强大的开源网络侦查工具:IVRE
IVRE简介
IVRE(又名DRUNK)是一款开源的网络侦查框架工具,IVRE使用Nmap、Zmap进行主动网络探测、使用Bro、P0f等进行网络流量被动分析,探测结果存入数据库中,方便数据的查询、分类汇总统计。
网上已有部分文章对IVRE的使用做介绍,由于文章时间较早,IVRE的安装、命令执行等均有所改变,本文使用最新版IVRE做讲解,并增加部分其它文章未提及的Nmap模板参数设置、Web界面搜索使用等内容。
IVRE官方网站:https://ivre.rocks
GitHub:https://github.com/cea-sec/ivre
IVRE安装
使用Docker方式安装
$ mkdir ivre
$ cd ivre
//拉取Docker镜像
$ mkdir -m 1777 var_{lib,log}_{mongodb,neo4j} ivre-share
$ wget -q https://ivre.rocks/Vagrantfile
//启动Docker
$ vagrant up --no-parallel
//进入Docker - ivreclient shell
$ docker exec -it ivreclient bash
root@e809cb41cb9a:/#
//查看ivre命令帮助
root@e809cb41cb9a:/#ivre --help
安装脚本会在ivre目录中创建几个新的文件夹,这些文件夹用于挂载到Docker容器中存放数据库等信息。ivre-share会挂载容器ivreclient的根目录下,之后的扫描操作我们也在这个目录下执行,方便主机和容器间的文件交互。
数据库初始化
第一次使用时,对4个数据库进行初始化操作(使用过程中,如需完全重新导入数据,也要对相应数据库做初始化设置):
$ ivre scancli --init
$ ivre ipinfo --init
$ ivre ipdata --init
$ ivre runscansagentdb --init
获取IP位置数据
ipdata数据包含了IP对应的地理位置信息。
$ ivre ipdata --download
$ ivre ipdata --import-all --no-update-passive-db
安装缺失Python模块
执行ivre命令后,提示部分Python模块缺失,下面进行这部分模块的安装:
apt-get update
apt-get install python-pip
//Python module PIL: 4.3.0: missing
pip install Pillow
//Python module krbV: missing
apt-get install libkrb5-dev
pip install python-krbv
//Python module MySQLdb: missing
apt-get install python-mysqldb
//安装VIM,方便编辑文件
apt-get install vim
IVRE使用
被动侦查
IVRE可以使用Bro和p0f对流量分析,并将结果导入到数据库中。
个人感觉网络流量分析这部分,IVRE所能提供的功能并不实用,略过,感兴趣的同学,请参考官方文档。
需对流量实时或回放分析,Windows平台下推荐使用成都本土科技公司科来的科来网络分析系统,技术交流版免费使用。
Flow analysis
网络数据流的图形展示,这个比较炫酷,简单介绍下。先在主机上使用Wireshark抓一段时间包,数据包保存为pcap格式,命名为test.pcap,放入IVRE的共享文件夹ivre-share中,执行命令处理数据包:
$ cd /ivre-share
//使用Bro对数据包进行处理,完成后再当前文件夹生成.log文件
$ bro -r test.cap
//初始化flowcli数据库
$ ivre flowcli --init
//将.log文件导入数据库
$ ivre bro2db *.log
查看导入的流量统计数据
$ ivre flowcli --count
585 clients
1259 servers
3629 flows
打开浏览器,输入http://your-host-ip/flow.html 查看网络流量动画。
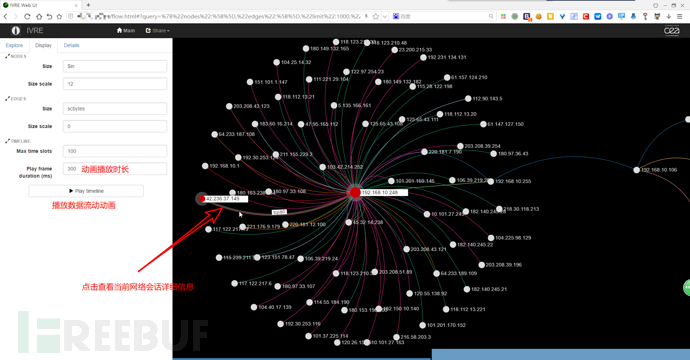
主动侦查
主动侦查部分是重点介绍的内容,通常环境下,企业内网环境的网络流量不可能完全经过安全测试服务器,需要了解内网全部服务器的端口、服务情况,需要使用Nmap、Masscan等工具进行主动探测扫描。
使用Nmap扫描
随机扫描1000个IP
进入Docker – ivreclient shell后,执行:
$ cd /ivre-share
$ ivre runscans --routable --limit 1000 --country CN --output=XMLFork
这条命令会执行一个随机扫描,扫描1000个中国地区的IP,默认开启30个Nmap并行进程。使用ivre help runscans查看扫描相关的详细帮助内容。扫描后在/ivre-share目录下生成扫描结果文件,包含端口开放、服务信息、网页截图等。
扫描后清理缓存文件:
rm -fr /ivre-share/scans/COUNTRY-CN/ current/
导**入扫描结果**
扫描完成后,将扫描结果导入数据库:
$ cd /ivre-share
$ ivre scan2db -c ROUTABLE-CN-001 -s Parrot -r /ivre-share/scans/COUNTRY-CN/up/
这里 ROUTABLE-CN-001 是这次扫描结果的分类名称,MySource是扫描来源名称,方便指挥对扫描结果的分类搜索。
除了在本地执行扫描工作外,IVRE还可以设置多个扫描在代理服务器,在主服务器上执行ivre {runscansagent|runscansagentdb}命令进行代理服务器的扫描任务下发和结果导入。
命令执行后提示xxx results imported,则导入成功。
指定扫描IP目标
通过ivre help runscans命令查看IVRE的帮助文档,找到两个指定扫描IP的参数,--range和--network,--range指定扫描IP的起止范围,--network参数可指定一个网段。例:
$ ivre runscans --network 45.32.14.0/24 --output=XMLFork
使用--output=CommandLine 参数来看下当前执行的完整命令:
root@67d2aa11797f:/ivre-share# ivre runscans --network 45.32.14.0/24 --output CommandLine
Command line to run a scan with template default
nmap -A -PS -PE -sS -vv --host-timeout 15m --script-timeout 2m --script '(default or discovery or auth) and not (broadcast or brute or dos or exploit or external or fuzzer or intrusive)'
使用Nmap模板扫描
--nmap-template参数可指定Nmap扫描模板,在/etc/ivre.conf中添加模板。
Nmap模板参考:
vi /etc/ivre.conf
//创建一个扫描1-65535端口,名称为`full-port`的Nmap扫描模板,在文件中添加以下内容(复制default模板并修改部分参数)
NMAP_SCAN_TEMPLATES["full-ports"] = NMAP_SCAN_TEMPLATES["default"].copy()
NMAP_SCAN_TEMPLATES["full-ports"]["ports"] = "1-65535"
NMAP_SCAN_TEMPLATES["full-ports"]["scripts_categories"] = ['(default or discovery or auth) and not (broadcast or brute or dos or exploit or external or fuzzer or intrusive)']
NMAP_SCAN_TEMPLATES["full-ports"]["scripts_exclude"] = []
添加模板参数后后再看看扫描命令:
root@67d2aa11797f:/ivre-share# ivre runscans --network 45.32.14.0/24 --output CommandLine --nmap-template full-port
Command line to run a scan with template full-port
nmap -A -PS -PE -sS -vv -p 1-65535 --host-timeout 15m --script-timeout 2m --script '(default or discovery or auth) and not (broadcast or brute or dos or exploit or external or fuzzer or intrusive)'
相比之前的命令,增加了-p 1-65535参数,执行全端口扫描。
模板中可以设置的其它参数,我在网上没找到详细的官方介绍文档,可以在IVRE的python文件中查找:/usr/local/lib/python2.7/dist-packages/ivre/nmapopt.py通过模板,你可以定制你的特定扫描需求。
扫描结果使用
执行扫描并导入数据库后,有三种方式使用这些内容:
- ivre scancli命令行工具
- Python模块ivre.db
- IVRE Web界面
CLI: ivre scancli
例:使用命令行查看所有开放了22端口的主机:
$ ivre scancli --port 22
See the output of .
使用ivre help scancli查看详细的帮助信息。
Python 模块
例:
$ python
>>> from ivre.db import db
>>> db.nmap.get(db.nmap.flt_empty)[0]
在Python shell执行help(db.nmap)查看模块的帮助信息。
Web界面
浏览器输入 http://your-host-ip 访问IVRE Web界面,
IVRE WEB界面
IVRE提供了WEB界面方便直观的展示主动扫描(Nmap)结果,通过关键字过滤搜索你需要的内容。
网页菜单栏点击HTLP,可以查看搜索过滤的帮助信息,其它菜单项则是在过滤器中快速添加过滤条件。左侧显示RESULTS、FILTER、EXPLORE三部分内容、
RESULTS:当前过滤规则的结果总数、显示页面控制
FILTER:过滤规则,可以填写服务过滤、结果排序、页面展示内容三类规则,可以多个规则组合使用
- 一些常用的过滤示例:
- country:CN //过滤国家为中国
- city:Chengdu //过滤城市为成都
- openport //列出至少开放1个端口的IP
- otheropenport:22 //开放22端口
- service:telnet //开放Telnet服务
- !host:218.205.252.70 //不显示218.205.252.70,部分参数前面加!表示否定
- display:screenshot //结果中显示截图
- EXPLORE:将当前的过滤结果生成图形化展示
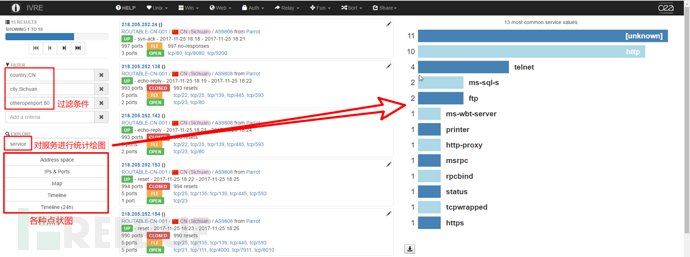
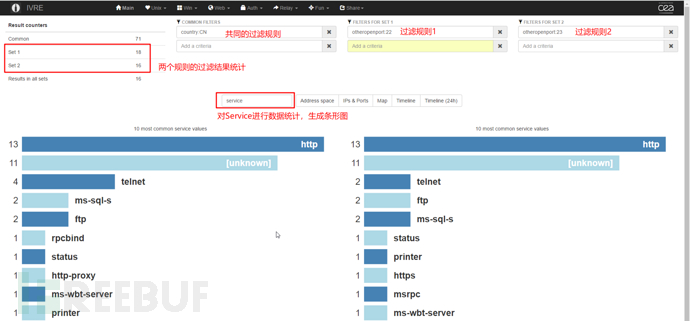
Compare Graphs
菜单栏Share→Compare Graphs,图形比较页面,可以设定两个不同的过滤规则,统计过滤后的数据,指定需统计的内容如服务(service)、端口(port)或产品(product)等,生成两组作比较的条形图。
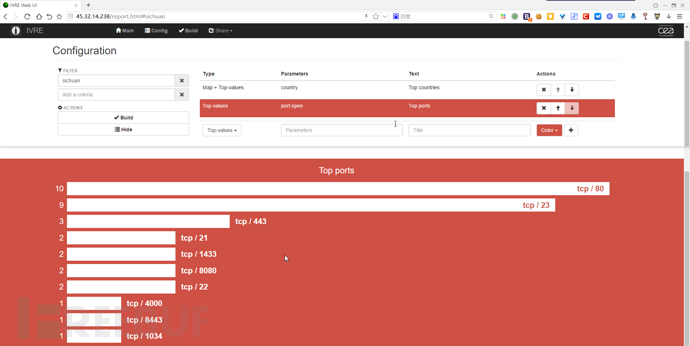
Report
菜单栏Share→Report,进入Report页面,对开发端口、服务、IP地区等进行Top 10统计,生成条形图,需要写统计报告的同学,这个功能比较实用。
结语
在复杂的企业内网,定期使用IVRE对内网的端口扫描探测并保存结果,便于安全工作人员及时掌握内网的服务开放、是否存在弱口令等情况。
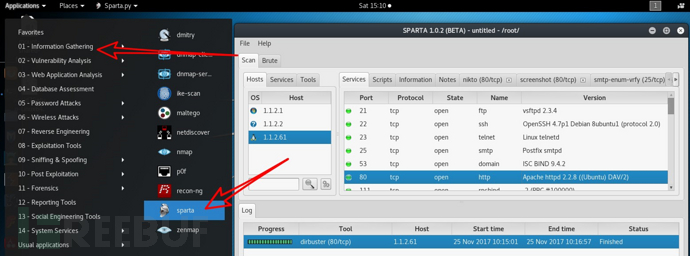
日常的渗透测试工作中,小规模的IP扫描,建议使用另一款工具——斯巴达(SPARTA,Kali自带,Github链接),输入IP,自动进行Nmap扫描,根据服务探测结果调用相关工具(如Hydra、Dibuster等)进行下一步的测试。
强大的开源网络侦查工具:IVRE的更多相关文章
- [推荐] 网络侦查工具 NMAP 简单入门
[推荐] 网络侦查工具 NMAP 简单入门 # 前言 作为一只运维开发,总是避不开要和网络打交道的.尤其是当自身能力到达瓶颈,开始从事云计算以求突破.会有搭建多台虚拟机的需要,这时候如果在手工的查询 ...
- Android强大的开源库与系统架构工具
后来加上的,因为太强大了,android上百个可立即使用的开源库介绍:https://github.com/Trinea/android-open-project 一款功能强大且实用的开发工具可以为开 ...
- Android 开源项目android-open-project工具库解析之(一) 依赖注入,图片缓存,网络相关,数据库orm工具包,Android公共库
一.依赖注入DI 通过依赖注入降低View.服务.资源简化初始化.事件绑定等反复繁琐工作 AndroidAnnotations(Code Diet) android高速开发框架 项目地址:https: ...
- 10 个强大的开源 Web 流量分析工具(转帖)
Web 流量分析工具多不胜数,从 WebTrends 这样专业而昂贵的,到 Google Analytics 这样强大而免费的,从需要在服务器端单独部署的,到可以从前端集成的,不一而足.本文收集并介绍 ...
- Android开源项目发现--- 工具类网络相关篇(持续更新)
1. Asynchronous Http Client for Android Android异步Http请求 项目地址:https://github.com/loopj/android-async- ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 12个强大的Web服务测试工具
在过去的几年中,web服务或API的普及和使用有所增加. web服务或API是程序或软件组件的集合,可以帮助应用程序进行交互或通过形成其他应用程序或服务器之间的连接执行一些进程/事务处理.基本上有两种 ...
- 微软开源自动机器学习工具NNI安装与使用
微软开源自动机器学习工具 – NNI安装与使用 在机器学习建模时,除了准备数据,最耗时耗力的就是尝试各种超参组合,找到最佳模型的过程了.对于初学者来说,常常是无从下手.即使是对于有经验的算法工程师 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
随机推荐
- 1512 Monkey King
Monkey King Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tota ...
- 详解Python中的相对导入和绝对导入
Python 相对导入与绝对导入,这两个概念是相对于包内导入而言的.包内导入即是包内的模块导入包内部的模块. Python import 的搜索路径 在当前目录下搜索该模块 在环境变量 PYTHONP ...
- [转] 重定向 CORS 跨域请求
非简单请求不可重定向,包括第一个preflight请求和第二个真正的请求都不行. 简单请求可以重定向任意多次,但如需兼容多数浏览器,只可进行一次重定向. 中间服务器应当同样配置相关 CORS 响应头. ...
- pycharm安装包
pycharm的纯净版本 链接: https://pan.baidu.com/s/15fLsO_GCO8uaYNQjLVdNaw 密码: ef22
- 大数据学习——sparkSql对接mysql
1上传jar 2 加载驱动包 [root@mini1 bin]# ./spark-shell --master spark://mini1:7077 --jars mysql-connector-j ...
- Leetcode 447.回旋镖的数量
回旋镖的数量 给定平面上 n 对不同的点,"回旋镖" 是由点表示的元组 (i, j, k) ,其中 i 和 j 之间的距离和 i 和 k 之间的距离相等(需要考虑元组的顺序). 找 ...
- 【java基础 13】两种方法判断hashmap中是否形成环形链表
导读:额,我介绍的这两种方法,有点蠢啊,小打小闹的那种,后来我查了查资料,别人都起了好高大上的名字,不过,本篇博客,我还是用何下下的风格来写.两种方法,一种是丢手绢法,另外一种,是迷路法. 这两种方法 ...
- DS博客作业06—图
1.本周学习总结 1.1思维导图 1.2学习体会 2.PTA实验作业 2.1 图着色问题 图着色问题是一个著名的NP完全问题.给定无向图G=(V,E),问可否用K种颜色为V中的每一个顶点分配一种颜色, ...
- hdu6074[并查集+LCA+思维] 2017多校4
看了标答感觉思路清晰了许多,用并查集来维护全联通块的点数和边权和. 用另一个up[]数组(也是并查集)来保证每条边不会被重复附权值,这样我们只要将询问按权值从小到大排序,一定能的到最小的边权和与联通块 ...
- PHP服务接口测试
最近百度Hi项目拟针对内部员工版本增加设备绑定功能,也许是公司出于对员工聊天信息安全性的考虑,同时也考虑到后期会有相应的员工名片等功能的推出,设备绑定的过程也是为了员工名片功能做个准备吧!设备绑定的服 ...