mongo-aggregate命令详解
一、aggregate执行流程和特性
1、执行流程:
db.collection.aggregate()是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果;
下图来自官方文档截图,作为aggregate运行过程图,方便大家了解;
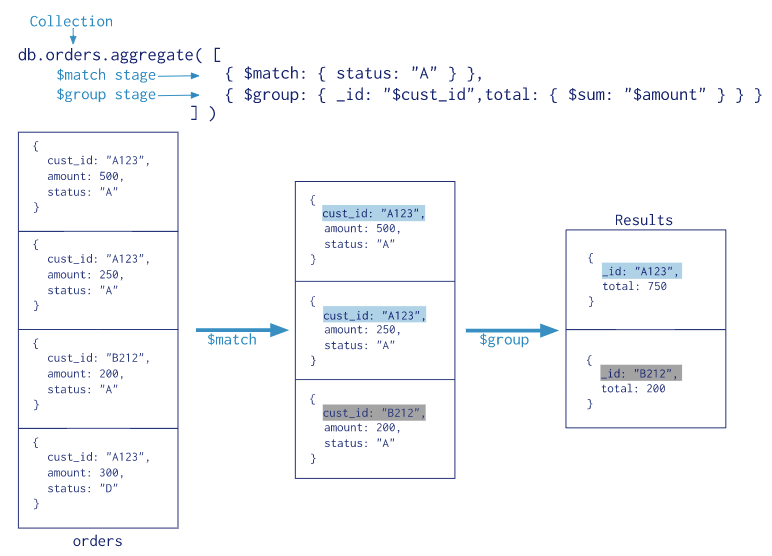
2、特性:
db.collection.aggregate();
- 可以进行多管道操作,能方便进行数据处理;
- 使用了mongodb内置的原生sql操作,聚合效率非常高,支持类似于mysql中的group by功能;
- 每个阶段管道限制为100MB的内存。如果一个节点管道超过这个极限,MongoDB将产生一个错误。为了能够在处理大型数据集,可以设置allowDiskUse为true来在聚合管道节点把数据写入临时文件。这样就可以解决100MB的内存的限制;
- 可以作用在分片集合,但结果不能输在分片集合,MapReduce可以 作用在分片集合,结果也可以输在分片集合
- 方法可以返回一个指针(cursor),数据放在内存中,直接操作。跟Mongo shell 一样指针操作;
- 输出的结果只能保存在一个文档中,BSON Document大小限制为16M。可以通过返回指针解决,版本2.6中后面:DB.collect.aggregate()方法返回一个指针,可以返回任何结果集的大小;
二、aggregate语法: db.collection.aggregate(pipeline, options)
[pipeline参数]
$group : 将集合中的文档分组,可用于统计结果,$group首先将数据根据key进行分组;
$project:可以对输入文档进行添加新字段或删除现有的字段,可以自定哪些字段显示与不显示;
$match :根据条件用于过滤数据,只输出符合条件的文档,如果放在pipeline前面,根据条件过滤数据,传输到下一个阶段管道,可以提高后续的数据处理效率。还可以放在out之前,对结果进行再一次过滤;
$redact :字段所处的document结构的级别;
$limit :用来限制MongoDB聚合管道返回的文档数;
$skip :在聚合管道中跳过指定数量的文档,并返回余下的文档;
$unwind :将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值;
$sample :随机选择从其输入指定数量的文档。如果是大于或等于5%的collection的文档,$sample进行收集扫描,进行排序,然后选择顶部的文件。因此,$sample 在收集阶段是受排序的内存限制 语法:{ $sample: { size: <positive integer> } }
$sort :将输入文档排序后输出;
$geoNear:用于地理位置数据分析;
$out :必须为pipeline最后一个阶段管道,因为是将最后计算结果写入到指定的collection中;
$indexStats :返回数据集合的每个索引的使用情况;语法:{ $indexStats: { } }
[pipeline例子]
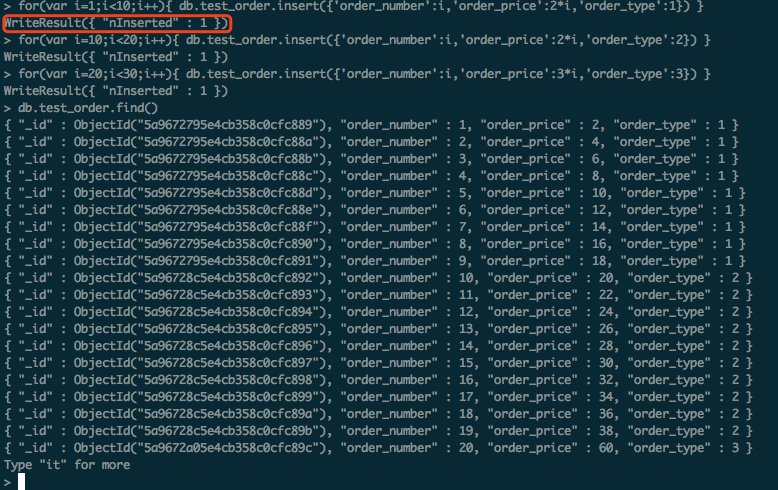
插入test数据(红色区域表示插入成功)
[$group]
_id 是要进行分组的key,如果_id为null 相当于select count(*) from table;
$sum:
统计test_order表条数 == 'select count(*) as count from test_order';

统计test_order表 order_price总和 == 'select sum(order_price) as total_order_price from test_order';

统计test_order表不同订单的order_price总和 == 'select sum(order_price) as total_order_price from test_order group by order_type';

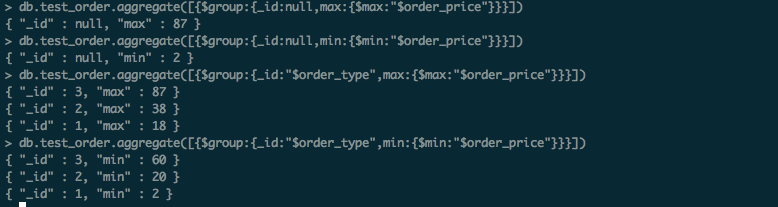
$min、$max :
统计test_order表中order_price最大价格和最小价格,不同订单的最大值和最小值 == 'select max(order_price) as order_type_max_price from test_order group by order_type';
$avg
统计test_order表中order_price平均价格 和不同订单的平均价格 == 'select avg(order_price) as order_type_avg_price from test_order group by order_type';

$push、$addToSet
列举出test_order表中不同类型的订单价格 数据都不要超出16M

$first、$last
统计test_order表中不同订单的第一条和最后一条的订单价格(如果有排序则按照排序,如果没有取自然first和last)

[$project]
根据需求去除test_order不需要展示的字段

[$match]
查询不同订单售卖的总价格,其中总价格大于100的== 'select sum(order_price) as order_type_sum_price from test_order group by order_price having order_type_sum_price > 100';

查询order_type=3的总价 = 'select sum(order_price) as total_price' from test_order where order_type = 3';

[$limit、$skip]
查询限制条数,和跳过条数可以使用在阶段管道用在$group 之前可以大大的提高查询性能

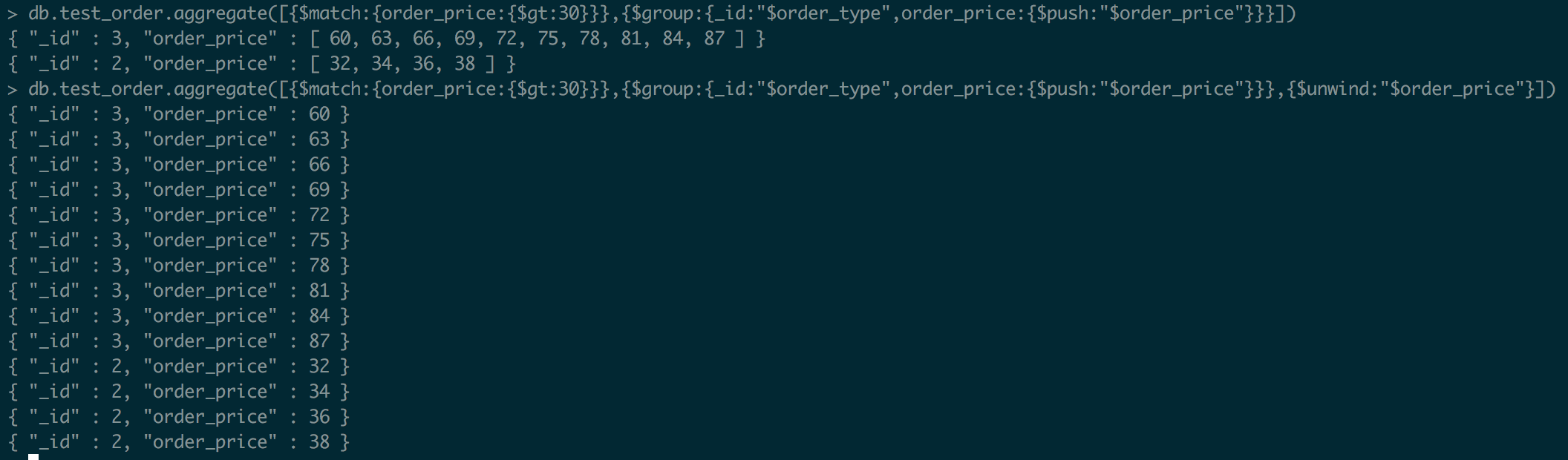
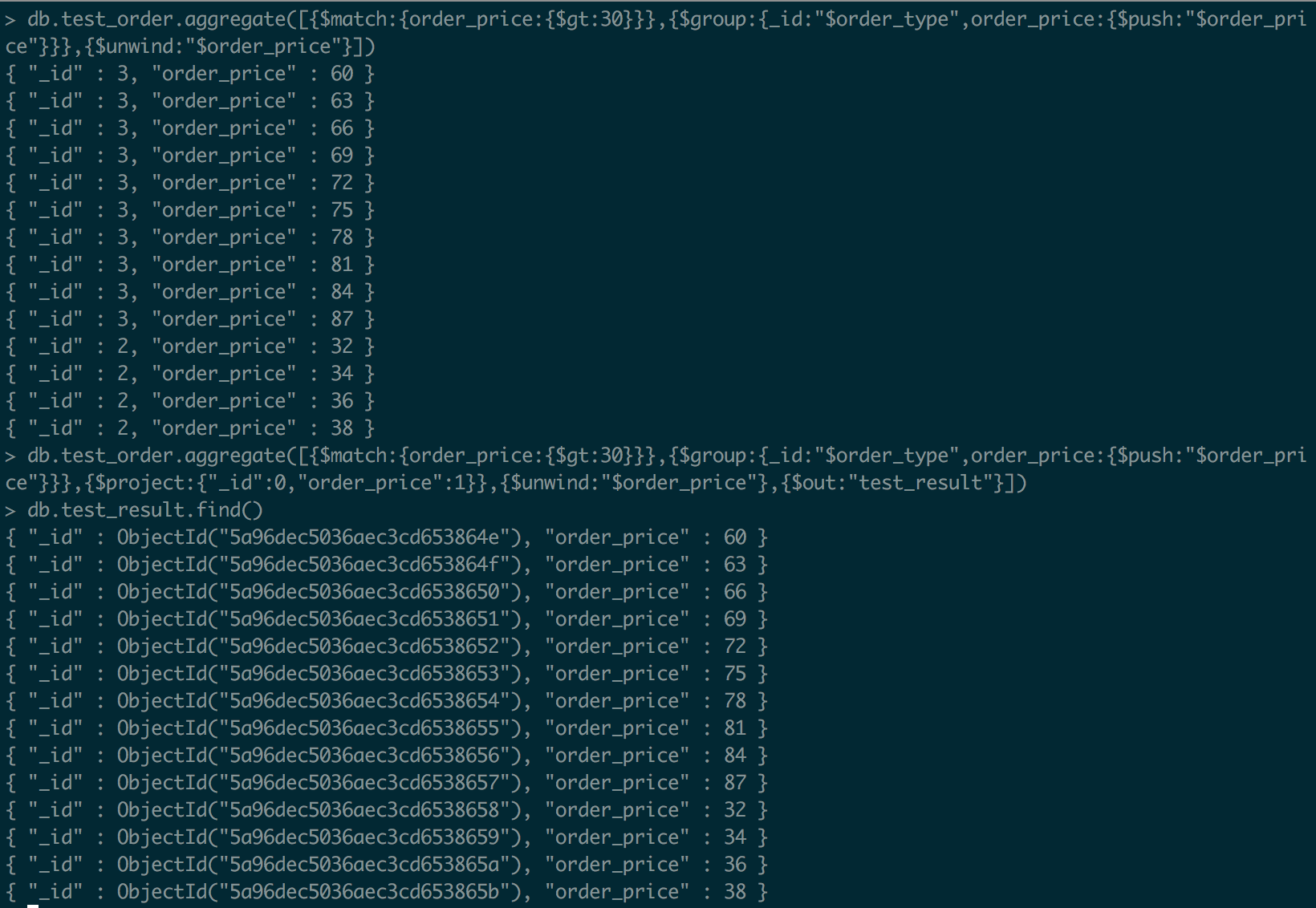
[$unwind]
可以拆分数组类型字段,其中包含数组字段值
[$out]
是把执行的结果写入指定数据表中
[options例子]
explain:返回指定aggregate各个阶段管道的执行计划信息

mongo-aggregate命令详解的更多相关文章
- 07 redi sorder set结构及命令详解
zadd key score1 value1 score2 value2 .. 添加元素 redis 127.0.0.1:6379> zadd stu 18 lily 19 hmm 20 lil ...
- 【文本处理命令】之sed命令详解
sed行处理命令详解 一.简介 sed命令是一种在线编辑器.一个面向字符流的非交互式编辑器,也就是说sed不允许用户与它进行交互操作.sed是按行来处理文本内容的,它一次处理一行内容.处理时,把当前处 ...
- Dockerfile 命令详解及最佳实践
Dockerfile 命令详解 FROM 指定基础镜像(必选) 所谓定制镜像,那一定是以一个镜像为基础,在其上进行定制.就像我们之前运行了一个 nginx 镜像的容器,再进行修改一样,基础镜像是必须指 ...
- Git初探--笔记整理和Git命令详解
几个重要的概念 首先先明确几个概念: WorkPlace : 工作区 Index: 暂存区 Repository: 本地仓库/版本库 Remote: 远程仓库 当在Remote(如Github)上面c ...
- linux yum命令详解
yum(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器.基於RPM包管理,能够从指定的服务器自动下载RP ...
- Linux下ps命令详解 Linux下ps命令的详细使用方法
http://www.jb51.net/LINUXjishu/56578.html Linux下的ps命令比较常用 Linux下ps命令详解Linux上进程有5种状态:1. 运行(正在运行或在运行队列 ...
- Docker命令详解
Docker命令详解 最近学习Docker,将docker所有命令实验了一番,特整理如下: # docker --help Usage: docker [OPTIONS] COMMAND [arg ...
- linux awk命令详解
linux awk命令详解 简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分 ...
- android adb 命令详解
ADB (Android Debug Bridge) 是android SDK中的工具,需要先配置环境变量才能使用.起调试桥的作用,可以管理安卓设备.(也叫debug工具) ---------查看设 ...
- Git 常用命令详解
Git 是一个很强大的分布式版本管理工具,它不但适用于管理大型开源软件的源代码(如:linux kernel),管理私人的文档和源代码也有很多优势(如:wsi-lgame-pro) Git 的更多介绍 ...
随机推荐
- poj_3641_Pseudoprime numbers
Fermat's theorem states that for any prime number p and for any integer a > 1, ap = a (mod p). Th ...
- SEOer必读:50个网站推广方法
1.论坛推广 这里所说的论坛推广绝对不是在论坛里一个一个版贴广告,也不是将网站地址加在签名里然后疯狂刷屏,那样既耗费精力而且效果也不见得好,论坛管理员只要点几下鼠标就能将你的帖子全部删除,顺便封掉你的 ...
- tcl之控制流-foreach
- Spark Streaming 交互 Kafka的两种方式
一.Spark Streaming连Kafka(重点) 方式一:Receiver方式连:走磁盘 使用High Level API(高阶API)实现Offset自动管理,灵活性差,处理数据时,如果某一时 ...
- poj2001Shortest Prefixes(trie)
Shortest Prefixes Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 18687 Accepted: 808 ...
- springboot 入门2 开发环境与生产环境采用不同配置问题
目开发中我们通常有两套配置信息 分别配置了我们的数据源信息等? 那么我们要如何不通过修改配置文件大量配置来实现简单的修改与配置来实现相关配置加载功能 首先springboot 有一个核心的配置文件a ...
- 分别用反射、编程接口的方式创建DataFrame
1.通过反射的方式 使用反射来推断包含特定数据类型的RDD,这种方式代码比较少,简洁,只要你会知道元数据信息时什么样,就可以使用了 代码如下: import org.apache.spark.sql. ...
- echart图表展示数据-简单的柱状图
话不多说,先上几张效果图 给大家看看 1:echart所用到的文件包需要事先引入好具体可见 http://echarts.baidu.com/doc/start.html 2:本例中所有的数据都是通过 ...
- ElasticSearch学习笔记(三)-- 查询
1. URISearch详解与演示 2. QueryDSL简介 3. 字段类查询简介及match-query 4. 相关性算分 5. match-phrase-query 6. query-strin ...
- svn Previous operation has not finished; run 'cleanup' if it was interrupted
svn cleanup failed–previous operation has not finished; run cleanup if it was interrupted Usually, a ...