Hive高级
HiveServer2
- 概述:
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Overview2
- 客户端:
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
Hive数据压缩
- 压缩格式: bzip2, gzip, lzo, snappy等
- 压缩比:bzip2>gzip>lzo bzip2最节省存储空间
- 解压速度:lzo>gzip>bzip2 lzo解压速度是最快的
在实际的项目开发当中,hive表的数据:
* 存储格式
orcfile / qarquet
* 数据压缩
snappy
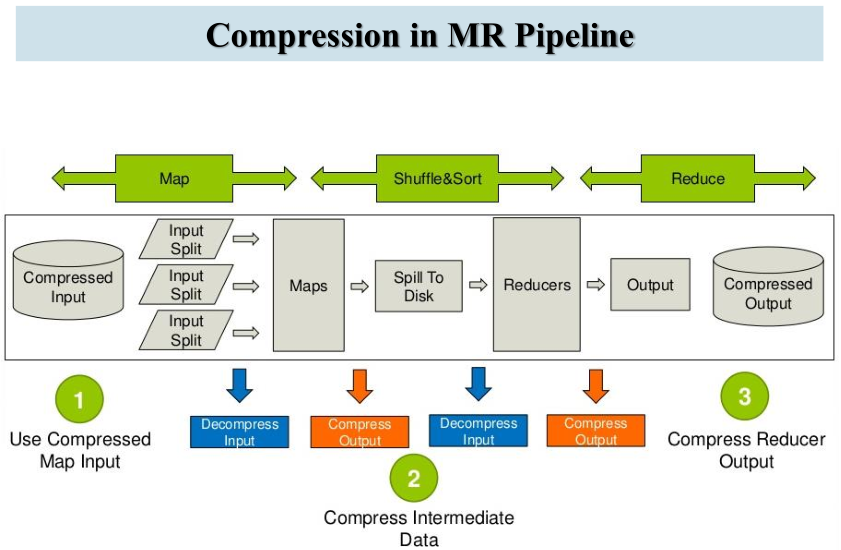
Hive数据存储
Hive supports several file formats:
Text File
SequenceFile
RCFile
Avro Files
ORC Files
Parquet
Custom INPUTFORMAT and OUTPUTFORMAT
- https://cwiki.apache.org/confluence/display/Hive/FileFormats
- https://cwiki.apache.org/confluence/display/Hive/SerDe
Hive优化
- EXPLAIN语法
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain





Hive高级的更多相关文章
- 大数据技术之_08_Hive学习_04_压缩和存储(Hive高级)+ 企业级调优(Hive优化)
第8章 压缩和存储(Hive高级)8.1 Hadoop源码编译支持Snappy压缩8.1.1 资源准备8.1.2 jar包安装8.1.3 编译源码8.2 Hadoop压缩配置8.2.1 MR支持的压缩 ...
- 第3节 hive高级用法:16、17、18
第3节 hive高级用法:16.hive当中常用的几种数据存储格式对比:17.存储方式与压缩格式相结合:18.总结 hive当中的数据存储格式: 行式存储:textFile sequenceFile ...
- hive高级数据类型
hive的高级数据类型主要包括:数组类型.map类型.结构体类型.集合类型,以下将分别详细介绍. 1)数组类型 array_type:array<data_type> -- 建表语句 cr ...
- Hive高级聚合GROUPING SETS,ROLLUP以及CUBE
scala> import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.sql.hive.HiveContext s ...
- 第3节 hive高级用法:15、hive的数据存储格式介绍
hive当中的数据存储格式: 行式存储:textFile sequenceFile 都是行式存储 列式存储:orc parquet 可以使我们的数据压缩的更小,压缩的更快 数据查询的时候尽量不要用se ...
- 第3节 hive高级用法:14、hive的数据压缩
六.hive的数据压缩 在实际工作当中,hive当中处理的数据,一般都需要经过压缩,前期我们在学习hadoop的时候,已经配置过hadoop的压缩,我们这里的hive也是一样的可以使用压缩来节省我们的 ...
- 第3节 hive高级用法:13、hive的函数
4.2.Hive参数配置方式 Hive参数大全: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties 开 ...
- hadoop之hive高级操作
在输出结果较多,需要输出到文件中时,可以在hive CLI之外执行hive -e "sql" > output.txt操作 但当SQL语句太长或太多时,这种方式不是很方便,可 ...
- 【HIVE高级笔试必备题型】(组内topN、相邻行的值比较问题)求语文大于数学_/_求文科大于理科成绩的学生
Hive SQL练习之成绩分析 数据:[id, 学号,班级,科目,成绩] 1,1,1,yuwen,80 2,1,1,shuxue,85 3,2,1,yuwen,75 4,2,1,shuxue,70 5 ...
随机推荐
- python调用top命令获得CPU利用率
1.python调用top命令获得CPU利用率 思路:通过python调用top命令获取cpu使用率 #python2代码 [root@zdops-server script]# cat cpu_lo ...
- 【AS3 Coder】任务五:Flash 2D游戏的第二春(中)
在上一节中,我们介绍了如何构建我们小小的90度角RPG游戏的背景,在这一节中我将为列位带来重头戏部分,隆重介绍我们的主角及NPC登场,噔噔噔噔……掌声在哪里?! 额,没听到掌声,罢了,直接开场吧. 本 ...
- JRebel 7.0.10 for intellij IDEA 2017.1
1什么是JRebel? JRebel是一套JavaEE开发工具.JRebel是一款JAVA虚拟机插件,它使得JAVA程序员能在不进行重部署的情况下,即时看到代码的改变对一个应用程序带来的影响.JReb ...
- vue笔记二
七.列表渲染 1.示例 <ul id="example-2"> <li v-for="(item, index) in items"> ...
- mysql kill process解决死锁
mysql使用myisam的时候锁表比较多,尤其有慢查询的时候,造成死锁.这时需要手动kill掉locked的process.使他释放. (以前我都是重起服务)..惭愧啊.. 演示:(id 7是我用p ...
- TCP/IP详解 卷一(第十一章 UDP:用户数据报协议)
UDP是一个简单的面向数据报的运输层协议. UDP不提供可靠性:它把应用程序传给IP层的数据发送出去,但是并不保证它们能到达目的地. UDP首部的个字段如下图所示
- (三)storm-kafka源代码走读之怎样构建一个KafkaSpout
上一节介绍了config的相关信息,这一节说下,这些參数各自是什么.在zookeeper中的存放路径是如何的,之前QQ群里有非常多不知道该怎么传入正确的參数来new 一个kafkaSpout,其主要还 ...
- 把数据库里面的stu表中的数据,导出到excel中
# 2.写代码实现,把我的数据库里面的stu表中的数据,导出到excel中 #编号 名字 性别 # 需求分析:# 1.连接好数据库,写好SQL,查到数据 [[1,'name1','男'],[1,'na ...
- 阿里巴巴 DevOps 转型后的运维平台建设
原文:http://www.sohu.com/a/156724220_262549 本文转载自公众号「DevOps 时代」,高效运维社区致力于陪伴您的职业生涯,与您一起愉快的成长. 作者简介: 陈喻( ...
- Android实用工具
1 json类:hiJson 格式化json字符串 2 sqlite类:sqlitespy,SQLiteExpertSetup 3