#学习笔记# VALSE 2019.01.09 朱俊彦 --- Learning to Synthesize Images, Videos, and 3D Objects
视频类型:VALSE-webinar
报告时间:2019年01月09日
报告人:MIT朱俊彦
报告题目:Learning to Synthesize Images, Videos, and 3D Objects
报告网址:http://valser.org/article-298-1.html
视频地址:http://www.iqiyi.com/w_19s78pzlsx.html#vfrm=8-8-0-1
Part 1 : image generation
给定一个输入图像x,学习一个生成器G,使输出图像尽可能与真实图像y相似。
该问题面临三个挑战:
- How to design an objective L?
- How to optimize L?
- How to collect data (x, y)?
解决篇
1. How to design an objective L?
pix2pix,可以自动设计损失函数。
不仅要生成高清的图像,还要生成的图像和输入相匹配。
pix2pix提供了一个可学习的损失函数,受到GAN的启发,但也用到了输入图像。
2. How to optimize L?
pix2pixHD, Large-scale optimization。
使用到传统思想 Image Pyramid [Burt and Adelson 1987],即coarse-to-fine。先生成低分辨率的图像,然后增强细节,直到生成高分辨率的图像。
好处:(1)smooth energy landscape 。处理低分辨率图像时,图像的起伏landscape会平缓很多。
(2)reduce the number of parameters。参数数量减少,训练速度加快。
实现:
(1)训练一个模型生成低分辨率图像,pix2pix实现
(2)用低分辨率的输出图像和高分辨率的输入图像结合,生成高分辨率图像。具体如图或参考原文。

3. How to collect data (x, y)?
CycleGAN, learning without pairs. 不用成对的数据,学习两个域间的映射。
First reference: Mark Twain提出,在语言翻译中(如,英语翻译到法语再到英语),即使一个人不懂法语,也可以检查翻译的质量,通过“back translation”,看翻译回来的句子和最初的句子是否一致。
由以上启发提出cycle-consistency loss,解决了mode-collapse问题,从一张马的图像x出发,通过正向映射G,得到输出G(x),同时使用对抗损失来判别输出斑马的真假,同时学习反向的映射F,把斑马再变回马,测量重建的马和原始的马之间的差距。这就解决了mode-collapse的问题。
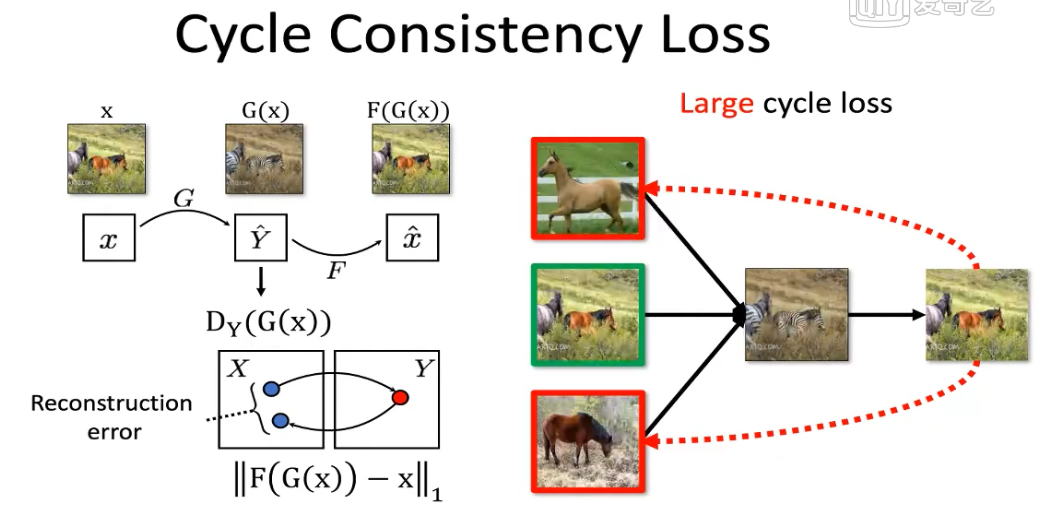
但是CycleGAN不会永远成功。斑马人的例子,是由于训练数据集中只有野马的图像,没包括马上的骑手,所以在测试阶段对新物体并不有效。
Part 2 : Understanding Black-box Networks
问题:如何理解这样一个黑盒子网络?如果出现问题,该如何调试?
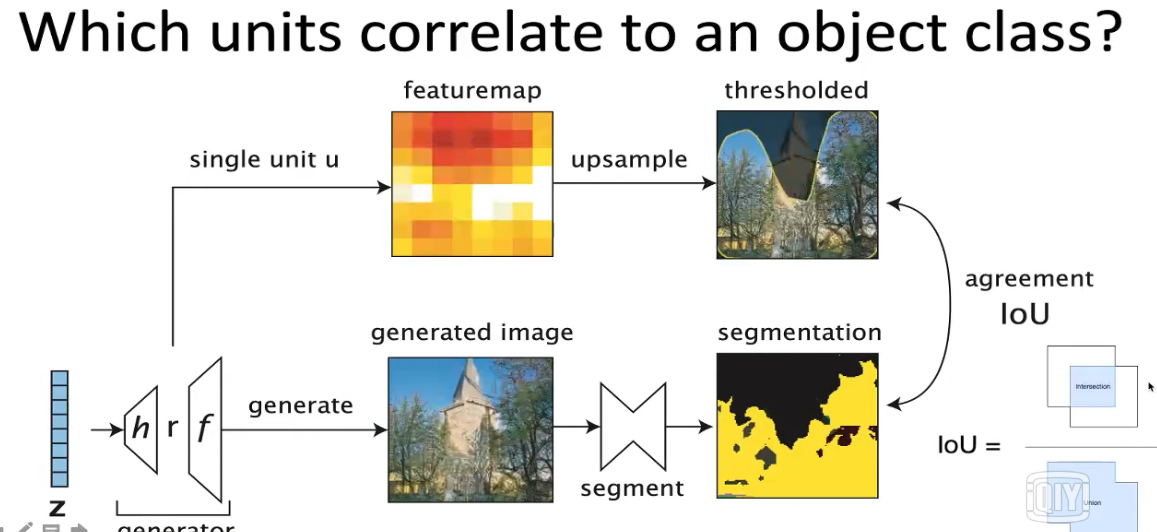
GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
通过训练集,训练出决定某个物体的units,可以控制这个units来控制图像中某物体(如树)的有无或数量,实现对图像中物体的增减。也可以找出决定瑕疵的单元,去除这个单元就能达到去瑕疵的效果。(具体内容和原理见论文,暂时看不懂原理)
Part 3 : 2D-->3D
为了使GAN能够支持视频生成、游戏体验、虚拟现实等场景,我们需要从2D出发,向3D扩展,甚至4D,5D,即包括相机视角、时间戳以及三维空间坐标的五维空间。即vid2vid
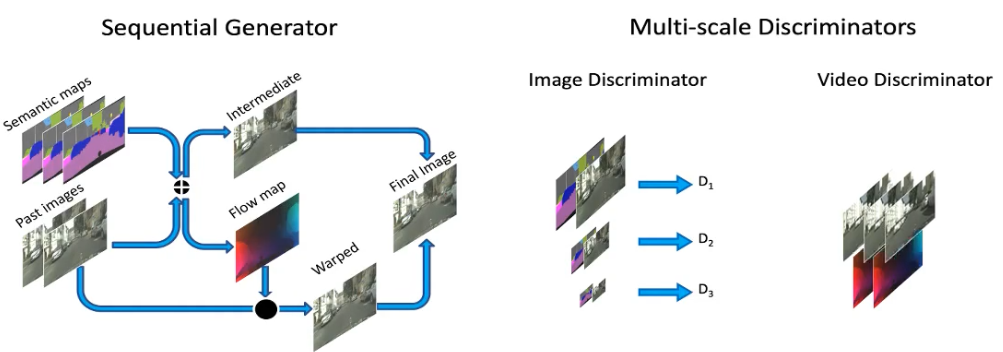
#sequential generator#
给定输入语义标签图,我们要生成对应的输出视频,一种方法就是直接用pix2pixHD逐帧生成,但是结果看上去并不好,帧与帧之间有大量的闪烁,因此在英伟达赞助下,我们提出了一种方法。基本思路是使用基于图像扭转(warpping-based)的方法,生成当前帧到下一帧的光流,以及一些细节,再通过基于光流的方法,将两部分融合在一起。网络需要学习光流信息,才能合成下一帧。其中的关键在于,前面生成的帧还可以重复使用,只需要增添一些新的细节即可。每生成一帧后,便将其加入之前的帧序列中,送进网络中。这有点像循环神经网络。
#multi-scale discriminators#
我们还考察了不同的判别器,引入了空间多尺度和时间多尺度,比如时域上我们观察两帧,四帧到八帧的时间尺度,以保持长期的时域一致性。
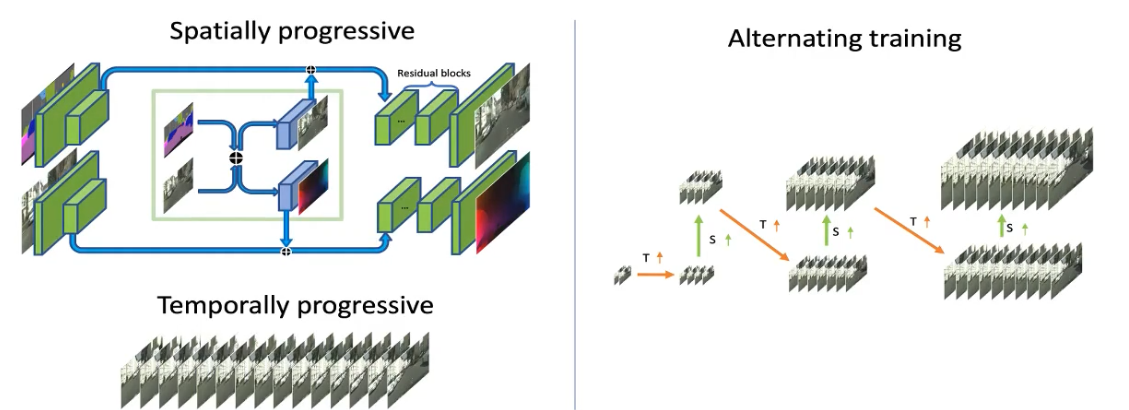
#progressive training#
同时在训练时,采用增量递进(progressive growing)的策略,先从合成低分辨率图像开始,然后增大分辨率。对时域也同样处理,先生成连续两帧,然后再到四帧,再训练模型生成八帧,直到最后一次生成十六帧。
#alternative training#
空域和时域的增长交替进行,首先合成低分辨率图像,连续四帧,然后让分辨率稍作提升,接着增加帧数,比如八帧,然后再提升分辨率,再增加时长,整个训练是一个增量式的过程。
应用:street views,customized gaming,motion transfer
Part 4 : 2D vs 3D
WGAN-GP是传统的2D生成对抗网络,能够生成样本。提出了Visual object networks,不仅能合成2D图像,还能创建3D模型,可以将模型投影到深度图加掩模的2.5D表示,再合成最终的2D图像。这其中最大的优势在于,可以生成不同视角下的图像,或者改变物体形状而保持视角和表面纹理,或者固定物体形状和视角,只更换表面纹理,从而使这三个要素彼此分离,共同支撑3D场景中的编辑。
#learning 3D disentanglement#
首先给定物体形状的编码,训练一个网络来生成3D模型,同样地,用判别器来检查生成样本是真是假。接着,将3D模型投影,得到2.5D的中间表示,投影算法的实现是可以反向求导的,梯度可以从2.5D表示传回3D模型层。之后再添加纹理,这部分比较像CycleGAN,从2.5D的草图生成2D图像。物体的形状、观察的视角以及表面纹理都可以由对应的编码所控制。整个模型采用端到端训练,对于2D图像和3D模型都有相应的判别器去鉴别真伪,所有的模块一同参与训练。
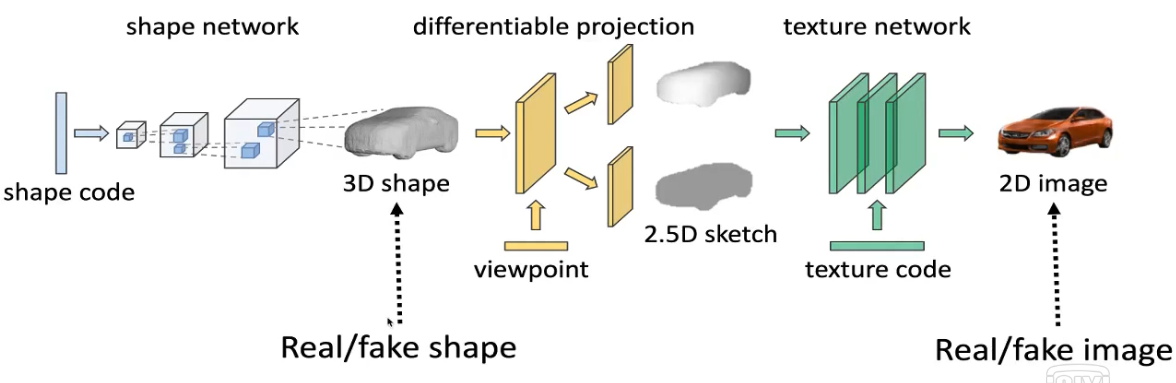
小结:
图像生成部分之外的部分,没看过论文,理解不是很深刻,具体原理不是很清楚。但是大佬的这些工作让人受益匪浅,在GAN领域真是相当厉害了。趁热打铁补论文~
#学习笔记# VALSE 2019.01.09 朱俊彦 --- Learning to Synthesize Images, Videos, and 3D Objects的更多相关文章
- AWS re:Invent(2019.01.09)
时间:2019.01.09地点:北京国际饭店
- 再起航,我的学习笔记之JavaScript设计模式09(原型模式)
我的学习笔记是根据我的学习情况来定期更新的,预计2-3天更新一章,主要是给大家分享一下,我所学到的知识,如果有什么错误请在评论中指点出来,我一定虚心接受,那么废话不多说开始我们今天的学习分享吧! 我们 ...
- 【Scala学习笔记】第01弹——Scala安装与配置
安装Scala之前先要安装JDK(1.5以上),最好安装JDK 1.8+,安装好JDK后配置JDK的环境变量. 然后去Scala官网(http://www.scala-lang.org/downloa ...
- 【Cocos2d-X开发学习笔记】第01期:PC开发环境的详细搭建
本文使用的是cocos2d-x-2.1.4版本 ,截至目前为止是最新稳定版 所谓的开发环境就是制作游戏的地方,打个比方读者就会十分清楚了.比如提到做饭,人们都会想到厨房.这是 因为厨房有炉灶.烟机.水 ...
- zabbix学习笔记----安装----2019.03.26
1.zabbix官方yum源地址:repo.zabbix.com 2.安装zabbix server zabbix server使用mysql作为数据库,在zabbix 3.X版本,安装zabbix- ...
- zabbix学习笔记----概念----2019.03.25
1.zabbix支持的通讯方式 1)agent:专用的代理程序,首推: 2)SNMP: 3)SSH/Telnet: 4)IPMI,通过标准的IPMI硬件接口,监控被监控对象的硬件特性. 2)zab ...
- 2019.01.09 bzoj2599: [IOI2011]Race(点分治)
传送门 题意:给一棵树,每条边有权.求一条路径,权值和等于K,且边的数量最小. 思路: 考虑点分治如何合并. 我们利用树形dpdpdp求树的直径的方法,边dfsdfsdfs子树边统计答案即可. 代码: ...
- 2019.01.09 bzoj3697: 采药人的路径(点分治)
传送门 点分治好题. 题意:给出一棵树,边分两种,求满足由两条两种边数相等的路径拼成的路径数. 思路: 考虑将边的种类转化成边权−1-1−1和111,这样就只用考虑由两条权值为000的路径拼成的路径数 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 0-1: Introduction of Machine Learning
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
随机推荐
- CKEditor 自定义按钮插入服务端图片
CKEditor 富文本编辑器很好用,功能很强大,在加上支持服务端图片上传的CKFinder更是方便, 最近在使用CKFinder的时候发现存在很多问题,比如上传图片的时候,图片不能按时间降序排列,另 ...
- 人脑和CPU
人类的数学运算没有计算机快是因为神经信号速度没有电信号快吗,电信号是光速吧. 不过人类的cpu大脑和存储硬盘和内存超过目前计算机n条街,虽然传输速度慢,但是传输量也是大的,其实计算机就是根据人脑设计的 ...
- java selenium webdriver第一讲 seleniumIDE
Selenium是ThoughtWorks公司,一个名为Jason Huggins的测试为了减少手工测试的工作量,自己实现的一套基于Javascript语言的代码库 使用这套库可以进行页面的交互操作, ...
- java 多线程系列---JUC原子类(五)之AtomicLongFieldUpdater原子类
AtomicLongFieldUpdater介绍和函数列表 AtomicLongFieldUpdater可以对指定"类的 'volatile long'类型的成员"进行原子更新.它 ...
- javascript——常用函数
1.获取随机数: function GetRandomNum(n, m) { //n-m之间的随机数 return Math.floor(Math.random() * (m - n + 1) + n ...
- C# 连接Mysql 字符串
Database=XXX;Data Source=XXX;User Id=XXX;Password=XXX;pooling=false;CharSet=utf8;port=3306
- http协议基础教程
引言 HTTP 是一个属于应用层的面向对象的协议,由于其简捷.快速的方式,适用于分布式超媒体信息系统.它于1990年提出,经过几年的使用与发展,得到不断地完善和 扩展.目前在WWW中使用的是HTTP/ ...
- PL/SQL批处理语句(一)BULK COLLECT
我们知道PL/SQL程序中运行SQL语句是存在开销的,因为SQL语句是要提交给SQL引擎处理,这种在PL/SQL引擎和SQL引擎之间的控制转移叫做上下文却换,每次却换时,都有额外的开销.然而,FORA ...
- PHP的count(数组)和strlen(字符串)的内部实现
PHP的count(数组)和strlen(字符串)的内部实现上是直接显示一个长度变量,还是重头依次数一遍有多少个元素?关乎我理解这2个函数的效率..希望高人能从php的c源码上讲一讲.没有源码看过源码 ...
- 在html中打开PDF
<object classid="clsid:CA8A9780-280D-11CF-A24D-444553540000" width="990" heig ...