MapReduce 详解
MapReduce的整个运行分为两个阶段: Map和Reduce
Map阶段由一定数量的Map Task组成
输入格式的数据格式化:InputFormat
数日数据的处理:Mapper
数据分组:Partitioner
下面流程图:
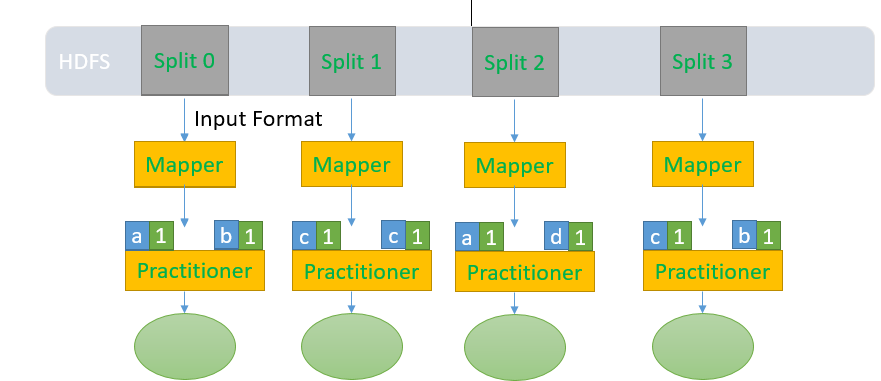
1. Map task 首先从HDFS上Read文件,通过Input Format把分件切分成一个一个的split.生成<Key,Value> key默认用行在文件中的偏移量
2.对每一个split块执行Map操作
3.
4. Maper的<Key,Value>输出到Reducer段
Redue阶段由一定数量的Reduce Task 组成
数据的远程COPY
数据按Key排序
数据处理:Reducer
数据输出格式: OutputFormat
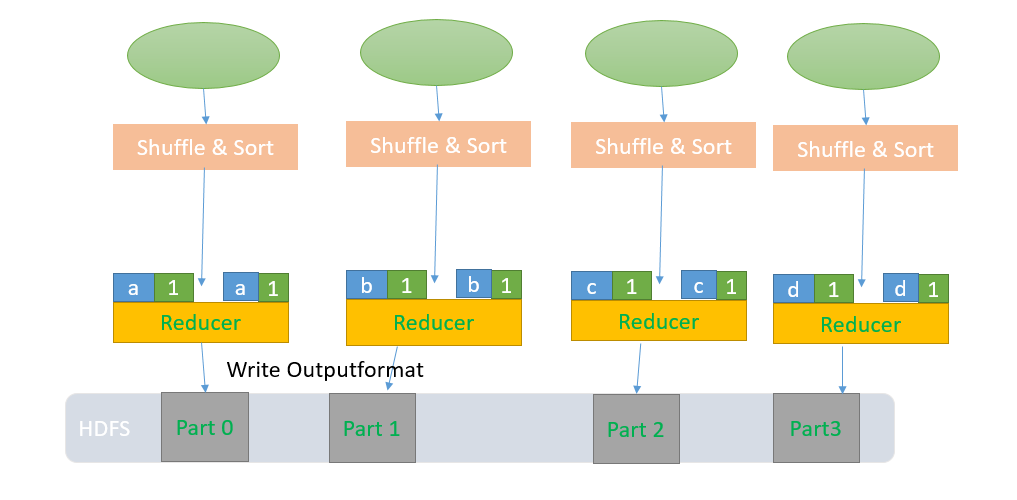
1. 拿到Mapper的ouput作为Input
2. 把patitiioner的结果远程copy到本地
3. Shffle & Sort操作。
4. Reducer操作
5.输出
MapReduce 详解的更多相关文章
- hadoop之mapreduce详解(进阶篇)
上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述. 一.mapreduce ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
- 大数据入门第七天——MapReduce详解(一)入门与简单示例
一.概述 1.map-reduce是什么 Hadoop MapReduce is a software framework for easily writing applications which ...
- hadoop之mapreduce详解(基础篇)
本篇文章主要从mapreduce运行作业的过程,shuffle,以及mapreduce作业失败的容错几个方面进行详解. 一.mapreduce作业运行过程 1.1.mapreduce介绍 MapRed ...
- hadoop之mapreduce详解(优化篇)
一.概述 优化前我们需要知道hadoop适合干什么活,适合什么场景,在工作中,我们要知道业务是怎样的,能才结合平台资源达到最有优化.除了这些我们当然还要知道mapreduce的执行过程,比如从文件的读 ...
- MapReduce:详解Shuffle过程(转)
/** * author : 冶秀刚 * mail : dennyy99@gmail.com */ Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapRedu ...
- MapReduce:详解Shuffle过程
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapReduce, Shuffle是必须要了解的.我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑, ...
- MapReduce详解
1.mapreduce之shuffle http://blog.csdn.net/thomas0yang/article/details/8562910 2.彻底了解mapreduce核心Shuffl ...
- [转]MapReduce:详解Shuffle过程
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapReduce, Shuffle是必须要了解的.我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑, ...
- Hadoop生态集群MapReduce详解
一.概述 MapReduce是一种编程模型,这点很重要,仅仅是一种编程的模型,而不是具体的软件.在hadoop中,HDFS是分布式的文件存储系统,而MapReduce是一个分布式的计算框架.用于大规模 ...
随机推荐
- php单引号双引号的区别
单引号里面的内容是直接被当做一个字符串,用双引号定义的字符串的内容最只要的特征就是会被解析.
- linux鸟哥的私房菜
这书还是感觉非常棒,真的是授之以渔而不是授之以鱼.我觉得只需要掌握一个命令就可以了man -k KEYWORD 比如我想查找和防火墙相关的命令,那么 man -k firewall 结果是ufw 然后 ...
- cf123E Maze
传送门 分析 见ptx大爷的博客 代码 #include<iostream> #include<cstdio> #include<cstring> #include ...
- 914D Bash and a Tough Math Puzzle
传送门 分析 用线段树维护区间gcd,每次查询找到第一个不是x倍数的点,如果这之后还有gcd不能被x整除的区间则这个区间不合法 代码 #include<iostream> #include ...
- zookeeper集群安装(转)
转载地址:http://www.blogjava.net/hello-yun/archive/2012/05/03/377250.html 本方法,本人亲自试验,可以成功. ZooKeeper是一个分 ...
- Entity Framework Tutorial Basics(3):Entity Framework Architecture
Entity Framework Architecture The following figure shows the overall architecture of the Entity Fram ...
- LeetCode第35题:搜索插入位置
题目描述: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引.如果目标值不存在于数组中,返回它将会被按顺序插入的位置. 你可以假设数组中无重复元素. 示例 1: 输入: [1,3,5,6 ...
- 《the art of software testing》 (1-2)章
软件测试的心理学,重点是要认清: 测试时为发现错误而执行程序的过程 成功的测试:如果在测试某段程序时发现了错误,而且这些错误是可以修复的,就将这次合理设计并得到有效执行的测试称作是"成功的& ...
- C++笔记--名字空间和异常
名字空间 成员函数可以在名字空间的定义里去声明,然后再去采用一种定义方式例如:namespace__name::member_name的方式去定义这个成员函数 namespace parser{ do ...
- javascript table排序之jquery.tablesorter.js
table排序 jquery.tablesorter.js 一.Demo下载地址: 1.tablesorter.js下载地址: http://download.csdn.net/detail/zhan ...