的时候,分片大小是由block块大小决定的,和它的大小一样。比如把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成三个block块,与之对应产生三个split,所以最终会产生三个map task。我又发现了另一个问题,第三个block块里存的文件大小只有2MB,而它的block块大小是128MB,那它实际占用Linux file system的多大空间?
答案是实际的文件大小,而非一个块的大小。
有大神已经验证这个答案了:http://blog.csdn.net/samhacker/article/details/23089157
1、往hdfs里面添加新文件前,hadoop在linux上面所占的空间为 464 MB:

2、往hdfs里面添加大小为2673375 byte(大概2.5 MB)的文件:
2673375 derby.jar
3、此时,hadoop在linux上面所占的空间为 467 MB——增加了一个实际文件大小(2.5 MB)的空间,而非一个block size(128 MB):

4、使用hadoop dfs -stat查看文件信息:

这里就很清楚地反映出: 文件的实际大小(file size)是2673375 byte, 但它的block size是128 MB。
5、通过NameNode的web console来查看文件信息:

结果是一样的: 文件的实际大小(file size)是2673375 byte, 但它的block size是128 MB。
6、不过使用‘hadoop fsck’查看文件信息,看出了一些不一样的内容—— ‘1(avg.block size 2673375 B)’:

值得注意的是,结果中有一个 ‘1(avg.block size 2673375 B)’的字样。这里的 'block size' 并不是指平常说的文件块大小(Block Size)—— 后者是一个元数据的概念,相反它反映的是文件的实际大小(file size)。以下是Hadoop Community的专家给我的回复:
“The fsck is showing you an "average blocksize", not the block size metadata attribute of the file like stat shows. In this specific case, the average is just the length of your file, which is lesser than one whole block.”
最后一个问题是: 如果hdfs占用Linux file system的磁盘空间按实际文件大小算,那么这个”块大小“有必要存在吗?
其实块大小还是必要的,一个显而易见的作用就是当文件通过append操作不断增长的过程中,可以通过来block size决定何时split文件。以下是Hadoop Community的专家给我的回复:
“The block size is a meta attribute. If you append tothe file later, it still needs to know when to split further - so it keeps that value as a mere metadata it can use to advise itself on write boundaries.”
补充:我还查到这样一段话
原文地址:http://blog.csdn.net/lylcore/article/details/9136555
一个split的大小是由goalSize, minSize, blockSize这三个值决定的。computeSplitSize的逻辑是,先从goalSize和blockSize两个值中选出最小的那个(比如一般不设置map数,这时blockSize为当前文件的块size,而goalSize是文件大小除以用户设置的map数得到的,如果没设置的话,默认是1)。
【Hadoop】三句话告诉你 mapreduce 中MAP进程的数量怎么控制?的更多相关文章
- 三句话告诉你break、return、continue!
break:终止循环执行循环体下面的代码 return:终止循环并且退出循环所在的方法 continue:终止当前循环,进行下一次循环
- 三句话看明白jdk收费吗
对于从oracle下载的jdk8:JDK8u200(含)以下版本不收费. 对于从oracle下载的jdk11:JDK 11.0.0不收费,JDK 11.0.1不收费. 对于openjdk:免费 ——— ...
- 正确理解Widget::Widget(QWidget *parent) :QWidget(parent)这句话(初始化列表中无法直接初始化基类的数据成员,所以你需要在列表中指定基类的构造函数)
最近有点忙,先发一篇我公众号的文章,以下是原文. /********原文********/ 最近很多学习Qt的小伙伴在我的微信公众号私信我,该如何理解下面段代码的第二行QWidget(parent) ...
- 【干货!!】三句话搞懂 Redis 缓存穿透、击穿、雪崩
前言 如何有效的理解并且区分 Reids 穿透.击穿和雪崩之间的区别,一直以来都挺困扰我的.特别是穿透和击穿,过一段时间就稀里糊涂的分不清了. 为了有效的帮助笔者自己,以及拥有同样烦恼的朋友们区分这三 ...
- UESTC - 1172 三句话题意
题目链接 记一个集合的gcd为该集合内所有数的最大公约数, 求一个给定集合的非空子集的gcd的k次方的期望~ Input 第一行有一个数t,表示数据组数 接下去每组数据两行,第一行两个数n,k(0 & ...
- iOS三句话实现文本转语音:AVSpeechSynthesizer
一.介绍 从iOS5开始,iOS系统已经在siri上集成了语音合成的功能,但是是私有API.但是在iOS7,新增了一个简单的API----AVSpeechSynthesizer来做这件事情. 二.案例 ...
- 几句话说明 .NET MVC中ViewData, ViewBag和TempData的区别
ViewData和TempData是字典类型,赋值方式用字典方式, ViewData["myName"] ViewBag是动态类型,使用时直接添加属性赋值即可 ViewBag.my ...
- 三句话搞定FireDAC连接池
form上拖入: FDManager1: TFDManager; FDConnection1: TFDConnection; //初始化连接池procedure TForm1.InitDBPool;b ...
- MapReduce中map并行度优化及源码分析
mapTask并行度的决定机制 一个job的map阶段并行度由客户端在提交job时决定,而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分 ...
随机推荐
- TensorFlow 模型文件
在这篇 TensorFlow 教程中,我们将学习如下内容: TensorFlow 模型文件是怎么样的? 如何保存一个 TensorFlow 模型? 如何恢复一个 TensorFlow 模型? 如何使用 ...
- Hash表模板
namespace Hash { ; ; struct adj { ll nxt,v,num,val; }e[N]; ll head[H],ecnt=; void init() { ecnt=; me ...
- BZOJ2875 [Noi2012]随机数生成器 【矩阵乘法 + 快速乘】
题目 栋栋最近迷上了随机算法,而随机数是生成随机算法的基础.栋栋准备使用线性同余法(Linear Congruential Me thod)来生成一个随机数列,这种方法需要设置四个非负整数参数m,a, ...
- 用CSS模拟魔兽世界技能冷却的效果
效果演示 上面的效果看起来还不错吧.在网页里,除了用Flash,我们还是有不少方法可以实现它. 显然这种效果不复杂,一张背景图片,加上前面带有透明度的多边形图层,在脚本控制下就可以转起来了.但问题 ...
- Tomcat学习笔记(六)
Tomcat日志 网上找到一篇分析不错的博文 http://peiquan.blog.51cto.com/7518552/1580189/
- 石子归并的三种打开方式——难度递增———51Node
1021 石子归并 N堆石子摆成一条线.现要将石子有次序地合并成一堆.规定每次只能选相邻的2堆石子合并成新的一堆,并将新的一堆石子数记为该次合并的代价.计算将N堆石子合并成一堆的最小代价. ...
- 用Java画QRCode二维码
支付宝.微信扫码支付的二维码,第三方的类库QRCode.jar 还是很好用的.下面贴出来这个东东生成二维码的代码. 使用时注意包括图片地址.编码内容.图片属性等几个参数,支付宝的它们的扫码回调地址. ...
- 我们曾经心碎的数据库之 用SQL语句操作数据
第八章 用SQL语句操作数据 1.SQL简介 SQL语言是能够识别指令,执行相应的操作并为程序提供数据的一套指令集 SQL的全称: 结构化查询语言(Structured Query Languag ...
- 今天做一个winform,想直接把窗体改成输出类库,其他地方直接调结果总提示不能注册组件,回来调度,可以,总结,windows还是直接用新建的类型项目,改容易出错
如题, 对于winform程序,还是新建一个类库,这样,在类库里面可以添加窗体.这样可以提供其他程序集来调用里面的窗体
- 调用SMTP发送有附件的邮件
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...