SparkSteaming中直连与receiver两种方式的区别
SparkStreaming的Receiver方式和直连方式有什么区别?
Receiver接收固定时间间隔的数据(放在内存中的),使用高级API,自动维护偏移量,达到固定的时间才去进行处理,效率低并且容易丢失数据,灵活性特别差,不好,而且它处理数据的时候,如果某一刻的数据量过大,那么就会造成磁盘溢写的情况,他通过WALS进行磁盘写入。
Receiver实现方式:

代码如下:
object KafkaWC02 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("kafkaWC").setMaster("local[2]") //设置线程数
val ssc = new StreamingContext(conf, Seconds(5))
//设置检查点
ssc.checkpoint("D:\\data\\checpoint\\checpoint1")
//接下来编写kafka的配置信息
val zks = "spark01:2181"
//然后是kafka的消费组
val groupId = "gp1"
//Topic的名字 Map的key是Topic名字,第二个参数是线程数
val topics = Map[String, Int]("test02" -> 1)
//创建kafka的输入数据流,来获取kafka中的数据
val data = KafkaUtils.createStream(ssc, zks, groupId, topics)
//获取到的数据是键值对的格式(key,value)
//获取到的数据是 key是偏移量 value是数据
//接下来开始处理数据
val lines = data.flatMap(_._2.split(" "))
val words = lines.map((_, 1))
val res = words.updateStateByKey(updateFunc,new HashPartitioner(ssc.sparkContext.defaultParallelism),true)
res.print()
//val result = words.reduceByKey(_ + _)
//val res = result.updateStateByKey[Int](updateFunc)
//res.print()
//打印输出
//result.print()
//启动程序
ssc.start()
//等待停止
ssc.awaitTermination()
}
//(iterator:Iteratot[(K,Seq[V]),Option[S]]))
//传过来的值是Key Value类型
//第一个参数,是我们从kafka获取到的元素,key ,String类型
//第二个参数,是我们进行单词统计的value值,Int类型
//第三个参数,是我们每次批次提交的中间结果集
val updateFunc=(iter:Iterator[(String,Seq[Int],Option[Int])])=>{
iter.map(t=>{
(t._1,t._2.sum+t._3.getOrElse(0))
})
}
}
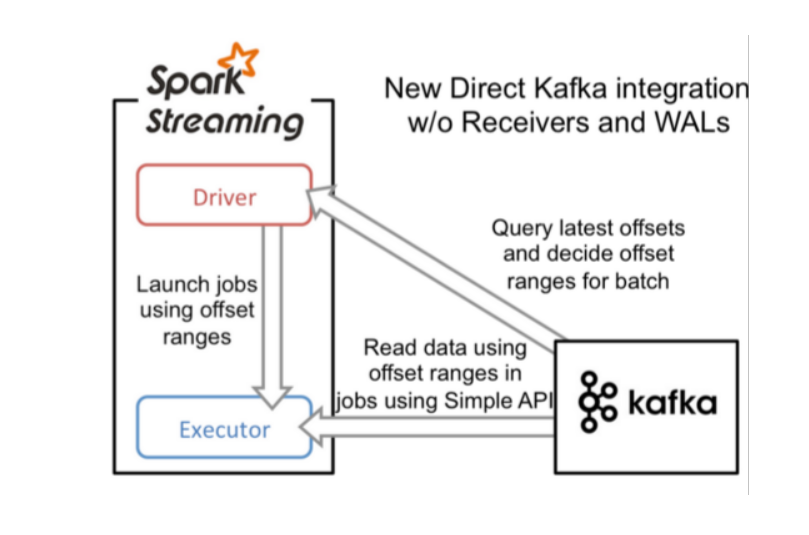
Direct直连方式,
它使用的是底层API实现Offest我们开发人员管理,这样的话,它的灵活性特别好。并且可以保证数据的安全性,而且不用担心数据量过大,因为它有预处理机制,进行提前处理,然后再批次提交任务。
Direct实现方式:
代码如下:
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Duration, StreamingContext} /**
* 重要!!! Direct直连方式
*/
object KafkaDirectWC {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Direct").setMaster("local[2]")
val ssc = new StreamingContext(conf,Duration(5000))
//指定组名
val groupId = "gp01"
//指定消费的topic名字
val topic = "tt"
//指定kafka的Broker地址(SparkStreaming的Task直接连接到Kafka分区上,用的是底层API消费)
val brokerList ="spark:9092"
//接下来我们要自己维护offset了,将offset保存到ZK中
val zkQuorum = "spark:2181"
//创建stream时使用的topic名字集合,SparkStreaming可以同时消费多个topic
val topics:Set[String] = Set(topic)
//创建一个ZkGroupTopicDirs对象,其实是指定往Zk中写入数据的目录
// 用于保存偏移量
val TopicDirs = new ZKGroupTopicDirs(groupId,topic)
//获取zookeeper中的路径“/gp01/offset/tt/”
val zkTopicPath = s"${TopicDirs.consumerOffsetDir}"
//准备kafka参数
val kafkas = Map(
"metadata.broker.list"->brokerList,
"group.id"->groupId,
//从头开始读取数据
"auto.offset.reset"->kafka.api.OffsetRequest.SmallestTimeString
)
// zookeeper 的host和ip,创建一个client,用于更新偏移量
// 是zookeeper客户端,可以从zk中读取偏移量数据,并更新偏移量
val zkClient = new ZkClient(zkQuorum)
//"/gp01/offset/tt/0/10001"
//"/gp01/offset/tt/1/20001"
//"/gp01/offset/tt/2/30001"
val clientOffset = zkClient.countChildren(zkTopicPath)
// 创建KafkaStream
var kafkaStream :InputDStream[(String,String)]= null
//如果zookeeper中有保存offset 我们会利用这个offset作为KafkaStream的起始位置
//TopicAndPartition [/gp01/offset/tt/0/ , 8888]
var fromOffsets:Map[TopicAndPartition,Long] = Map()
//如果保存过offset
if(clientOffset > 0){
//clientOffset 的数量其实就是 /gp01/offset/tt的分区数目
for(i<-0 until clientOffset){
// /gp01/offset/tt/ 0/10001
val partitionOffset = zkClient.readData[String](s"$zkTopicPath/${i}")
// tt/0
val tp = TopicAndPartition(topic,i)
//将不同partition 对应得offset增加到fromoffset中
// tt/0 -> 10001
fromOffsets += (tp->partitionOffset.toLong)
}
// key 是kafka的key value 就是kafka数据
// 这个会将kafka的消息进行transform 最终kafka的数据都会变成(kafka的key,message)这样的Tuple
val messageHandler = (mmd:MessageAndMetadata[String,String])=>
(mmd.key(),mmd.message())
// 通过kafkaUtils创建直连的DStream
//[String,String,StringDecoder, StringDecoder,(String,String)]
// key value key解码方式 value的解码方式 接收数据的格式
kafkaStream = KafkaUtils.createDirectStream
[String,String,StringDecoder,
StringDecoder,(String,String)](ssc,kafkas,fromOffsets,messageHandler)
}else{
//如果未保存,根据kafkas的配置使用最新的或者最旧的offset
kafkaStream = KafkaUtils.createDirectStream
[String,String,StringDecoder,StringDecoder](ssc,kafkas,topics)
}
//偏移量范围
var offsetRanges = Array[OffsetRange]()
//从kafka读取的数据,是批次提交的,那么这块注意下,
// 我们每次进行读取数据后,需要更新维护一下偏移量
//那么我们开始进行取值
// val transform = kafkaStream.transform{
// rdd=>
// //得到该RDD对应得kafka消息的offset
// // 然后获取偏移量
// offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// rdd
// }
// val mes = transform.map(_._2)
// 依次迭代DStream中的RDD
kafkaStream.foreachRDD{
//对RDD进行操作 触发Action
kafkardd=> offsetRanges = kafkardd.asInstanceOf[HasOffsetRanges].offsetRanges //下面 你就可以怎么写都行了,为所欲为
val maps = kafkardd.map(_._2) maps.foreach(println) for(o<-offsetRanges){
// /gp01/offset/tt/ 0
val zkpath = s"${TopicDirs.consumerOffsetDir}/${o.partition}"
//将该partition的offset保存到zookeeper中
// /gp01/offset/tt/ 0/88889
ZkUtils.updatePersistentPath(zkClient,zkpath,o.untilOffset.toString)
}
}
// 启动
ssc.start()
ssc.awaitTermination()
}
}
SparkSteaming中直连与receiver两种方式的区别的更多相关文章
- Redis持久化的两种方式和区别
该文转载自:http://www.cnblogs.com/swyi/p/6093763.html Redis持久化的两种方式和区别 Redis是一种高级key-value数据库.它跟memcached ...
- 引入外部CSS的两种方式及区别
1.CSS的两种引入方式 通过@import指令引入 @import指令是CSS语言的一部分,使用时把这个指令添加到HTML的一个<style>标签中: 要与外部的CSS文件关联起来,得使 ...
- Javascript绑定事件的两种方式的区别
命名函数 <input type="button" onclick="check()" id="btn"/> <scrip ...
- JQuery中阻止事件冒泡的两种方式及其区别
JQuery 提供了两种方式来阻止事件冒泡. 方式一:event.stopPropagation(); $("#div1").mousedown(function(event){ ...
- vue 路由传参 params 与 query两种方式的区别
初学vue的时候,不知道如何在方法中跳转界面并传参,百度过后,了解到两种方式,params 与 query.然后,错误就这么来了: router文件下index.js里面,是这么定义路由的: { p ...
- UIImage创建图片的两种方式的区别
在工作中经常会遇到添加图片,用哪种方式添加更好呢?请看详解 方法一: UIImage *image = [UIImage imageNamed:@"haha"]; 这种方法创建的图 ...
- c++构造函数成员初始化中赋值和初始化列表两种方式的区别
先总结下: 由于类成员初始化总在构造函数执行之前 1)从必要性: a. 成员是类或结构,且构造函数带参数:成员初始化时无法调用缺省(无参)构造函数 b. 成员是常量或引用:成员无法赋值,只能被初始化 ...
- js对象中属性调用.和[] 两种方式的区别
JS 调用属性一般有两种方法——点和中括号的方法. 标准格式是对象.属性(不带双引号),注意一点的是:js对象的属性,key标准是不用加引号的,加也可以,特别的情况必须加,如果key数字啊,表达式啊等 ...
- svn检出两种方式的区别
第一种是“做为新项目检出,并使用新建项目向导进行配置(仅当资源库中不存在.project工程文件时才可用,意思是如果代码库中有了这个工程文件,那么它就认为这是一个信息完整的工程,在导入的过程中就不需要 ...
随机推荐
- check_mk检测插件 - raid监控
mk_raidstatus python版本 #!/usr/bin/env python # -*- encoding: utf-8; py-indent-offset: 4 -*- import s ...
- 缓存的set、getAndTouch一定要谨慎使用
缓存的set.getAndTouch一定要谨慎使用. 很多人认为缓存在内存中性能良好,频繁更新,却不想机器的IO无法支撑,结果就是缓存成了系统的瓶颈.
- robotframework实战二---Jenkins连用
1.下载插件robot Jenkins环境搭建就不用说了,网上有很多帖子,你在使用时,你需要做以下几步 因为目前我已经安装了 2.新建项目 因为有重名的项目,所以会提示以下内容 你需要配置的内容就两处 ...
- CCF CSP 201712-2 游戏
题目链接:http://118.190.20.162/view.page?gpid=T67 问题描述 有n个小朋友围成一圈玩游戏,小朋友从1至n编号,2号小朋友坐在1号小朋友的顺时针方向,3号小朋友坐 ...
- Can Microsoft’s exFAT file system bridge the gap between OSes?
转自:http://arstechnica.com/information-technology/2013/06/review-is-microsofts-new-data-sharing-syste ...
- Thymeleaf模板引擎绕过浏览器缓存加载静态资源js,css文件
浏览器会缓存相同文件名的css样式表或者javascript文件.这给我们调试带来了障碍,好多时候修改的代码不能在浏览器正确显示. 静态常见的加载代码如下: <link rel="st ...
- requireJS的学习
官方文档 http://www.requirejs.cn/ 参考链接 http://www.w3cschool.cc/w3cnote/requirejs-tutorial-1.html http:// ...
- 连接MYSQL 错误代码2003
问题是服务里面mysql没有启动或者mysql服务丢失 解决办法: 开始->运行->cmd,进到mysql安装的bin目录(以我的为例,我的安装在D盘)D:\MySQL\bin>my ...
- python实现简单分类knn算法
原理:计算当前点(无label,一般为测试集)和其他每个点(有label,一般为训练集)的距离并升序排序,选取k个最小距离的点,根据这k个点对应的类别进行投票,票数最多的类别的即为该点所对应的类别.代 ...
- Linux apt & yum 及 常用命令
yum yum 语法 yum [options] [command] [package ...] options:可选,选项包括-h(帮助),-y(当安装过程提示选择全部为"yes" ...