将连续增长 N 次字符串所需的内存重分配次数从必定 N 次降低为最多 N 次 二进制安全
SDS 与 C 字符串的区别 — Redis 设计与实现 http://redisbook.com/preview/sds/different_between_sds_and_c_string.html
SDS 与 C 字符串的区别
根据传统, C 语言使用长度为 N+1 的字符数组来表示长度为 N 的字符串, 并且字符数组的最后一个元素总是空字符 '\0' 。
比如说, 图 2-3 就展示了一个值为 "Redis" 的 C 字符串:

C 语言使用的这种简单的字符串表示方式, 并不能满足 Redis 对字符串在安全性、效率、以及功能方面的要求, 本节接下来的内容将详细对比 C 字符串和 SDS 之间的区别, 并说明 SDS 比 C 字符串更适用于 Redis 的原因。
常数复杂度获取字符串长度
因为 C 字符串并不记录自身的长度信息, 所以为了获取一个 C 字符串的长度, 程序必须遍历整个字符串, 对遇到的每个字符进行计数, 直到遇到代表字符串结尾的空字符为止, 这个操作的复杂度为 O(N) 。
举个例子, 图 2-4 展示了程序计算一个 C 字符串长度的过程。






和 C 字符串不同, 因为 SDS 在 len 属性中记录了 SDS 本身的长度, 所以获取一个 SDS 长度的复杂度仅为 O(1) 。
举个例子, 对于图 2-5 所示的 SDS 来说, 程序只要访问 SDS 的 len 属性, 就可以立即知道 SDS 的长度为 5 字节:

又比如说, 对于图 2-6 展示的 SDS 来说, 程序只要访问 SDS 的 len 属性, 就可以立即知道 SDS 的长度为 11 字节。

设置和更新 SDS 长度的工作是由 SDS 的 API 在执行时自动完成的, 使用 SDS 无须进行任何手动修改长度的工作。
通过使用 SDS 而不是 C 字符串, Redis 将获取字符串长度所需的复杂度从 O(N) 降低到了 O(1) , 这确保了获取字符串长度的工作不会成为 Redis 的性能瓶颈。
比如说, 因为字符串键在底层使用 SDS 来实现, 所以即使我们对一个非常长的字符串键反复执行 STRLEN 命令, 也不会对系统性能造成任何影响, 因为 STRLEN 命令的复杂度仅为 O(1) 。
杜绝缓冲区溢出
除了获取字符串长度的复杂度高之外, C 字符串不记录自身长度带来的另一个问题是容易造成缓冲区溢出(buffer overflow)。
举个例子, <string.h>/strcat 函数可以将 src 字符串中的内容拼接到 dest 字符串的末尾:
char *strcat(char *dest, const char *src);
因为 C 字符串不记录自身的长度, 所以 strcat 假定用户在执行这个函数时, 已经为 dest 分配了足够多的内存, 可以容纳 src 字符串中的所有内容, 而一旦这个假定不成立时, 就会产生缓冲区溢出。
举个例子, 假设程序里有两个在内存中紧邻着的 C 字符串 s1 和 s2 , 其中 s1 保存了字符串 "Redis" , 而 s2 则保存了字符串 "MongoDB" , 如图 2-7 所示。

如果一个程序员决定通过执行:
strcat(s1, " Cluster");
将 s1 的内容修改为 "Redis Cluster" , 但粗心的他却忘了在执行 strcat 之前为 s1 分配足够的空间, 那么在 strcat 函数执行之后, s1 的数据将溢出到 s2 所在的空间中, 导致 s2 保存的内容被意外地修改, 如图 2-8 所示。

与 C 字符串不同, SDS 的空间分配策略完全杜绝了发生缓冲区溢出的可能性: 当 SDS API 需要对 SDS 进行修改时, API 会先检查 SDS 的空间是否满足修改所需的要求, 如果不满足的话, API 会自动将 SDS 的空间扩展至执行修改所需的大小, 然后才执行实际的修改操作, 所以使用 SDS 既不需要手动修改 SDS 的空间大小, 也不会出现前面所说的缓冲区溢出问题。
举个例子, SDS 的 API 里面也有一个用于执行拼接操作的 sdscat 函数, 它可以将一个 C 字符串拼接到给定 SDS 所保存的字符串的后面, 但是在执行拼接操作之前, sdscat 会先检查给定 SDS 的空间是否足够, 如果不够的话, sdscat 就会先扩展 SDS 的空间, 然后才执行拼接操作。
比如说, 如果我们执行:
sdscat(s, " Cluster");
其中 SDS 值 s 如图 2-9 所示, 那么 sdscat 将在执行拼接操作之前检查 s 的长度是否足够, 在发现 s 目前的空间不足以拼接 " Cluster" 之后, sdscat 就会先扩展 s 的空间, 然后才执行拼接 " Cluster" 的操作, 拼接操作完成之后的 SDS 如图 2-10 所示。


注意图 2-10 所示的 SDS : sdscat 不仅对这个 SDS 进行了拼接操作, 它还为 SDS 分配了 13 字节的未使用空间, 并且拼接之后的字符串也正好是 13 字节长, 这种现象既不是 bug 也不是巧合, 它和 SDS 的空间分配策略有关, 接下来的小节将对这一策略进行说明。
减少修改字符串时带来的内存重分配次数
正如前两个小节所说, 因为 C 字符串并不记录自身的长度, 所以对于一个包含了 N 个字符的 C 字符串来说, 这个 C 字符串的底层实现总是一个 N+1 个字符长的数组(额外的一个字符空间用于保存空字符)。
因为 C 字符串的长度和底层数组的长度之间存在着这种关联性, 所以每次增长或者缩短一个 C 字符串, 程序都总要对保存这个 C 字符串的数组进行一次内存重分配操作:
- 如果程序执行的是增长字符串的操作, 比如拼接操作(append), 那么在执行这个操作之前, 程序需要先通过内存重分配来扩展底层数组的空间大小 —— 如果忘了这一步就会产生缓冲区溢出。
- 如果程序执行的是缩短字符串的操作, 比如截断操作(trim), 那么在执行这个操作之后, 程序需要通过内存重分配来释放字符串不再使用的那部分空间 —— 如果忘了这一步就会产生内存泄漏。
举个例子, 如果我们持有一个值为 "Redis" 的 C 字符串 s , 那么为了将 s 的值改为 "Redis Cluster" , 在执行:
strcat(s, " Cluster");
之前, 我们需要先使用内存重分配操作, 扩展 s 的空间。
之后, 如果我们又打算将 s 的值从 "Redis Cluster" 改为 "Redis Cluster Tutorial" , 那么在执行:
strcat(s, " Tutorial");
之前, 我们需要再次使用内存重分配扩展 s 的空间, 诸如此类。
因为内存重分配涉及复杂的算法, 并且可能需要执行系统调用, 所以它通常是一个比较耗时的操作:
- 在一般程序中, 如果修改字符串长度的情况不太常出现, 那么每次修改都执行一次内存重分配是可以接受的。
- 但是 Redis 作为数据库, 经常被用于速度要求严苛、数据被频繁修改的场合, 如果每次修改字符串的长度都需要执行一次内存重分配的话, 那么光是执行内存重分配的时间就会占去修改字符串所用时间的一大部分, 如果这种修改频繁地发生的话, 可能还会对性能造成影响。
为了避免 C 字符串的这种缺陷, SDS 通过未使用空间解除了字符串长度和底层数组长度之间的关联: 在 SDS 中, buf 数组的长度不一定就是字符数量加一, 数组里面可以包含未使用的字节, 而这些字节的数量就由 SDS 的 free 属性记录。
通过未使用空间, SDS 实现了空间预分配和惰性空间释放两种优化策略。
空间预分配
空间预分配用于优化 SDS 的字符串增长操作: 当 SDS 的 API 对一个 SDS 进行修改, 并且需要对 SDS 进行空间扩展的时候, 程序不仅会为 SDS 分配修改所必须要的空间, 还会为 SDS 分配额外的未使用空间。
其中, 额外分配的未使用空间数量由以下公式决定:
- 如果对 SDS 进行修改之后, SDS 的长度(也即是
len属性的值)将小于1 MB, 那么程序分配和len属性同样大小的未使用空间, 这时 SDSlen属性的值将和free属性的值相同。 举个例子, 如果进行修改之后, SDS 的len将变成13字节, 那么程序也会分配13字节的未使用空间, SDS 的buf数组的实际长度将变成13 + 13 + 1 = 27字节(额外的一字节用于保存空字符)。 - 如果对 SDS 进行修改之后, SDS 的长度将大于等于
1 MB, 那么程序会分配1 MB的未使用空间。 举个例子, 如果进行修改之后, SDS 的len将变成30 MB, 那么程序会分配1 MB的未使用空间, SDS 的buf数组的实际长度将为30 MB + 1 MB + 1 byte。
通过空间预分配策略, Redis 可以减少连续执行字符串增长操作所需的内存重分配次数。
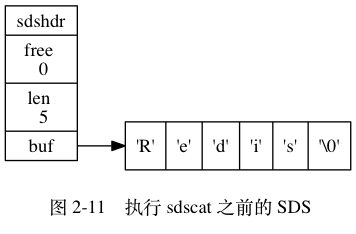
举个例子, 对于图 2-11 所示的 SDS 值 s 来说, 如果我们执行:
sdscat(s, " Cluster");
那么 sdscat 将执行一次内存重分配操作, 将 SDS 的长度修改为 13 字节, 并将 SDS 的未使用空间同样修改为 13 字节, 如图 2-12 所示。

如果这时, 我们再次对 s 执行:
sdscat(s, " Tutorial");
那么这次 sdscat 将不需要执行内存重分配: 因为未使用空间里面的 13 字节足以保存 9 字节的 " Tutorial" , 执行 sdscat 之后的 SDS 如图 2-13 所示。

在扩展 SDS 空间之前, SDS API 会先检查未使用空间是否足够, 如果足够的话, API 就会直接使用未使用空间, 而无须执行内存重分配。
通过这种预分配策略, SDS 将连续增长 N 次字符串所需的内存重分配次数从必定 N 次降低为最多 N 次。
惰性空间释放
惰性空间释放用于优化 SDS 的字符串缩短操作: 当 SDS 的 API 需要缩短 SDS 保存的字符串时, 程序并不立即使用内存重分配来回收缩短后多出来的字节, 而是使用 free 属性将这些字节的数量记录起来, 并等待将来使用。
举个例子, sdstrim 函数接受一个 SDS 和一个 C 字符串作为参数, 从 SDS 左右两端分别移除所有在 C 字符串中出现过的字符。
比如对于图 2-14 所示的 SDS 值 s 来说, 执行:
sdstrim(s, "XY"); // 移除 SDS 字符串中的所有 'X' 和 'Y'
会将 SDS 修改成图 2-15 所示的样子。


注意执行 sdstrim 之后的 SDS 并没有释放多出来的 8 字节空间, 而是将这 8 字节空间作为未使用空间保留在了 SDS 里面, 如果将来要对 SDS 进行增长操作的话, 这些未使用空间就可能会派上用场。
举个例子, 如果现在对 s 执行:
sdscat(s, " Redis");
那么完成这次 sdscat 操作将不需要执行内存重分配: 因为 SDS 里面预留的 8 字节空间已经足以拼接 6 个字节长的 " Redis" , 如图 2-16 所示。

通过惰性空间释放策略, SDS 避免了缩短字符串时所需的内存重分配操作, 并为将来可能有的增长操作提供了优化。
与此同时, SDS 也提供了相应的 API , 让我们可以在有需要时, 真正地释放 SDS 里面的未使用空间, 所以不用担心惰性空间释放策略会造成内存浪费。
二进制安全
C 字符串中的字符必须符合某种编码(比如 ASCII), 并且除了字符串的末尾之外, 字符串里面不能包含空字符, 否则最先被程序读入的空字符将被误认为是字符串结尾 —— 这些限制使得 C 字符串只能保存文本数据, 而不能保存像图片、音频、视频、压缩文件这样的二进制数据。
举个例子, 如果有一种使用空字符来分割多个单词的特殊数据格式, 如图 2-17 所示, 那么这种格式就不能使用 C 字符串来保存, 因为 C 字符串所用的函数只会识别出其中的 "Redis" , 而忽略之后的 "Cluster" 。

虽然数据库一般用于保存文本数据, 但使用数据库来保存二进制数据的场景也不少见, 因此, 为了确保 Redis 可以适用于各种不同的使用场景, SDS 的 API 都是二进制安全的(binary-safe): 所有 SDS API 都会以处理二进制的方式来处理 SDS 存放在 buf 数组里的数据, 程序不会对其中的数据做任何限制、过滤、或者假设 —— 数据在写入时是什么样的, 它被读取时就是什么样。
这也是我们将 SDS 的 buf 属性称为字节数组的原因 —— Redis 不是用这个数组来保存字符, 而是用它来保存一系列二进制数据。
比如说, 使用 SDS 来保存之前提到的特殊数据格式就没有任何问题, 因为 SDS 使用 len 属性的值而不是空字符来判断字符串是否结束, 如图 2-18 所示。

通过使用二进制安全的 SDS , 而不是 C 字符串, 使得 Redis 不仅可以保存文本数据, 还可以保存任意格式的二进制数据。
兼容部分 C 字符串函数
虽然 SDS 的 API 都是二进制安全的, 但它们一样遵循 C 字符串以空字符结尾的惯例: 这些 API 总会将 SDS 保存的数据的末尾设置为空字符, 并且总会在为 buf 数组分配空间时多分配一个字节来容纳这个空字符, 这是为了让那些保存文本数据的 SDS 可以重用一部分 <string.h> 库定义的函数。

举个例子, 如图 2-19 所示, 如果我们有一个保存文本数据的 SDS 值 sds , 那么我们就可以重用 <string.h>/strcasecmp 函数, 使用它来对比 SDS 保存的字符串和另一个 C 字符串:
strcasecmp(sds->buf, "hello world");
这样 Redis 就不用自己专门去写一个函数来对比 SDS 值和 C 字符串值了。
与此类似, 我们还可以将一个保存文本数据的 SDS 作为 strcat 函数的第二个参数, 将 SDS 保存的字符串追加到一个 C 字符串的后面:
strcat(c_string, sds->buf);
这样 Redis 就不用专门编写一个将 SDS 字符串追加到 C 字符串之后的函数了。
通过遵循 C 字符串以空字符结尾的惯例, SDS 可以在有需要时重用 <string.h> 函数库, 从而避免了不必要的代码重复。
总结
表 2-1 对 C 字符串和 SDS 之间的区别进行了总结。
表 2-1 C 字符串和 SDS 之间的区别
| C 字符串 | SDS |
|---|---|
| 获取字符串长度的复杂度为 O(N) 。 | 获取字符串长度的复杂度为 O(1) 。 |
| API 是不安全的,可能会造成缓冲区溢出。 | API 是安全的,不会造成缓冲区溢出。 |
修改字符串长度 N 次必然需要执行 N 次内存重分配。 |
修改字符串长度 N 次最多需要执行 N 次内存重分配。 |
| 只能保存文本数据。 | 可以保存文本或者二进制数据。 |
可以使用所有 <string.h> 库中的函数。 |
可以使用一部分 <string.h> 库中的函数。 |
表 2-2 SDS 的主要操作 API
| 函数 | 作用 | 时间复杂度 |
|---|---|---|
sdsnew |
创建一个包含给定 C 字符串的 SDS 。 | O(N) , N 为给定 C 字符串的长度。 |
sdsempty |
创建一个不包含任何内容的空 SDS 。 | O(1) |
sdsfree |
释放给定的 SDS 。 | O(1) |
sdslen |
返回 SDS 的已使用空间字节数。 | 这个值可以通过读取 SDS 的 len 属性来直接获得, 复杂度为 O(1) 。 |
sdsavail |
返回 SDS 的未使用空间字节数。 | 这个值可以通过读取 SDS 的 free 属性来直接获得, 复杂度为 O(1) 。 |
sdsdup |
创建一个给定 SDS 的副本(copy)。 | O(N) , N 为给定 SDS 的长度。 |
sdsclear |
清空 SDS 保存的字符串内容。 | 因为惰性空间释放策略,复杂度为 O(1) 。 |
sdscat |
将给定 C 字符串拼接到 SDS 字符串的末尾。 | O(N) , N 为被拼接 C 字符串的长度。 |
sdscatsds |
将给定 SDS 字符串拼接到另一个 SDS 字符串的末尾。 | O(N) , N 为被拼接 SDS 字符串的长度。 |
sdscpy |
将给定的 C 字符串复制到 SDS 里面, 覆盖 SDS 原有的字符串。 | O(N) , N 为被复制 C 字符串的长度。 |
sdsgrowzero |
用空字符将 SDS 扩展至给定长度。 | O(N) , N 为扩展新增的字节数。 |
sdsrange |
保留 SDS 给定区间内的数据, 不在区间内的数据会被覆盖或清除。 | O(N) , N 为被保留数据的字节数。 |
sdstrim |
接受一个 SDS 和一个 C 字符串作为参数, 从 SDS 左右两端分别移除所有在 C 字符串中出现过的字符。 | O(M*N) , M 为 SDS 的长度, N 为给定 C 字符串的长度。 |
sdscmp |
对比两个 SDS 字符串是否相同。 | O(N) , N 为两个 SDS 中较短的那个 SDS 的长度。 |
- Redis 只会使用 C 字符串作为字面量, 在大多数情况下, Redis 使用 SDS (Simple Dynamic String,简单动态字符串)作为字符串表示。
- 比起 C 字符串, SDS 具有以下优点:
- 常数复杂度获取字符串长度。
- 杜绝缓冲区溢出。
- 减少修改字符串长度时所需的内存重分配次数。
- 二进制安全。
- 兼容部分 C 字符串函数。
将连续增长 N 次字符串所需的内存重分配次数从必定 N 次降低为最多 N 次 二进制安全的更多相关文章
- leetCode刷题(找到最长的连续不重复的字符串长度)
Given a string, find the length of the longest substring without repeating characters. Examples: Giv ...
- Java基础知识强化之集合框架笔记61:Map集合之统计字符串中每个字符出现的次数的案例
1. 首先我们看看统计字符串中每个字符出现的次数的案例图解: 2. 代码实现: (1)需求 :"aababcabcdabcde",获取字符串中每一个字母出现的次数要求结果:a(5) ...
- javascript 写一段代码,判断一个字符串中出现次数最多的字符串,并统计出现的次数
javascript 写一段代码,判断一个字符串中出现次数最多的字符串,并统计出现的次数 function test(){ var bt = document.getElementById(" ...
- 用es6的Array.reduce()方法计算一个字符串中每个字符出现的次数
有一道经典的字符串处理的问题,统计一个字符串中每个字符出现的次数. 用es6的Array.reduce()函数配合“...”扩展符号可以更方便的处理该问题. s='abananbaacnncn' [. ...
- 统计字符串中每个字符出现的次数(Python)
#统计字符串中每个字符出现的次数 以The quick brown fox jumps over the lazy dog为例 message='The quick brown fox jumps o ...
- Java中统计字符串中各个字符出现的次数
import java.util.Iterator; import java.util.Set; import java.util.TreeMap; public class TreeMapDemo ...
- c# 字符串中某个词出现的次数及索引
字符串中某个词出现的次数主要是考察队字符串方法的使用: indexof(): 有9个重载,具体的请转到F12查看详细内容: 本文使用的是第6个重载: 如果找到该字符串,则为从零开始的索引位置:如果未找 ...
- Java统计一个字符串中各个字符出现的次数
相信很多人在工作的时候都会遇到这样一个,如何统计一个字符串中各个字符出现的次数呢,这种需求一把用在数据分析方面,比如根据特定的条件去查找某个字符出现的次数.那么如何实现呢,其实也很简单,下面我贴上代码 ...
- JAVA经典题--计算一个字符串中每个字符出现的次数
需求: 计算一个字符串中每个字符出现的次数 思路: 通过toCharArray()拿到一个字符数组--> 遍历数组,将数组元素作为key,数值1作为value存入map容器--> 如果k ...
随机推荐
- MVC 微信网页授权 获取 OpenId
最近开发微信公众平台,做下记录,以前也开发过,这次开发又给忘了,搞了半天,还是做个笔记为好. 注意框架为MVC 开发微信公众平台.场景为,在模板页中获取用户openid,想要进行验证的页面,集成模板页 ...
- 后台查询出来的list结果 在后台查询字典表切换 某些字段的内容
list=listEFormat(list, "Class_type", "611");//list查询数据库得到的结果Class_type /** * @Ti ...
- 容器编排系统K8s之访问控制--用户认证
前文我们聊到了k8s的statefulset控制器相关使用说明,回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/14201103.html:今天我们来聊一下k8 ...
- pandas取前K大的数,sort_values()和nlargest()速度比较
排序量比较大时: 数据量比较小时: 所以结论就是: 数据量大时选用nlargest,数据量小时选用sort_values() 具体数据量怎么算大:10000条时两个方法的时间差不多,所以可以按1000 ...
- [LeetCode]652. Find Duplicate Subtrees找到重复树
核心思想是:序列化树 序列化后,用String可以唯一的代表一棵树,其实就是前序遍历改造一下(空节点用符号表示): 一边序列化,一边用哈希表记录有没有重复的,如果有就添加,注意不能重复添加. 重点就是 ...
- C语言全排列
#include <stdio.h> int m=5; char s[]="12345"; void Swap(char *a, char *b)//元素交换 { ch ...
- js表单简单验证(手机号邮箱)
1 <%@ page language="java" contentType="text/html; charset=UTF-8" 2 pageEncod ...
- [php]配置文件中的超时时间
概要 php.ini l max_execution_time l max_input_time php-fpm.conf l process_control_timeout l reques ...
- 如何快速学会git
相信大多数入门者都对git的原理比较恍惚,今天我们来告诉大家如何快速学会git命令. 1.git init 这个命令会在当前目录里创建一个.git目录,也就是初始化本地仓库.git. 如图先创建文件夹 ...
- “You may need an appropriate loader to handle this file type”
这里不能为空!!!!!!!!!!!!!!!!!!!!