CS231n 2016 通关 第三章-SVM与Softmax
1===本节课对应视频内容的第三讲,对应PPT是Lecture3
2===本节课的收获
===熟悉SVM及其多分类问题
===熟悉softmax分类问题
===了解优化思想
由上节课即KNN的分析步骤中,了解到做图像分类的主要步骤
===根据数据集建立模型
===得到loss function
===根据loss function 对参数做优化
=========================================================================================
1、SVM


上图作图为通过f(x,w)得到输入图像的输出值,这里成为scores (3*4) * (4*1)》》3*1的输出值
右图 (3*4) *(4*3)》》3*3的输出值
那么如何根据输出值判定最终的label?》》建立SVM模型,得到loss,进行优化,得到最终模型。
参考之前的SVM知识对其基本理解。此处使用多分类的hinge loss:
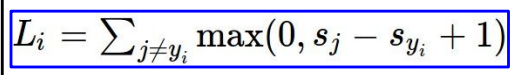
依照scores带入hinge loss:

依次计算,得到最终值,并求和再平均:
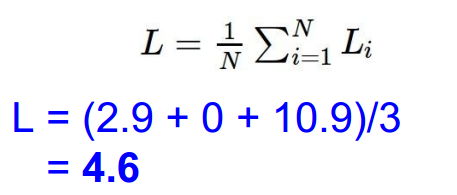
问题1:如果在求loss时,允许j=y_i
此时L会比之前未包含的L大1
问题2:如果对1个样本做loss时使用对loss做平均,而不是求和,会怎样?
相当于sum乘以常系数
问题3:如果使用下列的loss function会怎样?
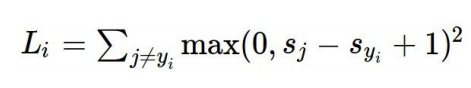
这其实是二次的hinge loss ,在某些情况下会使用。并且某些情况下结果比一次的hinge loss更好,此处使用一次形式。
问题4:上述求得的hinge loss的最大值与最小值:
最小值为0,最大值可以无限大。
问题5:通常在初始化f(x,w)中的参数w时,w值范围较小,此时得到的scores接近于0,那么这时候的loss是?
此时正确score与错误score的差接近于0,对于3classes,loss的结果是2。
实现SVM loss function的代码结构:

svm 的loss function中bug:
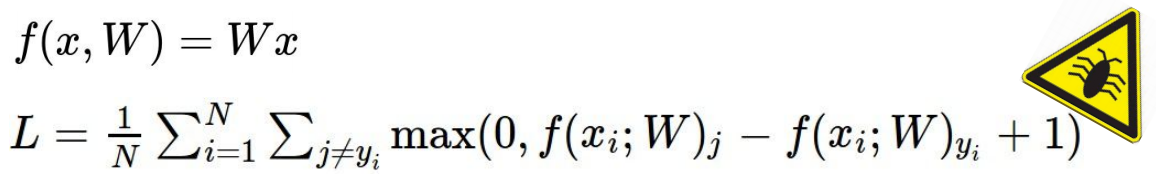
简要说明:当loss 为0,则对w进行缩放,结果依旧是0,如何解决?如下图所示:

加入正则项:

加入正则,对w进行约束,常用的正则有L1 L2,对应的note和作用使用L2正则,关于正则,在后面的章节会有分析。
L1趋于选取稀疏的参数,L2趋于选取数值较小且离散的参数。
==========================================================================================
2、softmax
在机器学习推导系列中,对softmax进行了推导。课作为参考:ML 徒手系列 最大似然估计
在f(x,w)的基础上,改变score:
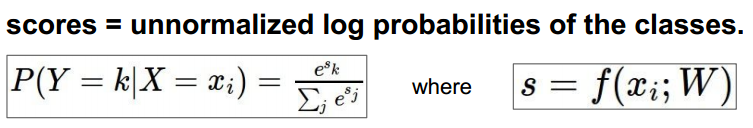
此时的score是0到1之间的值,且所以的score之和为1.大的score代表此score对应图像属于的某一个class的概率大。
使用似然估计作为loss,本来是似然估计越大越好,但通常loss使用越小时更直观,所以乘以-1:
单一样本:
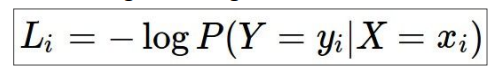
单一样本数值表示:
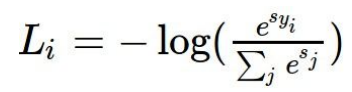
具体例子:

问题6:L_i的最大值与最小值?
可知,归一化后的取值为0到1,所以最大值为正无穷,最小值为0.
问题7:初始化参数w时,w值范围较小,此时得到的scores接近于0,那么这时候的loss是?
此时的probability变成1/num_classes,loss》log(num_classes)
视频上提到可以使用这个结果在初始值时检验模型的设置是否正确。
=======================================================================================
3、SVM与Softmax比较:
模型不同,loss function不同》》
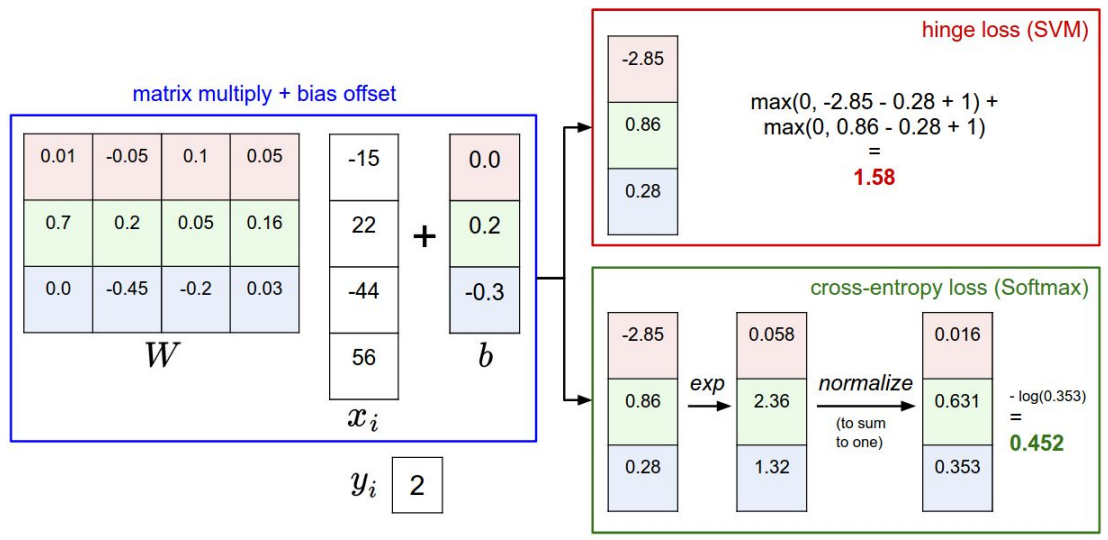
loss function:
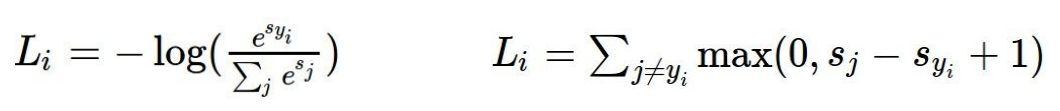
问题8:如果改变对输入数据做改变,即f(x,w)后的值发生变化,此时两个模型的loss分别会怎样变化?(如下例所示)

当改变的值不大时,对svm结果可能没影响,此时改变的点没有超过边界;但当改变较大时,会使得loss变化,此时表示数据点已经跨越了最大边界范围。
但是对softmax而言,无论大小的改变,结果都会相应变化。
课程提供了可视化的过程:http://vision.stanford.edu/teaching/cs231n/linear-classify-demo/
========================================================================================
4、优化参数
对两种模型loss 求和取平均并加入正则项。

方案1:随机选择w,计算得到相应的loss,选取产生的loss较小的w。
代码如下:
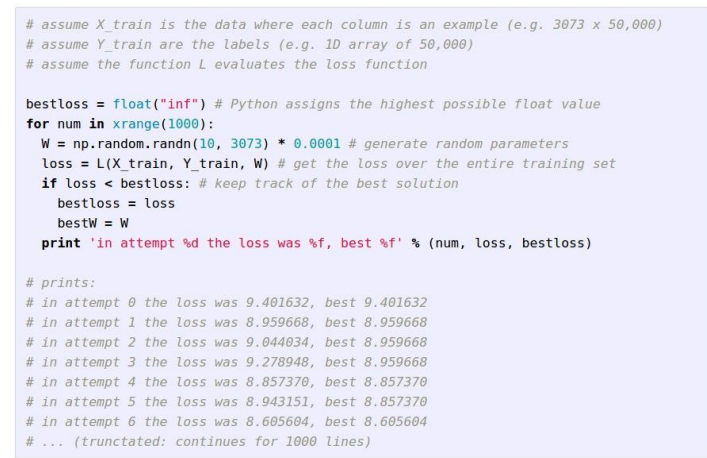
可见比较好的loss结果是8.605604,将此时的w更新到模型中,计算测试集数据得到预测的label,计算准确率,代码:

结果:

比瞎猜的概率:cifar10》》10个类别》》10% 较好。此时(上课时)的最好的模型可以做到95%准确率。
方案二:数值计算法梯度下降
梯度下降类比:

怎么达到谷底。。
一维求导:
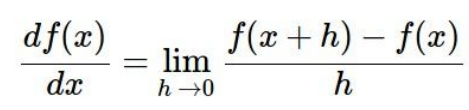
多维时,分别对分量求导。具体步骤如下所示:


上述计算了2个分量的偏导。按照此方法求其余分量偏导。代码结构如下图:

显然,这种方式计算比较繁琐,参数更新比较慢。
方案三:解析法梯度下降
方案二使用逐一对w进行微量变化,并求导数的方式步骤繁琐,并且产生了很多不必要的步骤。
方案三是直接对w分量求偏导的方式:
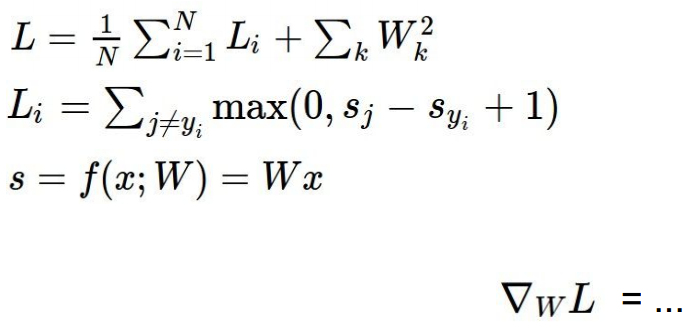

对于SVM:
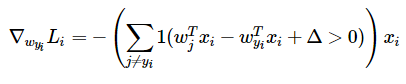
对于softmax:
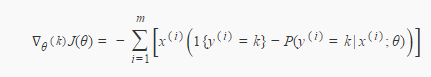
========================================================================================
5、batches
每次计算loss function 时,输入的图片数目。
使用256的batches:
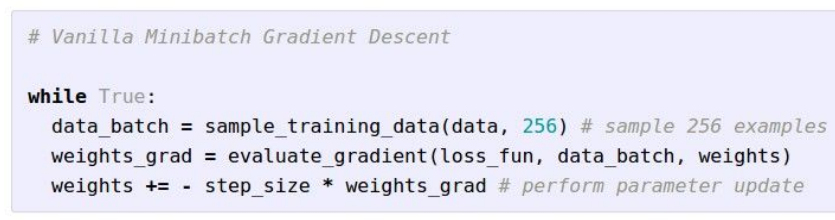
经常使用的batches数目:32/64/128/256
使用256 batches时的loss更新图:
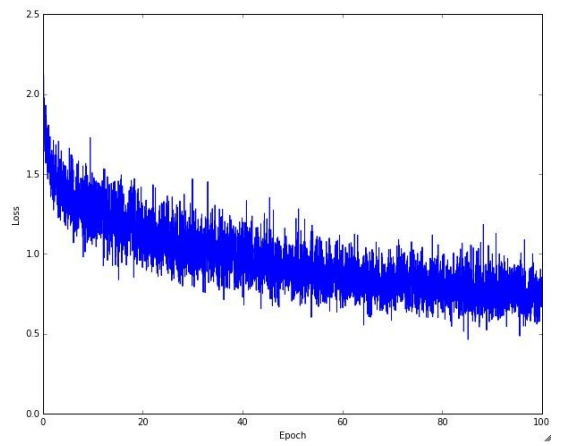
更新w与b的计算公式:
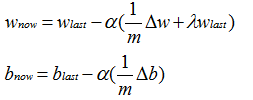
(1)对于Δw与Δb前的系数I/m是在使用batches后,得到总loss,求平均loss,然后用loss对batches次计算过程中的w与b求偏导,得到的偏导结果做平均。
可见,用了m个batches。
(2)λ为正则化系数,α为学习率或step size。
高学习率、低学习率、较好的学习率比较图:
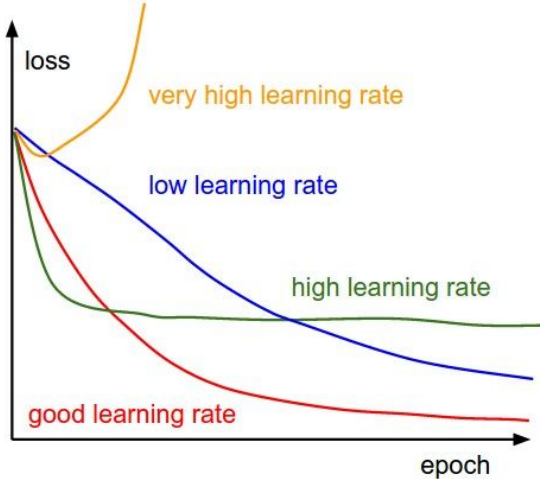
学习率属于超参数,需要通过验证的方式来选取比较合适的学习率。在课程提供的note中有介绍。
mini-batches 的代码结构:
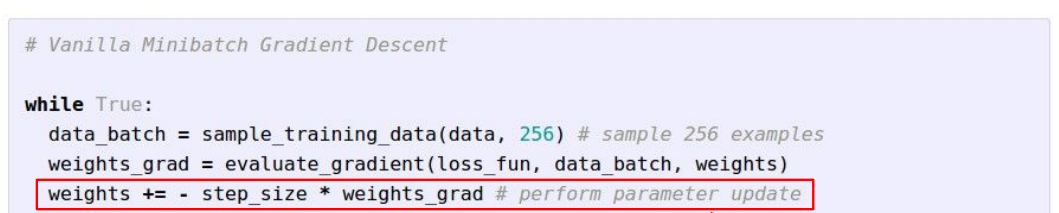
红色框中为参数更新方式,更多的更新方式:比如momentum,Adagrad,RMSProp,Adam等方式会在后续课程讲解。
提前比较各个方法的更新可视化图:
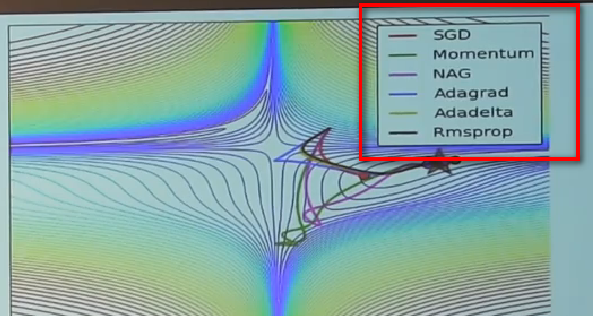
仅做了解,后续详细说。
========================================================================================
6、特征表示方式
图像特征频谱:
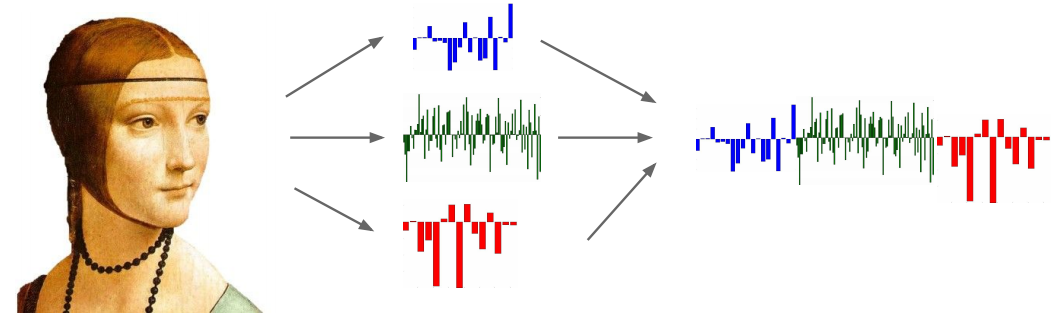
柱状图:
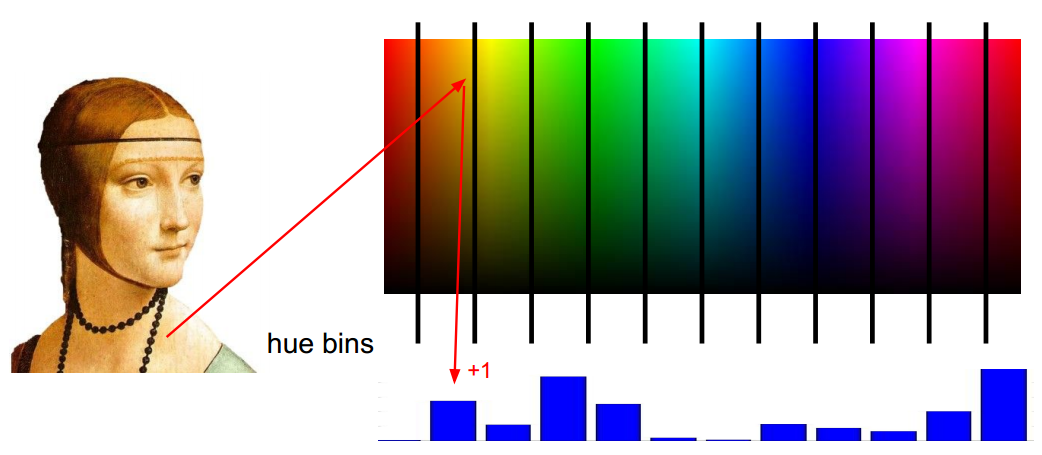
HOG/SIFT features:

Many more:GIST, LBP,Texton,SSIM, ...
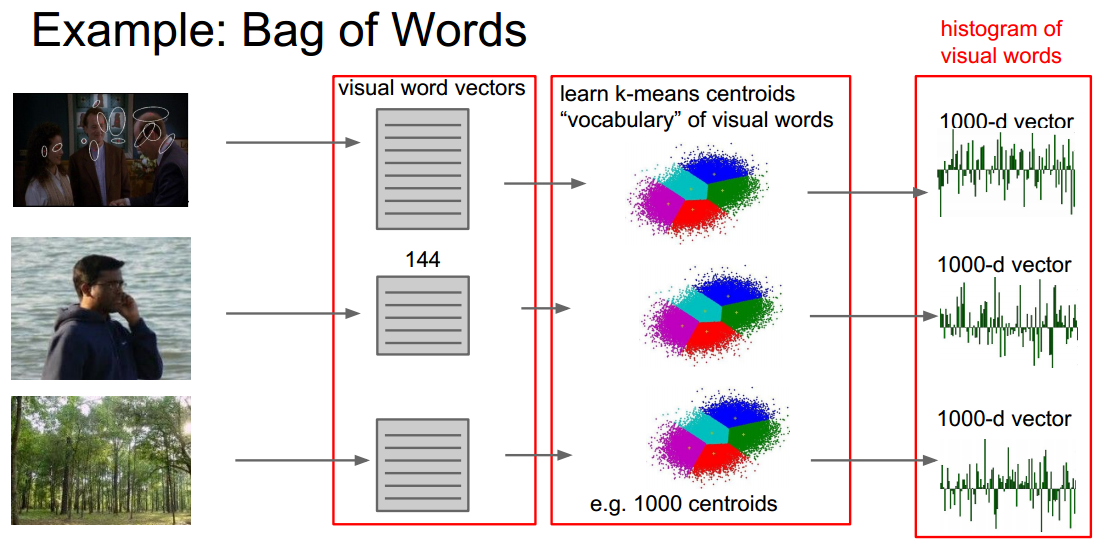
Bag of Words:
========================================================================================
7、模型与特征
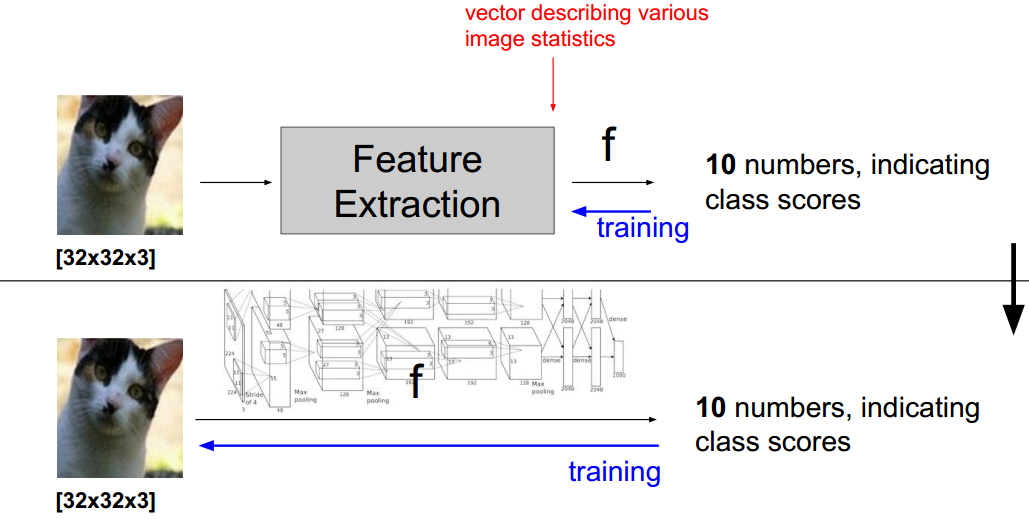
上图黑色线以上是cnn火了之前使用的方式,通过对数据做特征冲去得到多个特征向量,然后把特征向量输入到模型中进行训练。
黑色线以下,是现在很火的cnn模型,不需要对数据进行特征抽取。
参考:
附:通关CS231n企鹅群:578975100 validation:DL-CS231n
CS231n 2016 通关 第三章-SVM与Softmax的更多相关文章
- CS231n 2016 通关 第三章-SVM 作业分析
作业内容,完成作业便可熟悉如下内容: cell 1 设置绘图默认参数 # Run some setup code for this notebook. import random import nu ...
- CS231n 2016 通关 第三章-Softmax 作业
在完成SVM作业的基础上,Softmax的作业相对比较轻松. 完成本作业需要熟悉与掌握的知识: cell 1 设置绘图默认参数 mport random import numpy as np from ...
- CS231n 2016 通关 第五章 Training NN Part1
在上一次总结中,总结了NN的基本结构. 接下来的几次课,对一些具体细节进行讲解. 比如激活函数.参数初始化.参数更新等等. ====================================== ...
- CS231n 2016 通关 第六章 Training NN Part2
本章节讲解 参数更新 dropout ================================================================================= ...
- CS231n 2016 通关 第四章-NN 作业
cell 1 显示设置初始化 # A bit of setup import numpy as np import matplotlib.pyplot as plt from cs231n.class ...
- CS231n 2016 通关 第四章-反向传播与神经网络(第一部分)
在上次的分享中,介绍了模型建立与使用梯度下降法优化参数.梯度校验,以及一些超参数的经验. 本节课的主要内容: 1==链式法则 2==深度学习框架中链式法则 3==全连接神经网络 =========== ...
- CS231n 2016 通关 第五、六章 Fully-Connected Neural Nets 作业
要求:实现任意层数的NN. 每一层结构包含: 1.前向传播和反向传播函数:2.每一层计算的相关数值 cell 1 依旧是显示的初始设置 # As usual, a bit of setup impor ...
- CS231n 2016 通关 第五、六章 Dropout 作业
Dropout的作用: cell 1 - cell 2 依旧 cell 3 Dropout层的前向传播 核心代码: train 时: if mode == 'train': ############ ...
- CS231n 2016 通关 第五、六章 Batch Normalization 作业
BN层在实际中应用广泛. 上一次总结了使得训练变得简单的方法,比如SGD+momentum RMSProp Adam,BN是另外的方法. cell 1 依旧是初始化设置 cell 2 读取cifar- ...
随机推荐
- Effective java第一章引言
菜鸟一枚,开始读第一本书<Effective Java>(第二版)~ 看引言就有好多名词不懂(>_<) 导出的API由所有可在定义该API的包之外访问的API元素组成.一个包的 ...
- QT QDockWidget锚接部件 和 QTreeWidget 树形部件 构成树形选择项
1. 如图,在mainwindow中 添加DockWidget到右侧,里面镶嵌TreeWidget. 2. QTreeWidget *treeWidget = new QTreeWidget; // ...
- Android 开发工具(android studio )安装中的问题记录
第一个问题,下载安装android studio . 由于国内无法通过正常方式访问谷歌官网,所以下载的确是个问题,在我仔细寻找下,发现下面两个网站可以下载: 第一个:http://www.androi ...
- poi读取Excel内容数据
public static void main(String[] args) { try{ //获取文件输入流 FileInputStream fileIn = new FileInputStream ...
- Tensorflow中的transpose函数解析
transpose函数作用是对矩阵进行转换操作 相信说完上面这一句,大家和我一样都是懵逼状态,完全不知道是怎么回事,那么接下来和我一起探讨吧 1.二维数组 x = [[1,3,5], [2,4,6] ...
- numpy常用函数之randn
numpy中有一些常用的用来产生随机数的函数,randn就是其中一个,randn函数位于numpy.random中,函数原型如下: numpy.random.randn(d0, d1, ..., dn ...
- JavaScript的DOM操作(节点操作)
创建节点createElement()var node = document.createElement(“div”);没什么可说的,创建一个元素节点,但注意,这个节点不会被自动添加到文档(docum ...
- java学习笔记 --- 多线程(多线程的创建方式)
1.创建多线程方式1——继承Thread类. 步骤: A:自定义类MyThread继承Thread类. B:MyThread类里面重写run()? 为什么是run()方法呢? C:创建对象 D:启 ...
- Codeforces Round #286 (Div. 2)B. Mr. Kitayuta's Colorful Graph(dfs,暴力)
数据规模小,所以就暴力枚举每一种颜色的边就行了. #include<iostream> #include<cstdio> #include<cstdlib> #in ...
- k-means算法的优缺点以及改进
大家接触的第一个聚类方法,十有八九都是K-means聚类啦.该算法十分容易理解,也很容易实现.其实几乎所有的机器学习和数据挖掘算法都有其优点和缺点.那么K-means的缺点是什么呢? 总结为下: (1 ...