A/B Testing with Practice in Python (Part One)
I learned A/B testing from a Youtube vedio. The link is https://www.youtube.com/watch?v=Bu7OqjYk0jM.
I will divide the note into two parts. The first part is generally an overview of hypothesis testing. Most concepts can be found in the article "Statistics Basics: Main Concepts in Hypothesis Testing" and I will focus on pratical applications here.




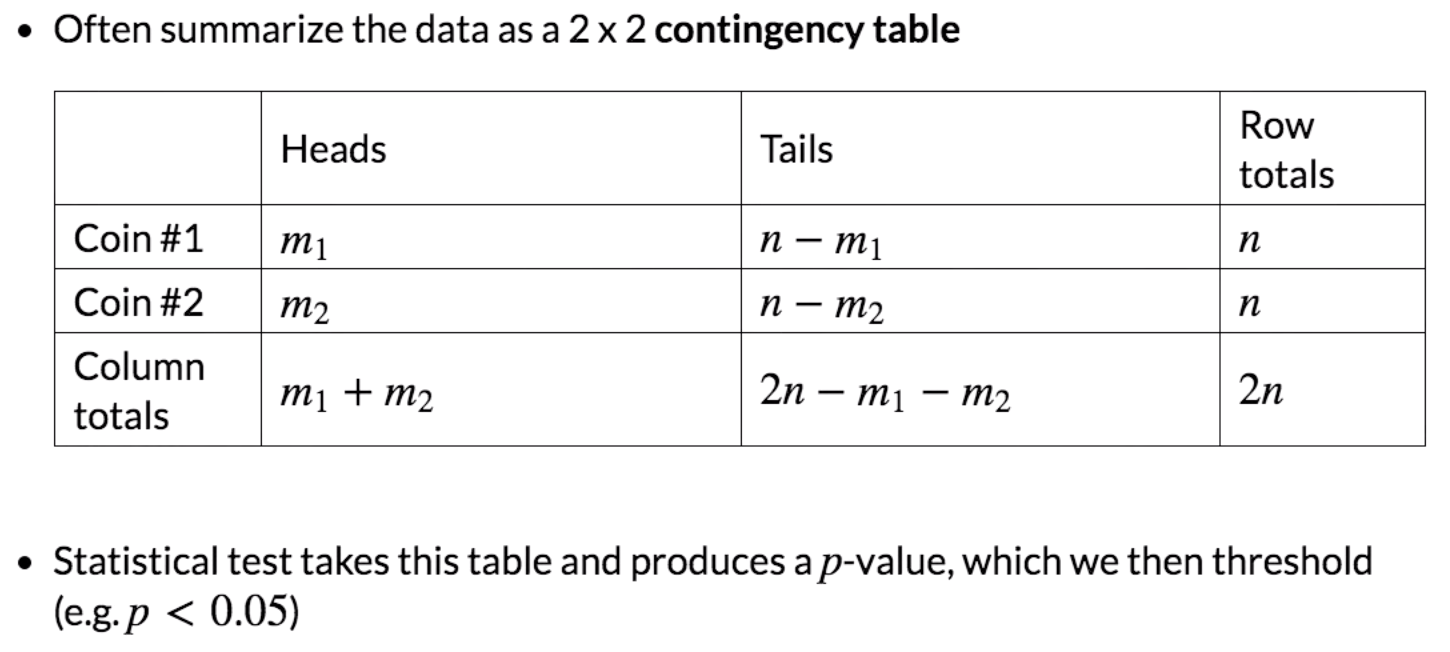



|
Actual Predicted |
T (H1) | F (H0) |
| T (H1) | TP | FP (α) |
| F (H0) | FN (β) | TN |
P = TP/(TP+FN)
R = 1-β =TP/(TP+FN)



Python Example
Case #1: Alternate hypothesis is true
n = 100
p1 = 0.4
p2 = 0.6 # Compute distributions
x = np.arange(0,n+1)
pmf1 = stats.binom.pmf(x,n,p1)
pmf2 = stats.binom.pmf(x,n,p2)
plot(x,pmf1,pmf2)
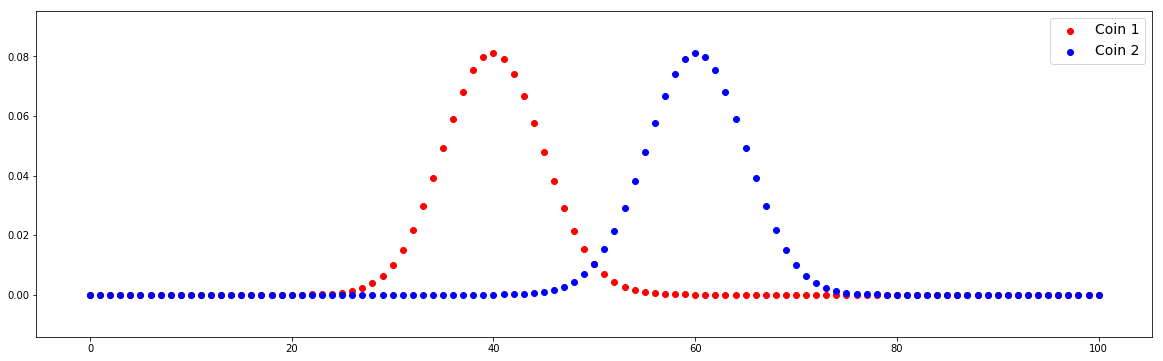
We can find that the distributions between Coin 1 and Coin 2 are different. We check different values of m1 and m2.
# Example outcomes
m1, m2 = 40, 60
table = [[m1, n-m1], [m2, n-m2]]
chi2, pval, dof, expected = stats.chi2_contingency(table)
decision = 'reject H0' if pval<0.05 else 'accept H0'
print('{} ({})'.format(pval,decision))
0.007209570764742524 (reject H0)
# Example outcomes
m1, m2 = 43, 57
table = [[m1, n-m1], [m2, n-m2]]
chi2, pval, dof, expected = stats.chi2_contingency(table)
decision = 'reject H0' if pval<0.05 else 'accept H0'
print('{} ({})'.format(pval,decision))
0.06599205505934735 (accept H0)
In the secod example, m1 and m2 are not different significantly to reject H0.
Case #2: Null hypothesis is true
n = 100
p1 = 0.5
p2 = 0.5 # Compute distributions
x = np.arange(0,n+1)
pmf1 = stats.binom.pmf(x,n,p1)
pmf2 = stats.binom.pmf(x,n,p2)
plot(x,pmf1,pmf2)
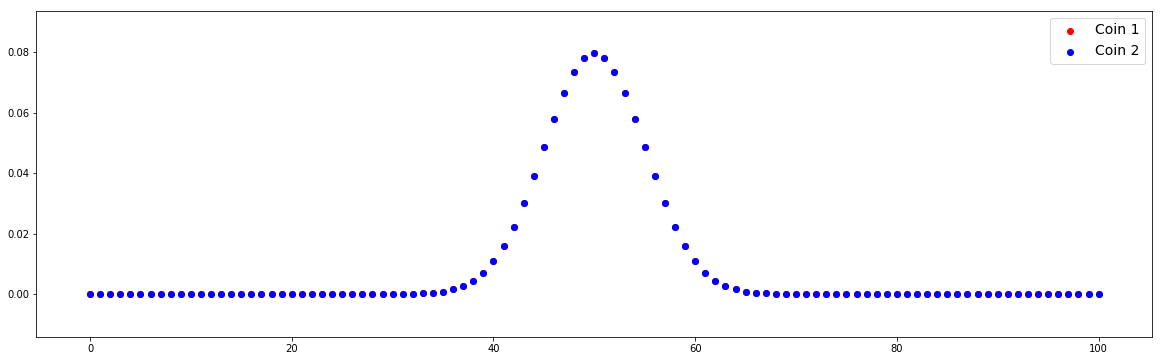
In this case, two distributions overlap because we define the same value of p1 and p2.
# Example outcomes
m1, m2 = 49, 51
table = [[m1, n-m1], [m2, n-m2]]
chi2, pval, dof, expected = stats.chi2_contingency(table)
decision = 'reject H0' if pval<0.05 else 'accept H0'
print('{} ({})'.format(pval,decision))
0.887537083981715 (accept H0)
Actuall, we can only say that m1 and m2 are not different significantly to reject H0. It doesn't mean we should accept H0. The explanation is given in the previous article.
# Example outcomes
m1, m2 = 42, 58
table = [[m1, n-m1], [m2, n-m2]]
chi2, pval, dof, expected = stats.chi2_contingency(table)
decision = 'reject H0' if pval<0.05 else 'accept H0'
print('{} ({})'.format(pval,decision))
0.033894853524689295 (reject H0)




Firstly, calculate the sample size:
p1, p2 = 0.0500, 0.0515
alpha = 0.05
beta = 0.05 # Evaluate quantile function
p_bar = (p1+p2)/2.0
za = stats.norm.ppf(1-alpha/2) # Two-sided test
zb = stats.norm.ppf(1-beta) # Compute correction factor
A = (za*np.sqrt(2*p_bar*(1-p_bar))+ zb*np.sqrt(p1*(1-p1)+p2*(1-p2)))**2 #Estimate samples required
n = A*(((1+np.sqrt(1+4*(p1-p2)/A)))/(2*(p1-p2)))**2 print (n) # we need 2n users
555118.7638311392
So for test and control combined we'll need at least 2n = 1.1 million users. This is where this stuff gets hard and you're trying to measure something that doesn't happen often which is usally the thing to care because if it's rare, it's usually valuable. When you're trying to change it, you usually can't change it much because if you can change it a lot then your business would be easier usually it's harder to change the thing you care the most about. So in that case, it's like the hardest case where a/b testing the most values are unchange.
Next we can perform a/b testing:
n = 555119
n_trials = 10000 # Simulate experimental results when null is true
control0 = stats.binom.rvs (n,p1,size = n_trials)
test0 = stats.binom.rvs(n, p1, size = n_trials) # Test and control are the same
tables0 = [[[a, n-a], [b, n-b]] for a, b in zip(control0, test0)]
results0 = [stats.chi2_contingency(T) for T in tables0]
decisions0 = [x[1] <= alpha for x in results0] # Simulate experimental results when alternate is true
control1 = stats.binom.rvs (n,p1,size = n_trials)
test1 = stats.binom.rvs(n, p2, size = n_trials) # Test and control are the same
tables1 = [[[a, n-a], [b, n-b]] for a, b in zip(control1, test1)]
results1 = [stats.chi2_contingency(T) for T in tables1]
decisions1 = [x[1] <= alpha for x in results1] # Compute false alarm and correct detection rates
alpha_est = sum(decisions0)/float(n_trials)
power_est = sum(decisions1)/float(n_trials) print('Theoretical false alarm rate = {:0.4f}, '.format(alpha)+
'empirical false alarm rate = {:0.4f}'.format(alpha_est))
print('Theoretical power = {:0.4f}, '.format(1-beta)+
'empirical power = {:0.4f}'.format(power_est))
Theoretical false alarm rate = 0.0500, empirical false alarm rate = 0.0509
Theoretical power = 0.9500, empirical power = 0.9536

A/B Testing with Practice in Python (Part One)的更多相关文章
- A/B Testing with Practice in Python (Part Two)
This is the second part of A/B testing notes, which contains the practical issues and alternatives o ...
- [Python + Unit Testing] Write Your First Python Unit Test with pytest
In this lesson you will create a new project with a virtual environment and write your first unit te ...
- Testing shell commands from Python
如何测试shell命令?最近,我遇到了一些情况,我想运行shell命令进行测试,Python称为万能胶水语言,一些自动化测试都可以完成,目前手头的工作都是用python完成的.但是无法从Python中 ...
- [The Basics of Hacking and Penetration Testing] Learn & Practice
Remember to consturct your test environment. Kali Linux & Metasploitable2 & Windows XP
- Automation Testing - Best Practice(书写规范)
Coding Standards Coding Standards are suggestions that will help us to write automation Scripts code ...
- Machine and Deep Learning with Python
Machine and Deep Learning with Python Education Tutorials and courses Supervised learning superstiti ...
- python安装locustio报错error: invalid command 'bdist_wheel'的解决方法
locust--scalable user load testing tool writen in Python(是用python写的.规模化.可扩展的测试性能的工具) 安装locustio需要的环境 ...
- Python框架、库以及软件资源汇总
转自:http://developer.51cto.com/art/201507/483510.htm 很多来自世界各地的程序员不求回报的写代码为别人造轮子.贡献代码.开发框架.开放源代码使得分散在世 ...
- Awesome Python
Awesome Python A curated list of awesome Python frameworks, libraries, software and resources. Insp ...
随机推荐
- Pascal小游戏 双人射击
一个双人的游戏 Pascal源码附上 只要俩人不脑残,一下午玩不完...又是控制台游戏中的一朵奇葩. Free Pascal 射击游戏 Program shooting_game; uses crt; ...
- jenkins调用pom.xml文件
对于测试人员来说,大部分代码维护在本地,因此在用jenkins做持续集成时,我们只需要用Jenkins去直接调用pom.xml文件去执行我们的项目 这里主要是正对创建自由风格的工程来讲解的 一.Jen ...
- Linux认知之旅【02 装个软件玩玩】!
〇.命令行终端熟悉了吗? 1.没有仔细研究上一篇文章? 拿上看看这几个命令:ls.cd.cp.mv.rm.mkdir.touch.cat.less.恩,暂时这些够用了! 什么?你连虚拟机也没装! 感谢 ...
- 【转载】Unity插件研究院之自动保存场景
原文: http://wiki.unity3d.com/index.php?title=AutoSave 最近发现Unity老有自动崩溃的BUG. 每次崩溃的时候由于项目没有保存所以Hierarch ...
- 【志银】nginx_php_mysql_phpMyAdmin配置(Windows)
✄更新中... 更新日期:2018.11.22 ★版本说明+快捷下载(官网) nginx nginx-1.14.1 http://nginx.org/download/nginx-1.14.1. ...
- 【志银】NYOJ《题目860》又见01背包
题目链接:http://acm.nyist.net/JudgeOnline/problem.php?pid=860 方法一:不用滚动数组(方法二为用滚动数组,为方法一的简化) 动态规划分析:最少要拿总 ...
- NVIDIA/DIGITS:Building DIGITS
在 Prerequisites中的 sudo apt-get update命令发生错误: W: GPG 错误:http://developer.download.nvidia.com/compute/ ...
- ubantu 系统常见问题
1 搜狗输入法错误: 删除home路径下的 .config/SouGouP...整个文件夹并重启 2 ubantu系统更新:sudo apt-get update 获取最近更新的软件包列表 ...
- React02
目录 React 进阶提升 条件渲染 受控组件* 状态提升* 组件数据流 TODO-LIST 设置服务器端口 列表渲染 条目PropTypes检查类型 export & import Refs ...
- Codeforces Round #328(Div2)
CodeForces 592A 题意:在8*8棋盘里,有黑白棋,F1选手(W棋往上-->最后至目标点:第1行)先走,F2选手(B棋往下-->最后至目标点:第8行)其次.棋子数不一定相等,F ...