读a paper of ICCV 2017 : Areas of Attention for Image Captioning
前言废话,作者说把代码公布在gitub上,但是迟迟没有公布,我发邮件询问代码情况,邮件也迟迟不回,表示很尴尬。。虽然种种这些,但是工作还是好工作,这个没的黑,那我们今天就来详细的介绍这篇文章。
导论:不了解caption的童鞋可以去看下这两篇知乎专栏:
一:摘要
作者提出了一个新的attention模型,这个模型与以往的区别在于,不仅考虑了状态与预测单词之间的关系,同时也考虑了图像区域与单词,状态之间的两两关系,好处嘛,就是信息考虑的更加全面,考虑的全面总归不是坏事啦~~。
二:baseline
这个图像生成文本的baseline,现在基本就是建立在谷歌的NIC模型上,思路是这样:用预训练好的卷积神经网络参数抽取图像特征,这个是编码部分,然后这个特征作为图像的初始状态,用RNN生成单词,这个是解码部分。示意图如下:(画的有点丑,请轻喷~~)
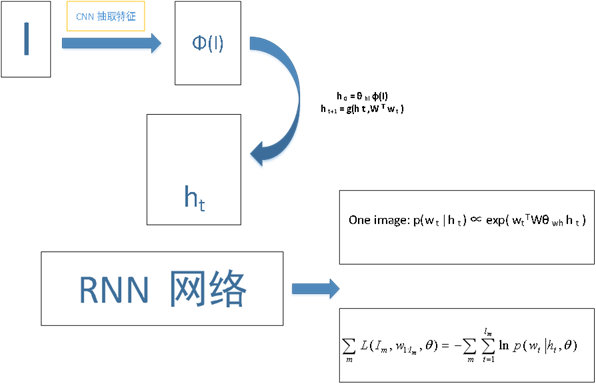
一张照片的损失函数其实就是一个logistic 回归,所有batch 那就是这些损失函数之和。 跟新状态的g 函数,一般就是用一个MLP 模型。当然RNN网络也可以换成和他功能相近的网络比如LSTM ,BLSTM 问题不大。
三:本文的损失函数
3.1 建立了一个联合概率分布: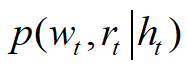
其中已经生成的单词: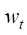
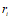 为在时刻t观察到的图像区域。
为在时刻t观察到的图像区域。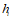 为RNN的内部状态。
为RNN的内部状态。
下面是这篇文章的精华部分,我就不妄加翻译了:

大家可以看,baseline中的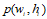 换成了
换成了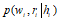 ,这就表示和图像区域扯上了关系,但是具体怎么扯上的呢,这就需要这两两之间的关系了。第一个得分是状态与生成单词之间的关系,第二个是图像区域与生成单词之间的关系,第三个是状态与图像之间的关系,这个第三个关系也就是attention所要解决的问题。后面两个我们不管他,就是个bias.
,这就表示和图像区域扯上了关系,但是具体怎么扯上的呢,这就需要这两两之间的关系了。第一个得分是状态与生成单词之间的关系,第二个是图像区域与生成单词之间的关系,第三个是状态与图像之间的关系,这个第三个关系也就是attention所要解决的问题。后面两个我们不管他,就是个bias.
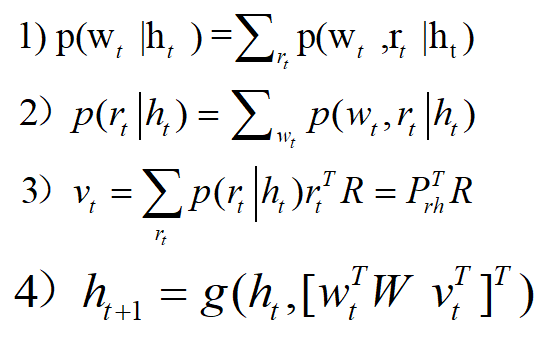
公式1,我是这样理解的,所有区域生成单词的可能性加起来就形成了在状态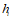 下生成单词的可能性。
下生成单词的可能性。
公式2,生成某一个单词的所有区域加起来,就是我们需要的attention 感兴趣的概率。
公式3,这就是attention的模型,状态ht下对图像某一区域感兴趣的概率。
公式4,状态更新机制,生成单词与感兴趣图像区域反馈RNN状态。
整个流程图如下:
四:Areas of attention的获取
4.1 Activiation grid:
类似于这样:

强制划分图像区域。当然这样显得有点粗糙。
4.1 object proposals
用目标检测的方法把每一个目标的给标出来,我们人为它是目标实例。

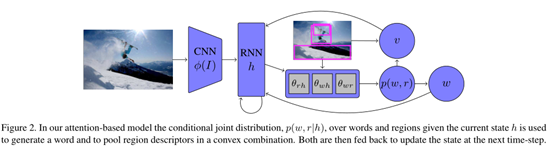
4.3 Spatial transformers
这一块说实话我认为是作者故意加篇幅的,本质上没有什么创新,简单来时是研究卷积神经网络的旋转,平移不变性,以前主要的都是通过数据增强的方法,强制去学习特征,而这个方式是加了一层trick,这样就有效的解决了这个问题。
具体的大家可以参考这篇博文:Spatial transformers
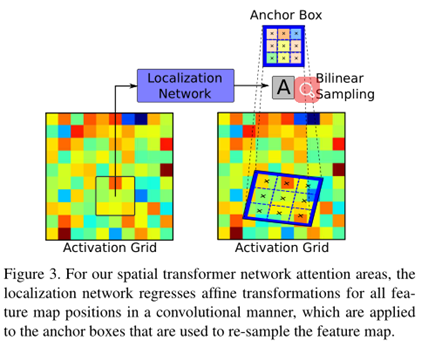
4.4 关注区域选择总结
5 总结
工作是个好工作,没代码,不开心。。。哈哈,祝大家周末愉快~~~!
读a paper of ICCV 2017 : Areas of Attention for Image Captioning的更多相关文章
- ICCV 2017论文分析(文本分析)标题词频分析 这算不算大数据 第一步:数据清洗(删除作者和无用的页码)
IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017. IEE ...
- ICCV 2017 Best Paper Awards
[ICCV 2017 Best Paper Awards]今年的ICCV不久前公布了Best Paper得主,來自Facebook AI Research的Mask R-CNN[1],與RetineN ...
- 复现ICCV 2017经典论文—PyraNet
. 过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”.这是今年 AAAI 会议上一个严峻的 ...
- 论文:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结 笔记不能简单的抄写文中 ...
- 应读的paper
1.Faster R-CNN:https://arxiv.org/abs/1506.01497(已读) 2.FPN(Feature Pyramid Networks for Object Detect ...
- 卷积网络可解释性复现 | Grad-CAM | ICCV | 2017
觉得本文不错的可以点个赞.有问题联系作者微信cyx645016617,之后主要转战公众号,不在博客园和CSDN更新. 论文名称:"Grad-CAM: Visual Explanations ...
- 《Stepwise Metric Promotion for Unsupervised Video Person Re-identification》 ICCV 2017
Motivation: 这是ICCV 17年做无监督视频ReID的一篇文章.这篇文章简单来说基于两个Motivation. 在不同地方或者同一地方间隔较长时间得到的tracklet往往包含的人物是不同 ...
- Genetic CNN: 经典NAS算法,遗传算法的标准套用 | ICCV 2017
论文将标准的遗传算法应用到神经网络结构搜索中,首先对网络进行编码表示,然后进行遗传操作,整体方法十分简洁,搜索空间设计的十分简单,基本相当于只搜索节点间的连接方式,但是效果还是挺不错的,十分值得学习 ...
- [ Continuously Update ] The Paper List of Seq2Seq Tasks ( including Attention Mechanism )
Papers Published in 2017 Convolutional Sequence to Sequence Learning - Jonas Gehring et al., CoRR 20 ...
随机推荐
- 网络编程 TCP学习
上传txt文本 通过socket向服务端发送数据 然后用serversocket 接收socket 通过流读取数据保存 服务端在发送确认信息并在client输出 client import java. ...
- .aspx 页面引用命名空间
一.单个页面引用: <%@ Import Namespace="" %> 二.所有页面引用,Web.config配置如下: <system.web> < ...
- js获取时间查并实现倒计时读条
<script type="text/javascript"> $().ready(function () {// 每增加一个切换,就要增加一行,tab1不变,其他的都 ...
- nightwatch-js -- test group
Test group 可以将你的测试脚本划分到组中,并根据需要运行它们.要将测试组合在一起,只需将它们放在相同的子文件夹中,文件夹的名字即是组的名字.例如:lib/├── selenium-serve ...
- 安装java运行环境
1.查看java安装版本 执行命令java -version查看已安装java运行环境信息. 2.下载JDK 到sun官网下载需要的jdk版本,地址为:http://www.oracle.com/te ...
- C#:异步编程和线程的使用(.NET 4.5 ),异步方法改为同步执行
摘自:http://www.codeproject.com/Articles/996857/Asynchronous-programming-and-Threading-in-Csharp-N(葡萄城 ...
- MyEclipse配置输出控制台信息至文本文件里
有时会遇到这种情况.输出的信息过多,console控制台显示不全然.这是就须要将输出的信息输出到文本文件里,既能够查看也能够备份. 1.右击须要执行的项目->Run As->Run Con ...
- Element type "Resource" must be followed by either attribute specifications, ">" or "/>".
在xml中配置没有问题的情况下.检查是否有单词中间缺少 空格 .2个单词靠的太近的情况! 试了一下情况解决!
- 开发中可能会用到的几个小tip----QT, pycharm, android, 等
QT: 如果是在windows下开发的话,添加外部库,外部包含头文件路径的时候,要注意用相对路径,或者在项目上右键添加外部库的路径或者头文件路径,否则,会卡在这里开始怀疑人生... 如果是在linux ...
- lua学习笔记(八)
元表与元方法 基本概念 1.lua中每个值都有一个元表 2.table和userdata可以有各自独立的元表 3.其它类型的值共享其类型所属的单一 ...