AcWing 294. 计算重复
暴力
其实这题的暴力就是个模拟。暴力扫一遍 \(conn(s_1, n_1)\),若出现了 \(res\) 个 \(s_2\)。
答案就是 \(\lfloor res / n1 \rfloor\)。
时间复杂度 \(O(T(|s_1|n1))\)。
算法1:考虑匹配一个 s1 所需的最小字符数
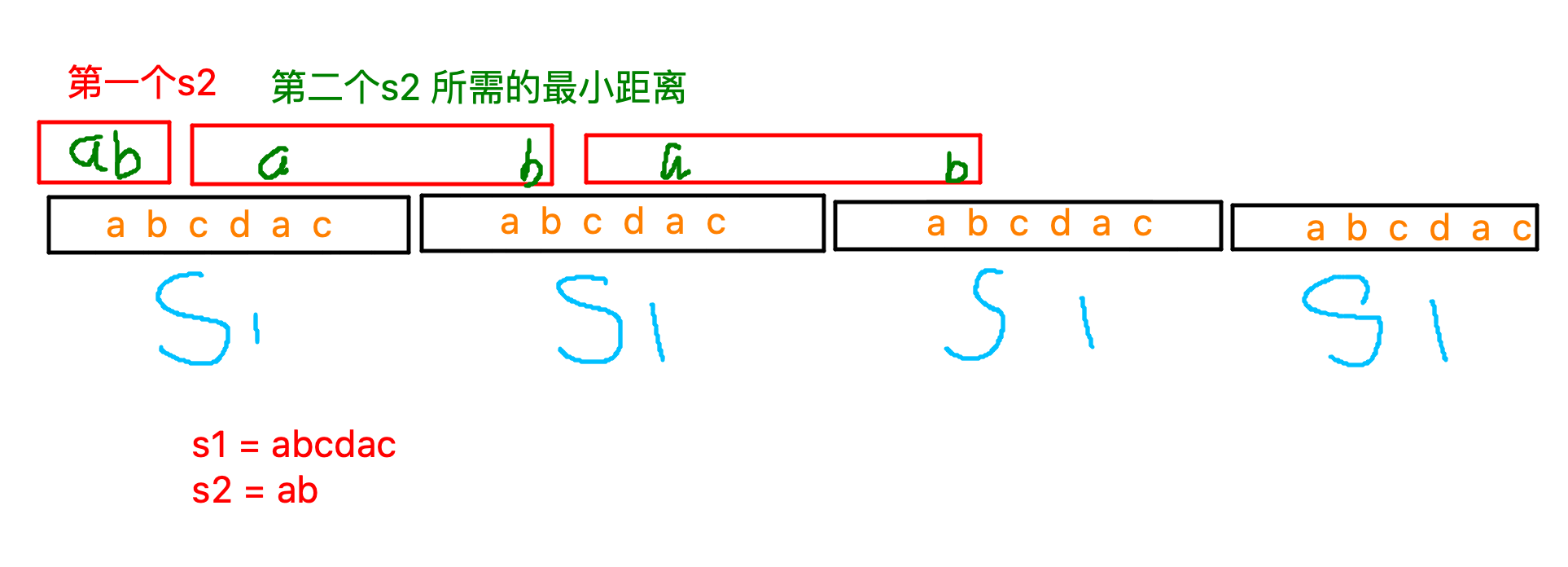
考虑字符串是一直循环的,每走完一个 \(s_2\),他会从一个位置重新开始匹配。我们考虑预处理出对于从 \(0\) ~ \(|s1|- 1\) 这个下标 \(i\) 开始,匹配一个 \(s_2\) 所需最小的字符数,设其为 \(f[i]\)。
那么我们就不需要把整个 \(conn(s_1, n_1)\) 搞出来了,可以搞一个变量 \(p = 0\) 表示当前走过的字符数,设出现的 \(s2\) 个数 \(res = 0\),循环执行:
如果 \(p + f[p \% |s1|] <= n1 *|s1|\),就 \(p += f[p \% |s1|], ans++\)。形象理解就是如果还能匹配一个 \(s2\),并且不超过限制,我就再过一个 \(s_2\),知道上述条件不符合时停止。
考虑最坏时答案是 \(|s_1| * n1 / |s2|\)。
所以 时间复杂度 \(O(T(|s_1| * n1 / |s2|))\)。最坏情况下和暴力一样的,想了那么久你 tm 跟暴力还一样。。
倍增
刚才的跳的过程可以描述为:
- 能跳就跳
- 对于每个 \(p\) ,有唯一的后继 \(p + f[p \% |s1|]\)
这不就是明显的可以倍增优化吗?
设 \(dp[i][j]\) 为\(s_1\)循环节从下标 \(i\) 出发,匹配 \(2 ^ j\) 个 \(s_2\) 串所需的最小字符数。
初始状态:\(dp[i][0] = f[i]\)
状态转移:\(dp[i][j] = dp[i][j - 1] + dp[(i + dp[i][j - 1]) \% |s_1|][j - 1]\),就是用两个 \(2 ^{j - 1}\) 拼出 \(2 ^ j\)。
跳的时候就用倍增模板就行了:
初始设 \(p = 0, res = 0\),从大到小枚举 \(j\):
- 如果 \(p + f[p \% |s_1|][j] <= n_1 *|s_1|\),就 \(p += f[p \% |s_1|][j], ans += 2 ^ j\)。
时间复杂度
在理论最坏情况下,貌似预处理是 \(O(|s| ^ 3)\) 的,因为没说只有小写字母,所以考虑构造如下数据:
abcdefghijklmnopqrstuvwxyz......(连续不一样的100个字符)
......zyxwvutsrqponmlkjihgfedcba
那么从 \(a\),第一个 \(s2\) 的最后才匹配到第二个字符,要匹配 \(|s_1| * |s_2| - |s_2| + 1\) 个字符才行
从 \(b\) 字符出发,要匹配 \(|s_1| * |s_2| - |s_2| + 0\) 个字符才行
...
这样,对于每个 \(i \in [0, |s_1|)\),他会循环 $ (|s_1| - 1) * |s_2| + 2 - i$。总的就是 \(s_1 * ((|s_1|) * |s_2| + 2) - \frac{|s_1| - 1 * |s_1|}{2}\)
\(O(T(|s_1| ^ 2|s_2| + log_{|s_1| * n_1 / |s_2|}))\)。大概最坏情况 \(O(1000000T)\) 左右。
跑的已经很快了 \(13ms\)
\(Tips:\)此题输入比较毒瘤,建议用 \(cin\)。因为如果用 \(scanf\) 貌似最后有个换行如果用 \(\not= EOF\) 会再算一组数据...
或者可以采取一种奇妙的方式,\(scanf()\) 这个玩意会返回成功读入变量的数量,你可以判断是否读满了四个变量...
#include <cstdio>
#include <iostream>
#include <cstring>
#include <cmath>
using namespace std;
const int N = 105;
char s1[N], s2[N];
int n1, n2, len1, len2, L, f[N][27];
int main() {
while(scanf("%s %d\n%s %d", s2, &n2, s1, &n1) == 4) {
memset(f, 0, sizeof f);
len1 = strlen(s1), len2 = strlen(s2), L = log2(len1 * n1 / len2);
for (int i = 0; i < len1; i++)
for (int j = 0; f[i][0] <= len1 * len2 && j < len2; f[i][0]++)
if(s2[j] == s1[(i + f[i][0]) % len1]) j++;
if (f[0][0] > len1 * len2) { puts("0"); continue; }
for (int j = 1; j <= L; j++)
for (int i = 0; i < len1; i++)
f[i][j] = f[i][j - 1] + f[(i + f[i][j - 1]) % len1][j - 1];
int p = 0, ans = 0;
for (int i = L; i >= 0; i--)
if(p + f[p % len1][i] <= len1 * n1) p += f[p % len1][i], ans += 1 << i;
printf("%d\n", ans / n2);
}
return 0;
}
算法2 考虑经过一个 s2 匹配的 s1 字符数
字符串匹配这个东西很玄妙,重新阅读这句话:
考虑字符串是一直循环的,每走完一个 \(s_2\),他会从一个位置重新开始匹配。
那么,我们考虑预处理:
- \(f[i]\) 为已经匹配到 \(s_2\) 的第 \(i\) 位,再走完一个 \(s_1\),能新匹配 \(s_2\) 的字符数。
显然,这个东西我们也可以用倍增优化:
设 \(dp[i][j]\) 为已经匹配到 \(s_2\) 的第 \(i\) 位,再走完 \(2 ^ j\) 个 \(s_1\),能新匹配 \(s_2\) 的字符数。
初始状态:\(dp[i][0] = f[i]\)
状态转移:\(dp[i][j] = dp[i][j - 1] + dp[(i + dp[i][j - 1]) \% |s_2|][j - 1]\),就是用两个 \(2 ^{j - 1}\) 的\(s_2\)拼出 \(2 ^ j\)。
最终的答案求解,只需维护一个指针 \(p\),枚举 $n_1 $的对应二进制位 \(i\),如果为 \(1\),就对应跳 $f[p % |s2|][i] $ 步即可。
时间复杂度
\(O(|s_1| * |s_2| + log_2n_1)\) 跑的飞快 \(3ms\)
即使字符串长度出到 $ <= 1000$ ,\(n_1, n_2\) 到 \(long\ long\) 范围也能解决。
#include <cstdio>
#include <iostream>
#include <cstring>
#include <cmath>
using namespace std;
const int N = 105;
char s1[N], s2[N];
int n1, n2, len1, len2, L, f[N][20];
int main() {
while(scanf("%s %d\n%s %d", s2, &n2, s1, &n1) == 4) {
memset(f, 0, sizeof f);
len1 = strlen(s1), len2 = strlen(s2), L = log2(n1);
for (int i = 0; i < len2; i++)
for (int j = 0; j < len1; j++)
if(s2[(i + f[i][0]) % len2] == s1[j]) f[i][0]++;
if (!f[0][0]) { puts("0"); continue; }
for (int j = 1; j <= L; j++)
for (int i = 0; i < len2; i++)
f[i][j] = f[i][j - 1] + f[(i + f[i][j - 1]) % len2][j - 1];
int p = 0, ans = 0;
for (int i = L; i >= 0; i--)
if(n1 >> i & 1) ans += f[p % len2][i], p += f[p % len2][i];
printf("%d\n", ans / len2 / n2);
}
return 0;
}
总结:
算法 \(1\) 的步长是我们的答案,倍增\(dp\)数组的具体数值是限制我们的字符,我们不知道步长,但我们知道限制。
算法 2 的步长是我们已知的 \(n_1\) 个字符串,倍增数组的具体数值是我们的答案(匹配了多少个字符),我们知道步长,按位枚举 \(n_1\) 下的二进制串即可。
两个东西是互逆的,但是反过来,时间复杂度却有神一般的提升,比较有趣。
AcWing 294. 计算重复的更多相关文章
- javascript数据结构与算法---检索算法(二分查找法、计算重复次数)
javascript数据结构与算法---检索算法(二分查找法.计算重复次数) /*只需要查找元素是否存在数组,可以先将数组排序,再使用二分查找法*/ function qSort(arr){ if ( ...
- 计算一个数组里的重复值并且删去(java)
主要思想: 数组可以无序 假设数字里的值都为正 循环判断数组 如果与前面的数字相同则变为-1 然后记录-1的个数算出重复值 然后重新new一个减去重复值长度的新数组 和原数组判断 不为-1的全部复制进 ...
- 【转】计算Java List中的重复项出现次数
本文演示如何使用Collections.frequency和Map来计算重复项出现的次数.(Collections.frequency在JDK 1.5版本以后支持) package com.qiyad ...
- C#linq计算总条数并去重复的写法
一,在实际需求中我们会存在选出了一个集合,而这时我们需要通过集合的某几个字段来计算重复,和统计重复的数量,这时我们可以用到linq来筛选和去重复. 二,如下代码: using System; usin ...
- POJ-3693/HDU-2459 Maximum repetition substring 最多重复次数的子串(需要输出具体子串,按字典序)
http://acm.hdu.edu.cn/showproblem.php?pid=2459 之前hihocoder那题可以算出最多重复次数,但是没有输出子串.一开始以为只要基于那个,每次更新答案的时 ...
- JAVA- 清除数组重复元素
清除数组重复元素并打印新数组. import java.util.*; public class Repeat { public static void main(String[] args) { / ...
- SAP Cloud for Customer客户主数据的重复检查-Levenshtein算法
SAP C4C的客户主数据创建时的重复检查,基于底层HANA数据库的模糊查找功能,根据扫描数据库中已有的数据检测出当前正在创建的客户主数据是否和数据库中记录有重复. 在系统里开启重复检查的配置: 在此 ...
- Leetcode 424.替换后的最长重复字符
替换后的最长重复字符 给你一个仅由大写英文字母组成的字符串,你可以将任意位置上的字符替换成另外的字符,总共可最多替换 k 次.在执行上述操作后,找到包含重复字母的最长子串的长度. 注意:字符串长度 和 ...
- Linux删除重复内容命令uniq笔记
针对文本文件,有时候我们需要删除其中重复的行.或者统计重复行的总次数,这时候可以采用Linux系统下的uniq命令实现相应的功能. 语法格式:uniq [-ic] 常用参数说明: -i 忽略大小写 - ...
随机推荐
- 多MDS变成单MDS的方法
前言 之前有个cepher的环境上是双活MDS的,需要变成MDS,目前最新版本是支持这个操作的 方法 设置最大mds 多活的mds的max_mds会超过1,这里需要先将max_mds设置为1 ceph ...
- python执行rados命令例子
前言 我们以前的管理平台在python平台下面做的,内部做的一些操作采用的是命令执行,然后解析的方式去做的,ceph自身有python的rados接口,可以直接调用原生接口,然后直接解析json的方式 ...
- 协程实现爬虫的例子主要优势在于充分利用IO时间去请求其他的url
# 分别使用urlopen和requests两个模块进行演示 # import requests # 需要安装的 # from urllib.request import urlopen # # ur ...
- Apache Flink Dashboard未授权访问导致任意Jar包上传漏洞
漏洞危害 攻击者无需Flink Dashboard认证,通过上传恶意jar包 csdn-[漏洞复现]Apache Flink任意Jar包上传导致远程代码执行 freebuf-Apache Flink ...
- Appium上下文和H5测试(一)
坚持原创输出,点击蓝字关注我吧 作者:清菡 博客:oschina.云+社区.知乎等各大平台都有. 目录 一.混合应用-H5 1.混合应用是什么? 2.怎么样分辨一个 App 页面究竟是原生的还是 We ...
- zabbix的搭建及操作(3)监控 MySQL 及 HTTP 状态监控
书接上回 -- 详情点击 Server端以配置好 mariadb(MySQL) 及 http 服务 Zabbix实现监控 mysql 数据库 server服务器端配置 vim /usr/local/z ...
- nginx学习首页随机模块
在default.conf下加入这行开启随机模块,在root目录下放入几种不同的html 改完保存下,使用命令检查nginx语法是否正确 nginx -tc /etc/nginx/nginx.conf ...
- 永别了,Dota2!
永别了,Dota2 .输了游戏,我还有人生! 游戏中,总有那些喷子,自己玩的不好,经常说人家! 和大便打架,即使赢了,身上也非常臭! 所以对于这种人,敬而远之即可!不吵不闹,默默把锅扛起!赢了,就好说 ...
- 精尽 MyBatis 源码分析 - SqlSession 会话与 SQL 执行入口
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- JS指定音频audio在某个时间点进行播放,获取当前音频audio的长度,音频时长格式转化
前言: 今天接到一个需求,需要获取某个.mp3音频文件的时间长度和指定音频audio在某个时间点进行播放(比如说这个视频有4分钟,我要让它默认从第2秒的时候开始播放),这里当然想到了H5中的audio ...