CS231n 2016 通关 第三章-SVM与Softmax
1===本节课对应视频内容的第三讲,对应PPT是Lecture3
2===本节课的收获
===熟悉SVM及其多分类问题
===熟悉softmax分类问题
===了解优化思想
由上节课即KNN的分析步骤中,了解到做图像分类的主要步骤
===根据数据集建立模型
===得到loss function
===根据loss function 对参数做优化
=========================================================================================
1、SVM


上图作图为通过f(x,w)得到输入图像的输出值,这里成为scores (3*4) * (4*1)》》3*1的输出值
右图 (3*4) *(4*3)》》3*3的输出值
那么如何根据输出值判定最终的label?》》建立SVM模型,得到loss,进行优化,得到最终模型。
参考之前的SVM知识对其基本理解。此处使用多分类的hinge loss:
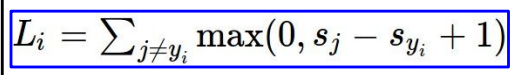
依照scores带入hinge loss:

依次计算,得到最终值,并求和再平均:
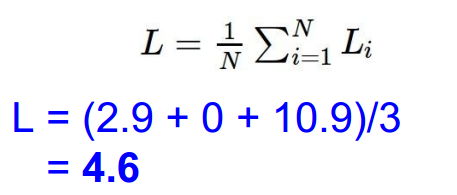
问题1:如果在求loss时,允许j=y_i
此时L会比之前未包含的L大1
问题2:如果对1个样本做loss时使用对loss做平均,而不是求和,会怎样?
相当于sum乘以常系数
问题3:如果使用下列的loss function会怎样?
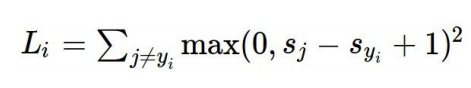
这其实是二次的hinge loss ,在某些情况下会使用。并且某些情况下结果比一次的hinge loss更好,此处使用一次形式。
问题4:上述求得的hinge loss的最大值与最小值:
最小值为0,最大值可以无限大。
问题5:通常在初始化f(x,w)中的参数w时,w值范围较小,此时得到的scores接近于0,那么这时候的loss是?
此时正确score与错误score的差接近于0,对于3classes,loss的结果是2。
实现SVM loss function的代码结构:

svm 的loss function中bug:
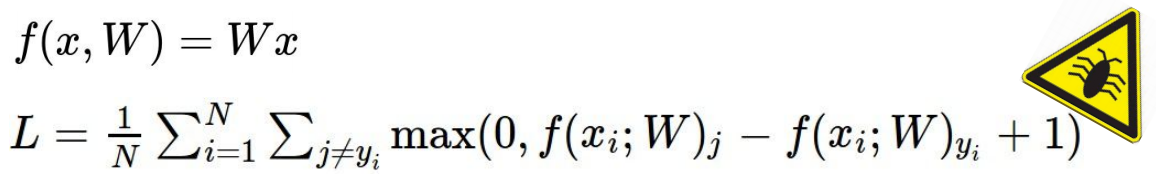
简要说明:当loss 为0,则对w进行缩放,结果依旧是0,如何解决?如下图所示:

加入正则项:

加入正则,对w进行约束,常用的正则有L1 L2,对应的note和作用使用L2正则,关于正则,在后面的章节会有分析。
L1趋于选取稀疏的参数,L2趋于选取数值较小且离散的参数。
==========================================================================================
2、softmax
在机器学习推导系列中,对softmax进行了推导。课作为参考:ML 徒手系列 最大似然估计
在f(x,w)的基础上,改变score:
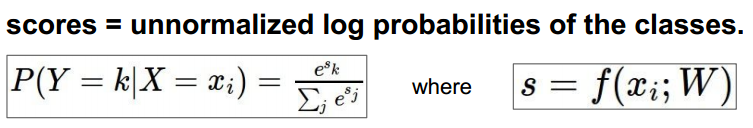
此时的score是0到1之间的值,且所以的score之和为1.大的score代表此score对应图像属于的某一个class的概率大。
使用似然估计作为loss,本来是似然估计越大越好,但通常loss使用越小时更直观,所以乘以-1:
单一样本:
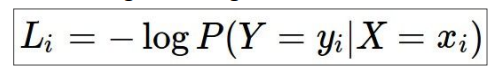
单一样本数值表示:
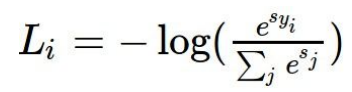
具体例子:

问题6:L_i的最大值与最小值?
可知,归一化后的取值为0到1,所以最大值为正无穷,最小值为0.
问题7:初始化参数w时,w值范围较小,此时得到的scores接近于0,那么这时候的loss是?
此时的probability变成1/num_classes,loss》log(num_classes)
视频上提到可以使用这个结果在初始值时检验模型的设置是否正确。
=======================================================================================
3、SVM与Softmax比较:
模型不同,loss function不同》》
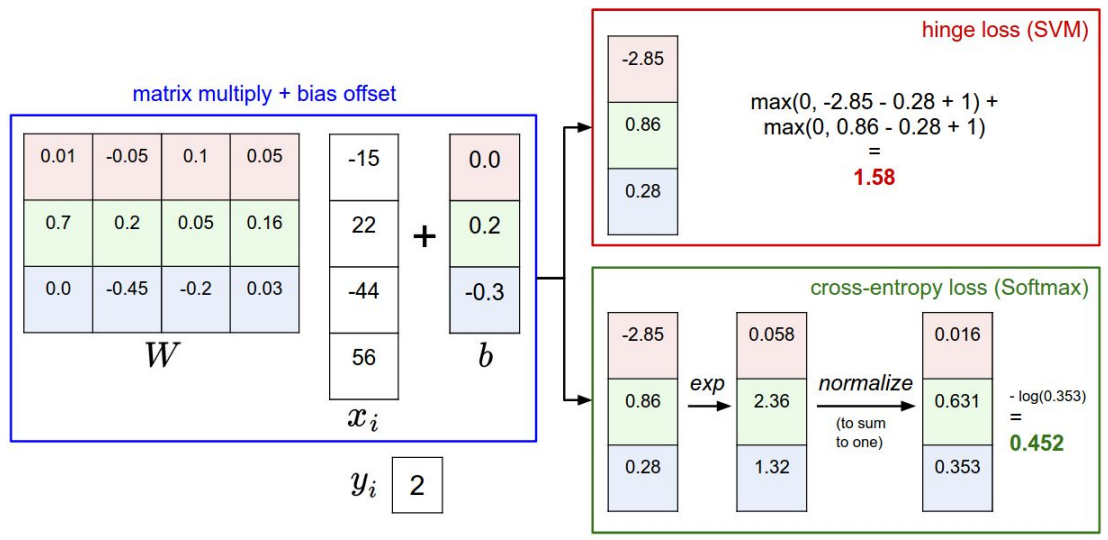
loss function:
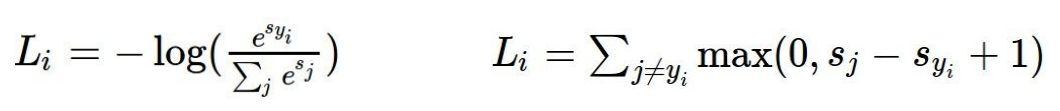
问题8:如果改变对输入数据做改变,即f(x,w)后的值发生变化,此时两个模型的loss分别会怎样变化?(如下例所示)

当改变的值不大时,对svm结果可能没影响,此时改变的点没有超过边界;但当改变较大时,会使得loss变化,此时表示数据点已经跨越了最大边界范围。
但是对softmax而言,无论大小的改变,结果都会相应变化。
课程提供了可视化的过程:http://vision.stanford.edu/teaching/cs231n/linear-classify-demo/
========================================================================================
4、优化参数
对两种模型loss 求和取平均并加入正则项。

方案1:随机选择w,计算得到相应的loss,选取产生的loss较小的w。
代码如下:
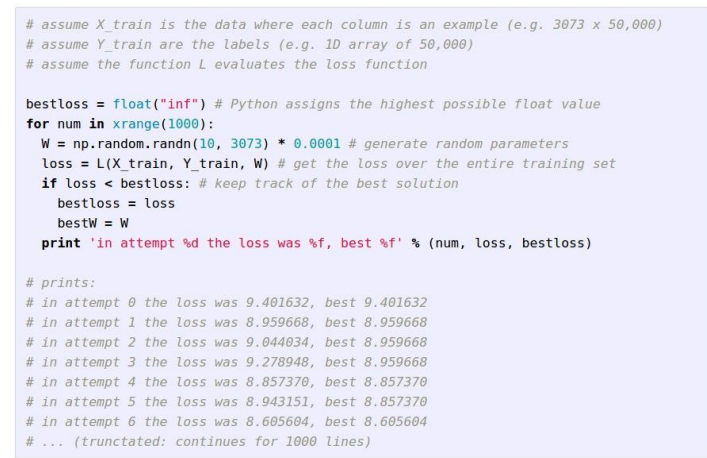
可见比较好的loss结果是8.605604,将此时的w更新到模型中,计算测试集数据得到预测的label,计算准确率,代码:

结果:

比瞎猜的概率:cifar10》》10个类别》》10% 较好。此时(上课时)的最好的模型可以做到95%准确率。
方案二:数值计算法梯度下降
梯度下降类比:

怎么达到谷底。。
一维求导:
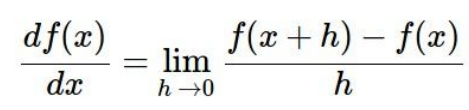
多维时,分别对分量求导。具体步骤如下所示:


上述计算了2个分量的偏导。按照此方法求其余分量偏导。代码结构如下图:

显然,这种方式计算比较繁琐,参数更新比较慢。
方案三:解析法梯度下降
方案二使用逐一对w进行微量变化,并求导数的方式步骤繁琐,并且产生了很多不必要的步骤。
方案三是直接对w分量求偏导的方式:
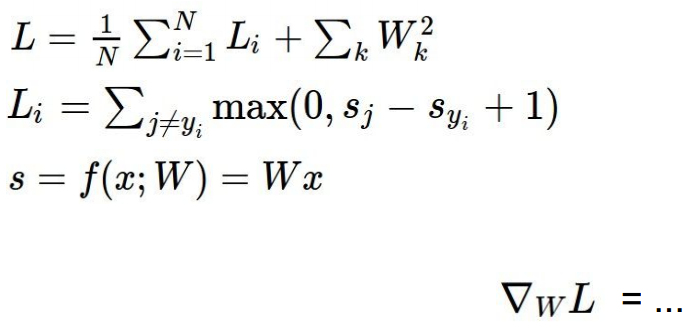

对于SVM:
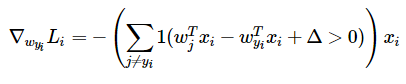
对于softmax:
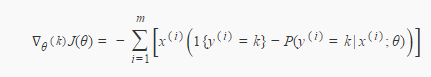
========================================================================================
5、batches
每次计算loss function 时,输入的图片数目。
使用256的batches:
经常使用的batches数目:32/64/128/256
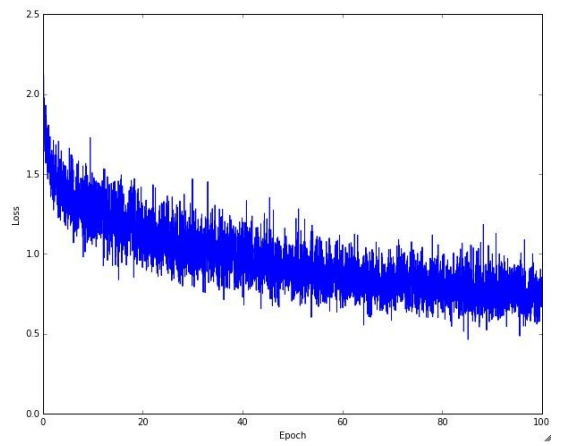
使用256 batches时的loss更新图:
更新w与b的计算公式:
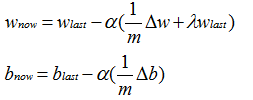
(1)对于Δw与Δb前的系数I/m是在使用batches后,得到总loss,求平均loss,然后用loss对batches次计算过程中的w与b求偏导,得到的偏导结果做平均。
可见,用了m个batches。
(2)λ为正则化系数,α为学习率或step size。
高学习率、低学习率、较好的学习率比较图:
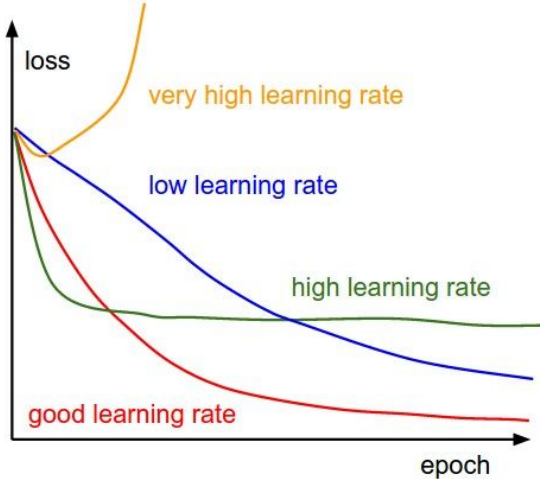
学习率属于超参数,需要通过验证的方式来选取比较合适的学习率。在课程提供的note中有介绍。
mini-batches 的代码结构:
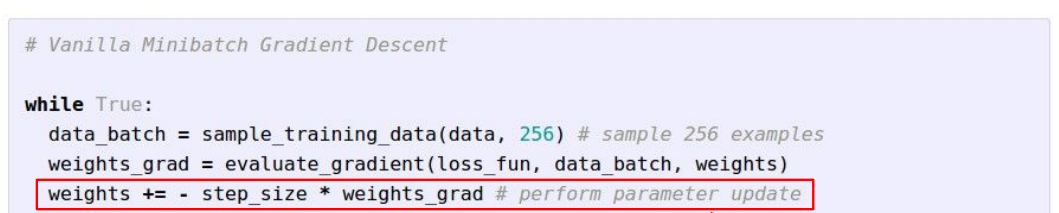
红色框中为参数更新方式,更多的更新方式:比如momentum,Adagrad,RMSProp,Adam等方式会在后续课程讲解。
提前比较各个方法的更新可视化图:
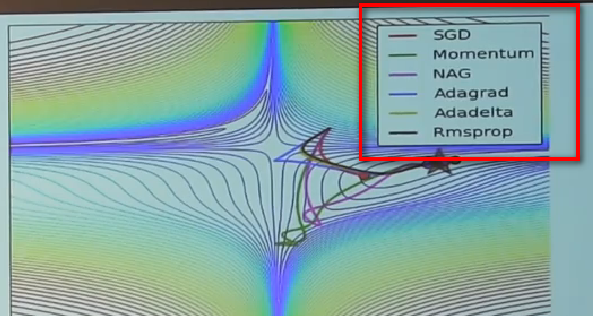
仅做了解,后续详细说。
========================================================================================
6、特征表示方式
图像特征频谱:
柱状图:
HOG/SIFT features:

Many more:GIST, LBP,Texton,SSIM, ...
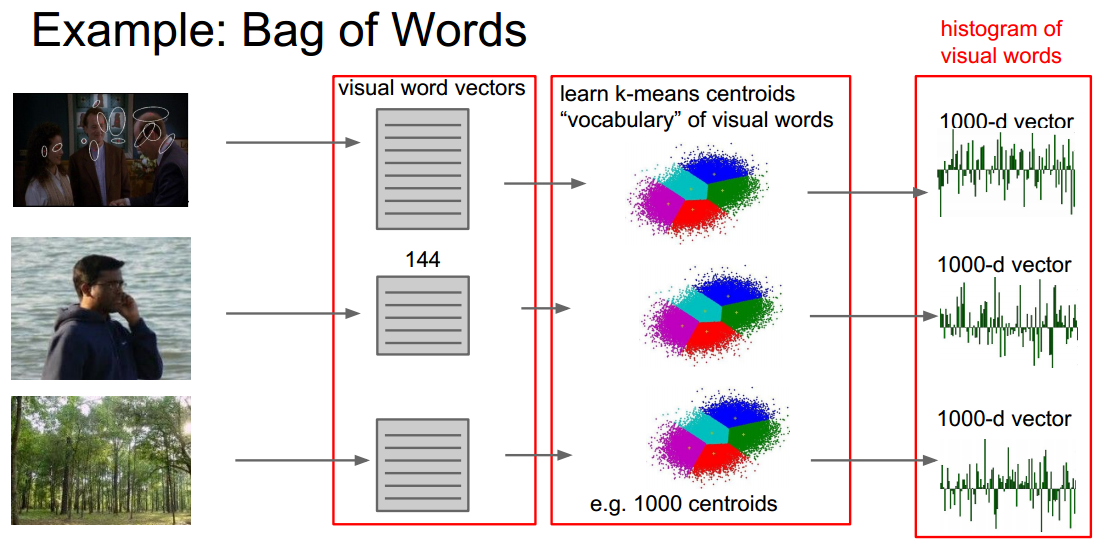
Bag of Words:
========================================================================================
7、模型与特征
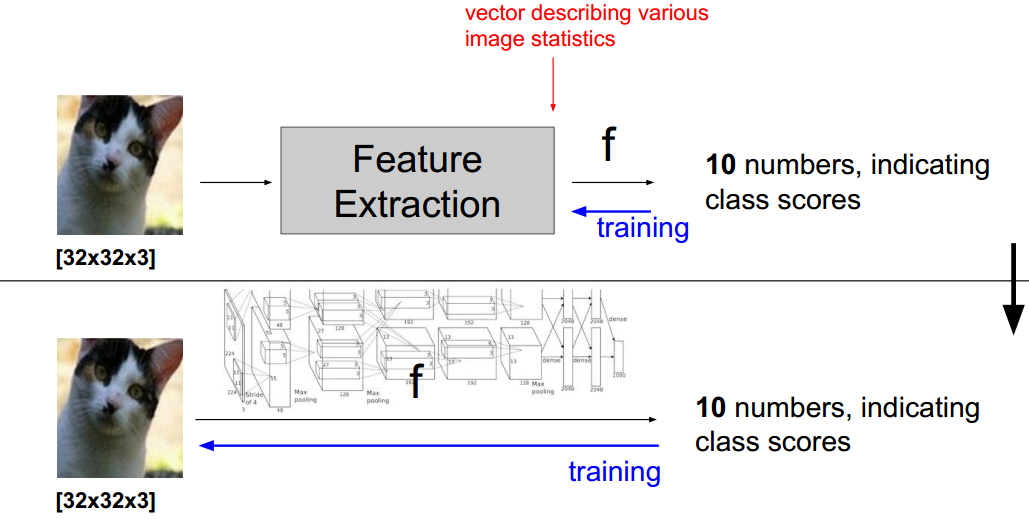
上图黑色线以上是cnn火了之前使用的方式,通过对数据做特征冲去得到多个特征向量,然后把特征向量输入到模型中进行训练。
黑色线以下,是现在很火的cnn模型,不需要对数据进行特征抽取。
参考:
附:通关CS231n企鹅群:578975100 validation:DL-CS231n
CS231n 2016 通关 第三章-SVM与Softmax的更多相关文章
- CS231n 2016 通关 第三章-SVM 作业分析
作业内容,完成作业便可熟悉如下内容: cell 1 设置绘图默认参数 # Run some setup code for this notebook. import random import nu ...
- CS231n 2016 通关 第三章-Softmax 作业
在完成SVM作业的基础上,Softmax的作业相对比较轻松. 完成本作业需要熟悉与掌握的知识: cell 1 设置绘图默认参数 mport random import numpy as np from ...
- CS231n 2016 通关 第五章 Training NN Part1
在上一次总结中,总结了NN的基本结构. 接下来的几次课,对一些具体细节进行讲解. 比如激活函数.参数初始化.参数更新等等. ====================================== ...
- CS231n 2016 通关 第六章 Training NN Part2
本章节讲解 参数更新 dropout ================================================================================= ...
- CS231n 2016 通关 第四章-NN 作业
cell 1 显示设置初始化 # A bit of setup import numpy as np import matplotlib.pyplot as plt from cs231n.class ...
- CS231n 2016 通关 第四章-反向传播与神经网络(第一部分)
在上次的分享中,介绍了模型建立与使用梯度下降法优化参数.梯度校验,以及一些超参数的经验. 本节课的主要内容: 1==链式法则 2==深度学习框架中链式法则 3==全连接神经网络 =========== ...
- CS231n 2016 通关 第五、六章 Fully-Connected Neural Nets 作业
要求:实现任意层数的NN. 每一层结构包含: 1.前向传播和反向传播函数:2.每一层计算的相关数值 cell 1 依旧是显示的初始设置 # As usual, a bit of setup impor ...
- CS231n 2016 通关 第五、六章 Dropout 作业
Dropout的作用: cell 1 - cell 2 依旧 cell 3 Dropout层的前向传播 核心代码: train 时: if mode == 'train': ############ ...
- CS231n 2016 通关 第五、六章 Batch Normalization 作业
BN层在实际中应用广泛. 上一次总结了使得训练变得简单的方法,比如SGD+momentum RMSProp Adam,BN是另外的方法. cell 1 依旧是初始化设置 cell 2 读取cifar- ...
随机推荐
- 一个专为电商定制的域名.shop
2.73亿元人民币获得.shop域名的经营权,使shop域名成为最高节拍价的顶级域名.虽然最终“最高节拍价”被web域名打破,但在电商届域名里shop还是王者.shop作为一个主要面向线上.线下销售实 ...
- java学习小笔记(三.socket通信)【转】
三,socket通信1.http://blog.csdn.net/kongxx/article/details/7288896这个人写的关于socket通信不错,循序渐进式的讲解,用代码示例说明,运用 ...
- XPath 文档 解析XMl
http://www.zvon.org/xxl/XPathTutorial/General_chi/examples.html 简介 XPath由W3C的 XPath 1.0 标准描述.本教程通过实例 ...
- SQL SERVER 集合
死锁和堵塞一直是性能测试执行中关注的重点. 下面是我整理的监控sql server数据库,在性能测试过程中是否出现死锁.堵塞的SQL语句,还算比较准备,留下来备用. --每秒死锁数量 SELECT * ...
- The tag handler class for "home.jsp" (org.apache.taglibs.standard.tag.rt.core.ForEachTag) was not found on the Java Build Path
web.xml中 listener,filter,servlet需按顺序. <listener> <listener-class>listener.VisitCountList ...
- 计算客网络赛 Coin 二项式定理+逆元
https://nanti.jisuanke.com/t/17115 Bob has a not even coin, every time he tosses the coin, the proba ...
- Spring使用proxool连接池 管理数据源
一.Proxool连接池简介及其配置属性概述 Proxool是一种Java数据库连接池技术.是sourceforge下的一个开源项目,这个项目提供一个健壮.易用的连接池,最为关键的是这个连接池提供监控 ...
- JProfiler远程监控 -转
1. 服务端安装JProfiler(与客户端版本一致) 2. 客户端配置连接: A).session——integration wizards——New remote integration B).选 ...
- spring发布RMI服务(-)
spring发布RMI服务 最近交流了一个项目,需要从RMI.WebService.接口文件中采集数据到大数据平台,下面自己测试了通过Spring发布RMI服务. 说明:RMI服务要求服务端和客户端都 ...
- 四种launchMode
注意:如果在一个singleTop或者singleInstance的ActivityA中通过startActivityForResult()方法来启动另外一个ActivityB,那么系统将直接返回Ac ...