.NET Core学习笔记(7)——Exception最佳实践
1.为什么不要给每个方法都写try catch
为每个方法都编写try catch是错误的做法,理由如下:
a.重复嵌套的try catch是无用的,多余的。
这一点非常容易理解,下面的示例代码中,OutsideMethodA中的try catch是不起作用的。
class NestedTryCatch
{
internal void OutsideMethodA()
{
try
{
this.InsideMethodB();
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
} private void InsideMethodB()
{
try
{
this.ExceptionMethod();
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
} private void ExceptionMethod()
{
throw new NotImplementedException("You did't implement this method!");
}
}
b.多余的try catch会掩盖严重的bug,将bug珍藏在log里并不会增值。
下面的代码中,一旦参数uri为null,意味着程序逻辑必然有bug,存在错误的调用。与其将这个bug和HttpRequestException混在一起写log,然后相忘于江湖。不如大大方方在开发阶段就每次crash,强迫必须修复隐藏的逻辑错误。
同时我们可以看到,catch里再次返回了null,这又是一种不负责任给上层代码挖坑的行为。上层代码两眼一黑,就得一个null,啥也不知道,估计也不敢问。
注释的部分给出了两种解决方案,Assert或者主动throw。
internal async Task<string> DownloadContent(string uri)
{
//Debug.Assert(!string.IsNullOrEmpty(uri)); //if (string.IsNullOrEmpty(uri))
//{
// throw new ArgumentNullException("uri is null");
//} try
{
using (var httpClient = new HttpClient())
{
return await httpClient.GetStringAsync(uri);
}
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
return null;
}
}
c.当程序因Exception进入不可继续的状态时,通过try catch避免程序crash,除了可以稍微体面地退出,并没有更大意义。
例如网络游戏在运行过程中,发生了错误。本地数据与服务器不再同步,是不会允许继续运行,也不会承认期间产生的本地数据。
硬用代码举例的话,就比如在构造函数里搞个try catch吞掉Exception,这个new出来的实例谁还敢用的,请站出来……
d.都知道空的try catch是错误的。
try
{
……
}
catch{ }
难道加个日志就会产生质变了嘛?
try
{
……
}
catch (Exception ex)
{
Log.Error(“xxxx方法失败了!”);
}
2.何时使用try catch?只提出问题不给出解决方案,会被骂耍流氓。下面我们来分析几个适于添加try catch的场景。
a.仅在你真的打算,并且知道如何处理当前的Exception时,加try catch。比较明显的场景是网络请求中的retry。
public async Task<string> HandleHttpRequestExceptionAsync()
{
HttpClient client = new HttpClient();
try
{
return await client.GetStringAsync("http://www.ajshdgasjhdgajdhgasjhdgasjdhgasjdhgas.tk/"); }
catch (HttpRequestException ex)
{
//Simulate to try again.
//log here then retry
return await client.GetStringAsync("http://www.dell.com/");
}
finally
{
client?.Dispose();
}
}
b.当常规流程控制无法避免异常时,加try catch。
通常可以用if来避免的问题,就不应通过try catch处理。反例如IO处理,无法确认用户会不会拔U盘,该情况下需catch IOException。
c.功能性的类库中的API缺乏业务逻辑,不知道如何处理Exception时,不应加try catch。应将错误抛给上层,由存在业务逻辑的调用方处理。
比较典型的,在使用Microsoft UI Automation的API时,找元素的API可能会抛出COMException。API本身认为调用方传参错误,传入了不存在元素的ID。但上层的调用代码会知道,是因为当前页面未加载完全。如果我们希望在这里retry或者忽略这个错误,try catch是合理的。
d.为了体面的退出。
在顶层加入try catch记录log是可行的。调用堆栈的信息会完整的保存下来。(针对Task的异常堆栈丢失问题,请看《.NET Core学习笔记(3)——async/await中的Exception处理》)
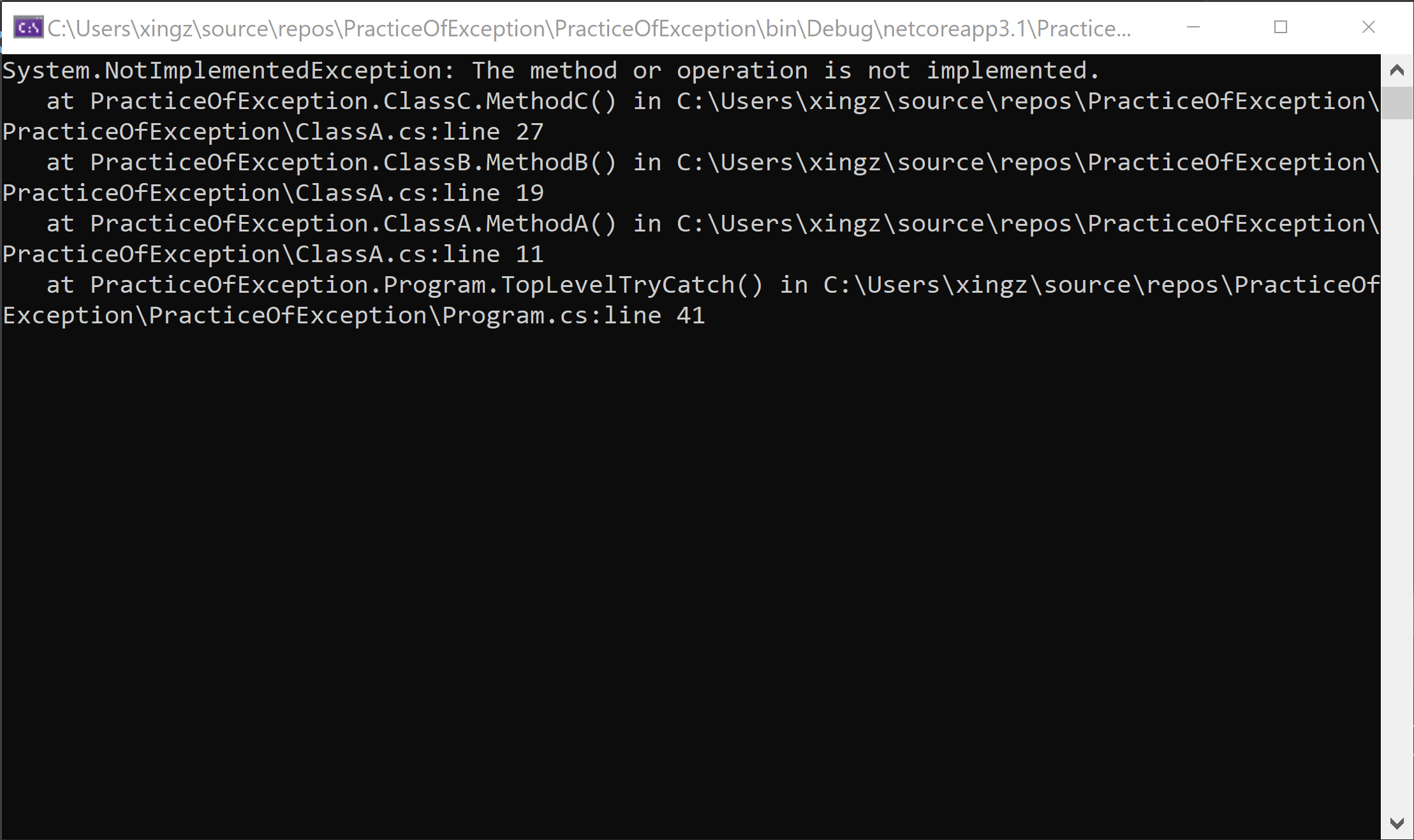
3.在顶层代码应用try catch的一些可行做法
a.如果我们真的害怕且不能接受crash,那么可以试着在Main方法里加个try catch,然后记录log。
b.不是主线程的UnHandle Exception可以通过AppDomain.UnhandledException来处理。
public static void Main()
{
AppDomain currentDomain = AppDomain.CurrentDomain;
currentDomain.UnhandledException += new UnhandledExceptionEventHandler(MyHandler); try
{
throw new Exception("");
}
catch (Exception e)
{
Console.WriteLine("Catch clause caught : {0} \n", e.Message);
} throw new Exception("");
} static void MyHandler(object sender, UnhandledExceptionEventArgs args)
{
Exception e = (Exception)args.ExceptionObject;
Console.WriteLine("MyHandler caught : " + e.Message);
Console.WriteLine("Runtime terminating: {0}", args.IsTerminating);
}
默认情况下.NET 程序将会退出,因为此时的程序因为这个unhandle exception,被认为进入了未知,且不可继续的状态。
此时即使通过某些特殊手段保持程序不退出,也没有任何意义。unhandle exception的意思就是有crash bug没处理。开发阶段干嘛去了。
https://docs.microsoft.com/en-us/dotnet/standard/threading/exceptions-in-managed-threads#application-compatibility-flag
上述链接提供了程序不退出的可能选项,但我认为实不可取。
4.判断Exception类型的一些技巧,
仍然以HttpClient.GetStringAsync举例,我们可以通过查看MSDN得知该方法可能抛出如下几个Exceptions:

a.AugumentNullException
我们上文提过了,在上层调用代码可以通过null check来避免,或者主动抛出exception。
b.HttpRequestException
网络错误都会抛这个异常,通常我们需要捕获该异常,并通过异常中返回的Status或是其他信息来针对性处理。
c.TaskCanceledException
在以下两种情况会被抛出:
- 指定了HttpClient.Timeout同时本次网络请求超出指定时间
- 在使用Task异步编程时,在Task Completed之前调用CancellationTokenSource对象的Cancel()方法
那么在写代码的时候,就要判断是否是.NET Core,同时符合以上两点。否则就无需对该异常添加处理。
举着例子更重要的目的是想说,除了顶层代码的最后一道用于记录log的try exception。没有任何理由用到基类Exception。
文中提到的示例代码可以在这里找到:
https://github.com/manupstairs/PracticeOfException
本篇提到了处理Exception时的一些实践经验,且为一家之言,如有错误的地方还请指出。
.NET Core学习笔记(7)——Exception最佳实践的更多相关文章
- 《Linux学习笔记:文本编辑最佳实践》
[Linux文本编辑的四种方法] 例如,要想test.txt文件添加内容"I am a boy",test.txt在当前目录中 方法一:vi编辑法 [推荐] 打开终端,输入vi t ...
- .NET CORE学习笔记系列(2)——依赖注入[6]: .NET Core DI框架[编程体验]
原文https://www.cnblogs.com/artech/p/net-core-di-06.html 毫不夸张地说,整个ASP.NET Core框架是建立在一个依赖注入框架之上的,它在应用启动 ...
- Dotnet core使用JWT认证授权最佳实践(二)
最近,团队的小伙伴们在做项目时,需要用到JWT认证.遂根据自己的经验,整理成了这篇文章,用来帮助理清JWT认证的原理和代码编写操作. 第一部分:Dotnet core使用JWT认证授权最佳实践(一) ...
- .NET CORE学习笔记系列(2)——依赖注入[7]: .NET Core DI框架[服务注册]
原文https://www.cnblogs.com/artech/p/net-core-di-07.html 包含服务注册信息的IServiceCollection对象最终被用来创建作为DI容器的IS ...
- .NET CORE学习笔记系列(2)——依赖注入[5]: 创建一个简易版的DI框架[下篇]
为了让读者朋友们能够对.NET Core DI框架的实现原理具有一个深刻而认识,我们采用与之类似的设计构架了一个名为Cat的DI框架.在上篇中我们介绍了Cat的基本编程模式,接下来我们就来聊聊Cat的 ...
- .NET CORE学习笔记系列(2)——依赖注入[4]: 创建一个简易版的DI框架[上篇]
原文https://www.cnblogs.com/artech/p/net-core-di-04.html 本系列文章旨在剖析.NET Core的依赖注入框架的实现原理,到目前为止我们通过三篇文章从 ...
- .NET CORE学习笔记系列(2)——依赖注入【3】依赖注入模式
原文:https://www.cnblogs.com/artech/p/net-core-di-03.html IoC主要体现了这样一种设计思想:通过将一组通用流程的控制权从应用转移到框架中以实现对流 ...
- .NET CORE学习笔记系列(2)——依赖注入【2】基于IoC的设计模式
原文:https://www.cnblogs.com/artech/p/net-core-di-02.html 正如我们在<控制反转>提到过的,很多人将IoC理解为一种“面向对象的设计模式 ...
- .NET CORE学习笔记系列(2)——依赖注入【1】控制反转IOC
原文:https://www.cnblogs.com/artech/p/net-core-di-01.html 一.流程控制的反转 IoC的全名Inverse of Control,翻译成中文就是“控 ...
随机推荐
- 如何在使用spring boot的时候,去掉使用tomcat
在spring boot中引入spring-boot-starter-web依赖的时候,不想使用spring boot提供的tomcat怎么办呢? 如下配置则可以解决问题: <dependenc ...
- 服务消费者(Feign-上)
上一篇文章,讲述了Ribbon去做负载请求的服务消费者,本章讲述声明性REST客户端:Feign的简单使用方式 - Feign简介 Feign是一个声明式的Web服务客户端.这使得Web服务客户端的写 ...
- 真的可以,用C语言实现面向对象编程OOP
ID:技术让梦想更伟大 作者:李肖遥 解释区分一下C语言和OOP 我们经常说C语言是面向过程的,而C++是面向对象的,然而何为面向对象,什么又是面向过程呢?不管怎么样,我们最原始的目标只有一个就是实现 ...
- css与javascript重难点,学前端,基础不好一切白费!
JavaScript是一种属于网络的脚本语言,已经被广泛用于Web应用开发,常用来为网页添加各式各样的动态功能,为用户提供更流畅美观的浏览效果.通常JavaScript脚本是通过嵌入在HTML中来实现 ...
- Git 新建版本库命令
Command line instructions Git global setup git config --global user.name "张三" git config - ...
- python基础知识练习1
1.要求:输入A.B.C获得方程的解. 分析:通过input函数接收A,B,C的值.通过公式计算出detal的值,再根据条件进行判断,输出所需要的值: def args_input(): try: A ...
- Demo_2:Qt实现猜字小游戏
1 环境 系统:windows 10 代码编写运行环境:Qt Creator 4.4.1 (community) Github: 2 简介 参考视频:https://www.bilibili.co ...
- SQL基础随记3 范式 键
SQL基础随记3 范式 键 什么是范式?哈,自己设计会使用但是一问还真说不上来.遂将不太明晰的概念整体下 什么是 & 分类 范式(NF),一种规范,设计数据库模型时对关系内部各个属性之间的 ...
- 最大的位或 HDU - 5969 简单思维题
题目描述 B君和G君聊天的时候想到了如下的问题. 给定自然数l和r ,选取2个整数x,y满足l <= x <= y <= r ,使得x|y最大. 其中|表示按位或,即C. C++. ...
- 如何Simplest搭建个人博客
前期 例如wordpress.hexo.hugo-- 准备 安装Node.js,安装Git,进入Hexo网站.进入Github网站进注册和登录. 建议买个阿里云服务器(学生最近好像是免费的) 开始搭建 ...