Python爬虫作业
题目如下:
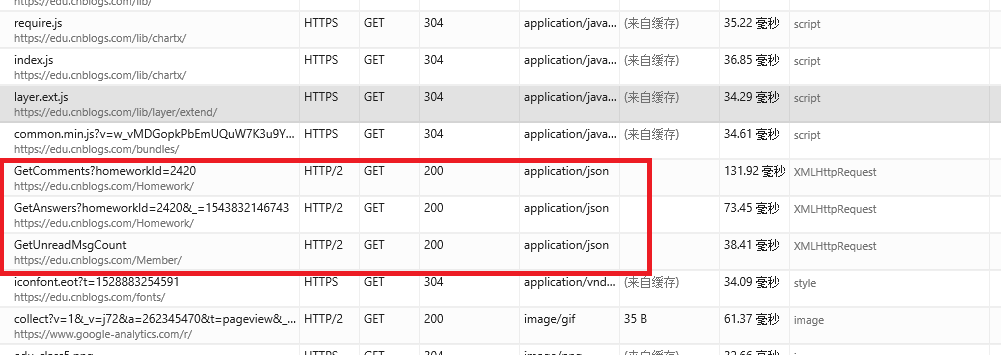

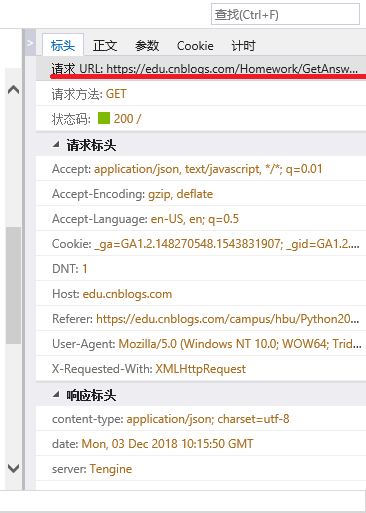
import requests as r
import json
url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543832146743"
try:
myhead = {'user-agent':'Mozilla/5.0'}
wb = r.get(url,headers=myhead,timeout=100)
wb.raise_for_status() #状态码不为200,引发HTttpERROR异常
wb.encoding = wb.apparent_encoding
key1 = wb.text
except:
print ("ERROR!")
#json.load返回字典类型,获取data索引后的信息,即目标json信息
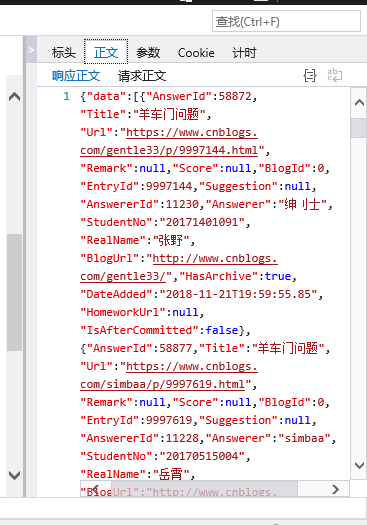
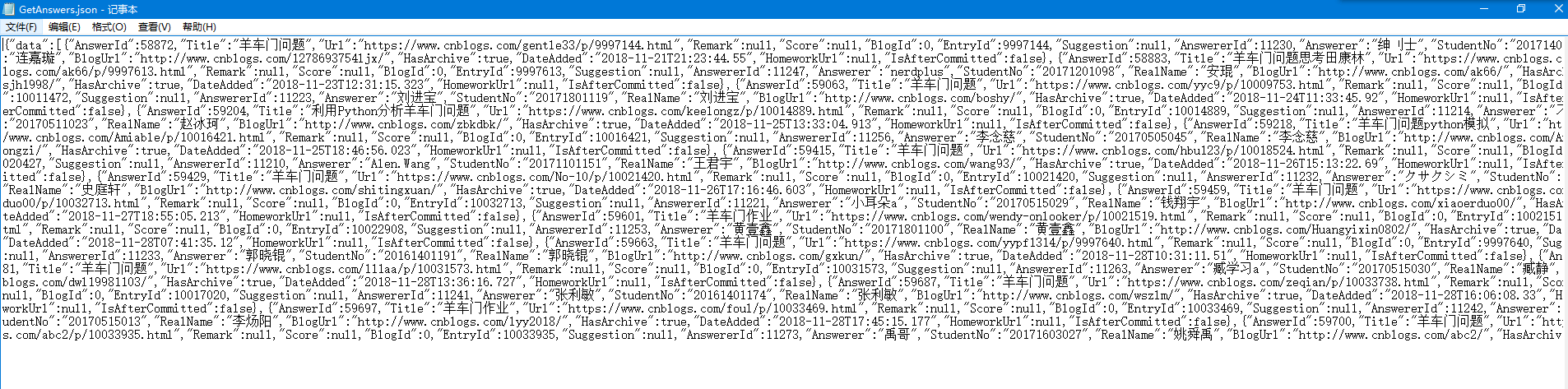
json1=json.loads(key1)['data']
#现在json1是列表了,开始逐行取信息,写到文件中
#注意学号用字符串保存,否则在excel中会按数字处理,即用科学计数法表示
#提交时间中,日期和时间中有个‘T’,用replace替换掉
keydata=' '
with open('hwlist.csv','w') as keyfile:
for index in json1:
keyfile.write(str(index['StudentNo'])+','+index['RealName']+','+index['DateAdded'].replace('T',' ')+','+index['Title']+','+index['Url']+'\n')
#有毒,明明IDE上缩进是对的
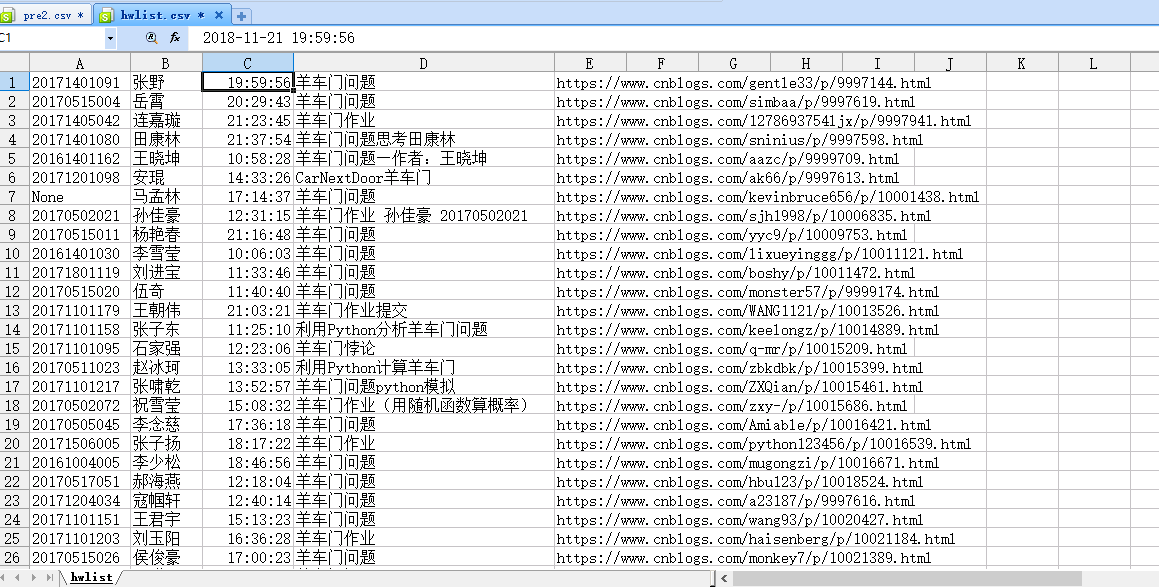
hwlist.csv打开后如下:好像是我excel设置的问题,日期无法好好显示,不过看单元格值应该是正确的
附:
其实上面的方法并不是我的本意…
我一开始看到目标文件是csv,就想到了解析大数据的神器——panda库。
panda库里的read_json可以把json字符串文件解析为panda自带的数据类型——Series或者Dataframe(直观的看上去就是一维数组与二维数组)
然后利用to_csv可以直接实现把数据转为csv文件格式。(当然也有to_txt,to_excel等等,很强大的库)
先看下我的代码:
import requests as r
import json
import pandas as pd
url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543832146743"
keyweb = r.get(url)
json1= json.loads(keyweb.text)['data']
keyjson = json.dumps(json1)
keytable = pd.read_json(keyjson)
#keytable.to_csv('pre1.csv')
keytable.to_csv('pre2.csv',columns=['StudentNo', 'RealName','Title','DateAdded','Url'],index=False,header=True)
处理源数据的手法都类似。不同的是,我们处理完json数据之后。再用json.dumps把处理好的数据转回为json字符串格式。
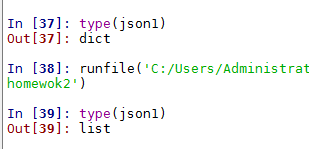
然后调用panda库的read_json方法,把这个json字符串转为panda库的dataframe格式。
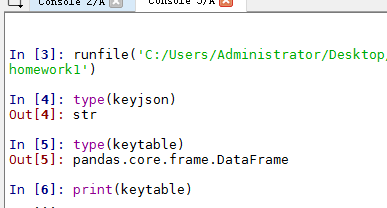
可以type一下,一目了然。
看上去万事俱备了,我们直接to_csv一波。
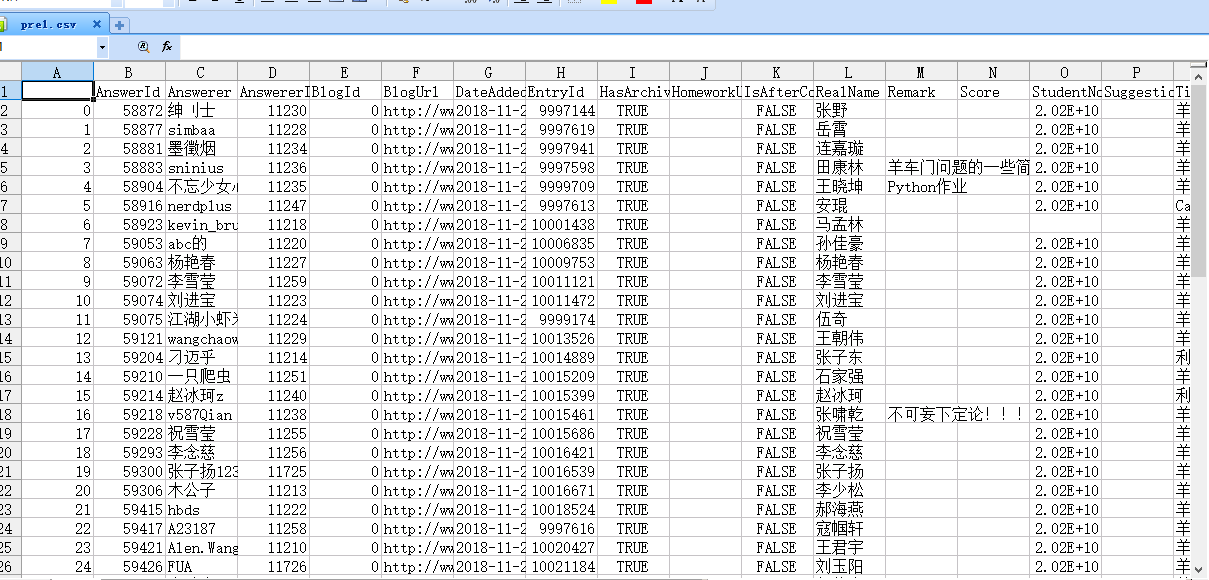
keytable.to_csv('pre1.csv')
问题出现了:是解析成了一个csv表不错,但是好多列都是我们不需要的。(包括莫名其妙的索引)
还好,to_csv方法给我们提供了参数来解决这些问题。
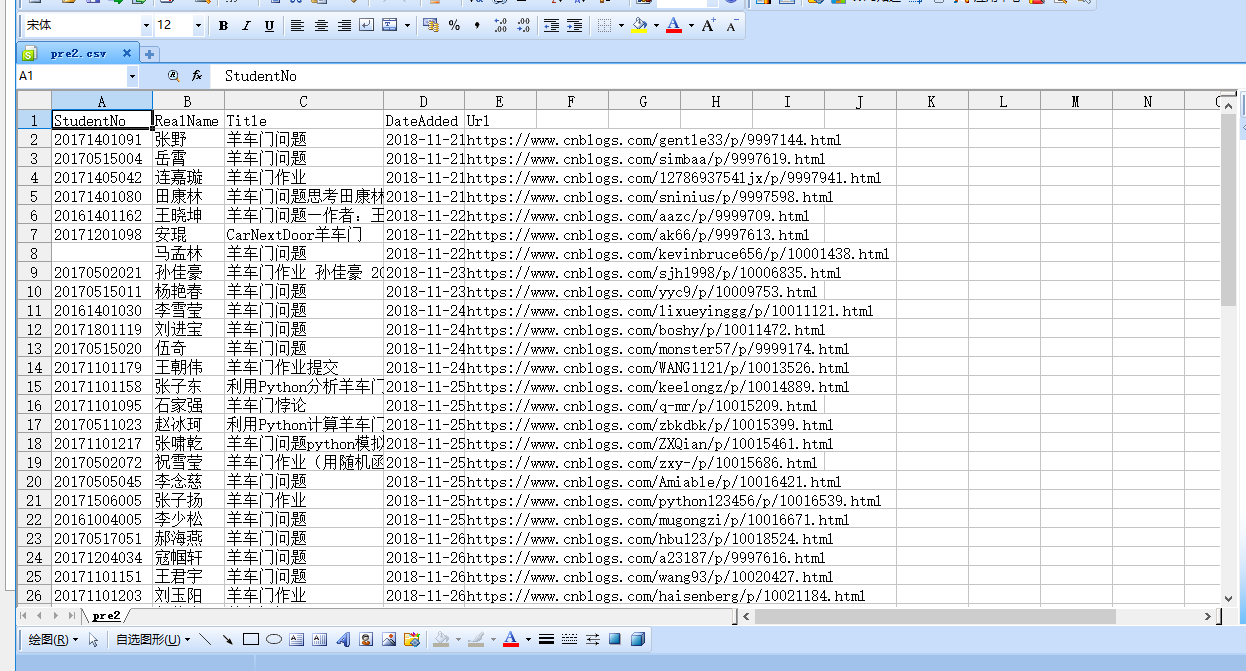
keytable.to_csv('pre2.csv',columns=['StudentNo', 'RealName','Title','DateAdded','Url'],index=False,header=True)
columns=['1’,'2'…]:只保留某些列的内容,这里我们保存学号,姓名,标题,提交时间,网址这些列
index=False:不写默认是true,会在第一列添加一列索引。且默认从0开始,我们用excel浏览,不太需要。X掉。
header=True:保留表头,位置在全表第一行。不写默认是true.
于是处理后的pre2.csv如下:
看上去问题解决了?不然:
我在其中遇到最大的问题就是:提交时间中那个“T”到底怎么处理掉?
有一位仁兄也用的panda库完成的作业,我参考了一下:是先把json数据处理好后,用panda库的DataFrame()将其转换成dataframe格式,并用colums给每个列命名,之后再用to_csv解析成csv格式。
这不失为一种很好的解决方案。
那么,可以不可以对我这种“暴力”转换的dataframe格式中的数据直接进行查值替换这类的操作呢?
研究了半天,最后也没有解决,可能是对panda库操作还是太少。希望有人能指点一下,不胜感激。
总结:
爬虫对我来说并不新鲜,但我却一直没有多加应用。
爬虫并不是get个url,直接.text这么简单的。
对于requests库的掌握都有些生疏。更不要提bs4和re这些了,对于信安专业的学生,不客气的说,这是不可原谅的。
努力弥补吧。
Python爬虫作业的更多相关文章
- 【Python】:简单爬虫作业
使用Python编写的图片爬虫作业: #coding=utf-8 import urllib import re def getPage(url): #urllib.urlopen(url[, dat ...
- Python爬虫之12306-分析请求总概述
python爬虫也学了一段时间了.也爬过不少网站,最后我想用12306抢票器这个项目做一个对之前的学习的效果成见也是一个目标(开始学爬虫的时候,看到说,会爬12306,就会爬80%的网站),本人纯自学 ...
- 路飞学城Python爬虫课第一章笔记
前言 原创文章,转载引用务必注明链接.水平有限,如有疏漏,欢迎指正. 之前看阮一峰的博客文章,介绍到路飞学城爬虫课程限免,看了眼内容还不错,就兴冲冲报了名,99块钱满足以下条件会返还并送书送视频. 缴 ...
- 从零起步 系统入门Python爬虫工程师 ✌✌
从零起步 系统入门Python爬虫工程师 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 大数据时代,python爬虫工程师人才猛增,本课程专为爬虫工程师打造, ...
- 路飞学城-Python爬虫集训-第三章
这个爬虫集训课第三章的作业讲得是Scrapy 课程主要是使用Scrapy + Redis实现分布式爬虫 惯例贴一下作业: Python爬虫可以使用Requests库来进行简单爬虫的编写,但是Reque ...
- 风变编程笔记(二)-Python爬虫精进
第0关 认识爬虫 1. 浏览器的工作原理首先,我们在浏览器输入网址(也可以叫URL),然后浏览器向服务器传达了我们想访问某个网页的需求,这个过程就叫做[请求]紧接着,服务器把你想要的网站数据发送给浏 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
随机推荐
- Html+css实现带图标的控件
</pre><pre name="code" class="html"><!DOCTYPE html> <html l ...
- Api容器在应用架构演化中的用途
单层架构 在最开始编程的时候相信大家都写过下面这种架构,界面代码,业务代码,数据库连接全部在工程面完成.当然这种架构在处理很小的程序的时候依然有生命力 两层架构 后来我们发现数据访问的代码大量重复,应 ...
- Head First HTML与CSS阅读笔记(一)
之前写过不少前端界面,但是没有完整阅读过一本HTML与CSS的书籍,都是用到什么查什么,最近闲暇之余想巩固加深一下前端基础方面的知识,阅读了<Head First HTML与CSS>,感觉 ...
- JSP开发过程遇到的中文乱码问题及解决方案
对于程序猿来说,乱码问题真的很头疼,下面列举几种常见的乱码. 1.数据库编码不一致导致乱码 解决方法: 首先查看数据库编码,输入: show variables like "%char%&q ...
- 知名nodeJS框架Express作者宣布弃nodeJS投Go
知名 nodeJS 框架 Express 的作者 TJ Holowaychuk 在 Twitter 发推并链接了自己的一篇文章,宣布弃 nodeJS 投 Go. 他给出的理由是:Go 语言和 Rust ...
- CUDA:Supercomputing for the Masses (用于大量数据的超级计算)-第九节
原文链接 第九节:使用CUDA拓展高等级语言 Rob Farber 是西北太平洋国家实验室(Pacific Northwest National Laboratory)的高级科研人员.他在多个国家级的 ...
- sudo apt-get install ubuntu-desktop, Error: unable to locate package
http://askubuntu.com/questions/130532/sudo-apt-get-install-ubuntu-desktop-error-unable-to-locate-pac ...
- JT∕T 905 -2014 出租汽车服务管理信息系统的相关协议研究
出租汽车服务管理信息系统(JT∕T 905 -2014) 国家的相关技术要求2014年7月正式出台,总体有四部分, 第 1 部分:总体技术要求: 第 2 部分:运营专用设备: 第 3 部分 ...
- c++ 循环程序的作业,2017年10月10日作业题。
作业1: 需求:输出一个由 * 符号所组成的矩形,要求每行有50个 * ,一共需要有60行.使用双重for循环完成. 作业2: 需求:输出一个由 * 符号所组成的三角形,要求第一行一个 * ,第二行 ...
- 【前端_js】理解 JavaScript 的 async/await
async 和 await 在干什么 任意一个名称都是有意义的,先从字面意思来理解.async 是“异步”的简写,而 await 可以认为是 async wait 的简写.所以应该很好理解 async ...