作图直观理解Parzen窗估计(附Python代码)
1.简介
Parzen窗估计属于非参数估计。所谓非参数估计是指,已知样本所属的类别,但未知总体概率密度函数的形式,要求我们直接推断概率密度函数本身。
对于不了解的可以看一下https://zhuanlan.zhihu.com/p/88562356
下面仅对《模式分类》(第二版)的内容进行简单探讨和代码实现
2.窗函数

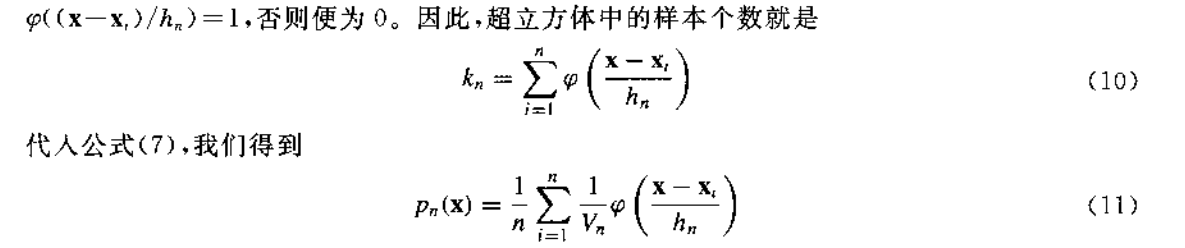
我们不去过多探讨什么是窗函数,只需简单理解这种估计的思想即可。
假设一种情况,你正在屋里看模式分类,结果天降正义掉下来一盆乒乓球,掉的哪里都是,你觉得这是天意,如果很多乒乓球都掉在了一个位置,那么那个位置下一次必掉屠龙宝刀,你想通过估计屋子里乒乓球密度,找出这个位置,那么如何估计呢?
假设你的屋里正好铺了地砖,每块地砖的大小都相同。你此时灵机一动,我只需要统计每块地砖上的乒乓球个数,有最多乒乓球的地砖就是屠龙宝刀的位置。
这似乎听起来很简单,的确,就是这么简单。我们回头看一下公式(9),其中\(
\varphi \left( \mathbf{u} \right)\)其实就是判断某个乒乓球是否在某个地砖上的一个函数,这里的\(\mathbf{u}\)是 乒乓球相对地砖中心的位置。
这里\(\mathbf{u}\)是\(\mathbf{x}-\mathbf{x}_{\mathbf{i}}\),\(\mathbf{x_i}\)是地砖中心的位置,而\(\mathbf{x}\)是乒乓球的位置。
那么公式(9)就显而易见了,如上图所示,你屋子里一块地砖的边长为\({h}\),红色乒乓球在地砖内,蓝色乒乓球没有在地砖内,判断的条件显然就是向量\(\mathbf{x}-\mathbf{x}_{\mathbf{i}}\)的每个元素是否小于\(\frac{1}{2}h\),我们可以直接对\(\mathbf{x}-\mathbf{x}_{\mathbf{i}}\)乘以\(\frac{1}{h}\),这样我们的窗函数就可以写成公式(9)的样子,只需要看参数\(\mathbf{u}=\frac{\mathbf{x}-\mathbf{x}_{\mathbf{i}}}{h}\)的每个元素是否小于\(\frac{1}{2}\)即可。
然后呢? 到这里工作差不多就结束了,我们看哪块地砖上乒乓球最多就行。
对于某块中心在\(\mathbf{x_i}\)的地砖,地砖上的乒乓球个数\(k\)就是公式(10)
有了每块地砖上的乒乓球个数,概率密度的估计就很简单了。
\]
一共\(n\)个球,有\(k\)个球落在某个地砖上,地砖的面积为\(V=h^2\)(别忘了地砖是二维空间),那\(p(\mathbf{x})\)就出来了。
到这里,公式(11)也不需要我说什么了吧
- 这里所写的窗函数表示超立方体,而不是超球体,判断条件也不是点到中心的距离小于2/h,而是点坐标的每个元素都小于2/h。
3.大地砖和小地砖
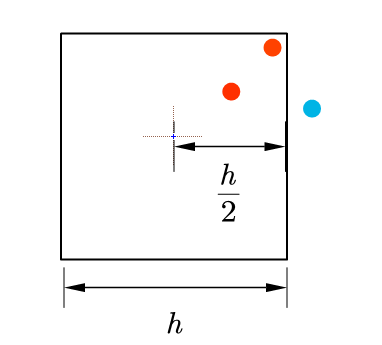
假设400个乒乓球在你房间的大致分为两堆,它们的分布可近似为
\\
\left( x_2\sim N\left( 5, 4 \right),y_2\sim N\left(-4,25 \right) \right)
\\
\]
乒乓球位置如下图所示
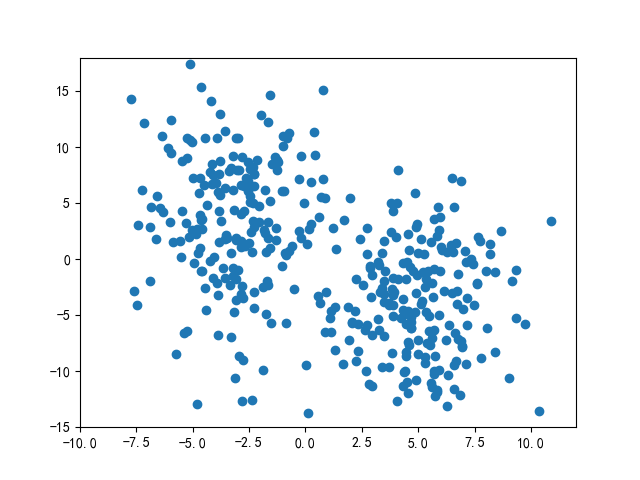
你为了更好的估计乒乓球的密度,用魔法不断更改着地砖的大小,如下图所示,地砖的边长分别为8、5、2,黄点为坐标为(1,4)的地砖所包含的乒乓球,红点为地砖中心。我们可以看到随着\(h\)的不断变化,每个地砖所包含的乒乓球数量是不同的。
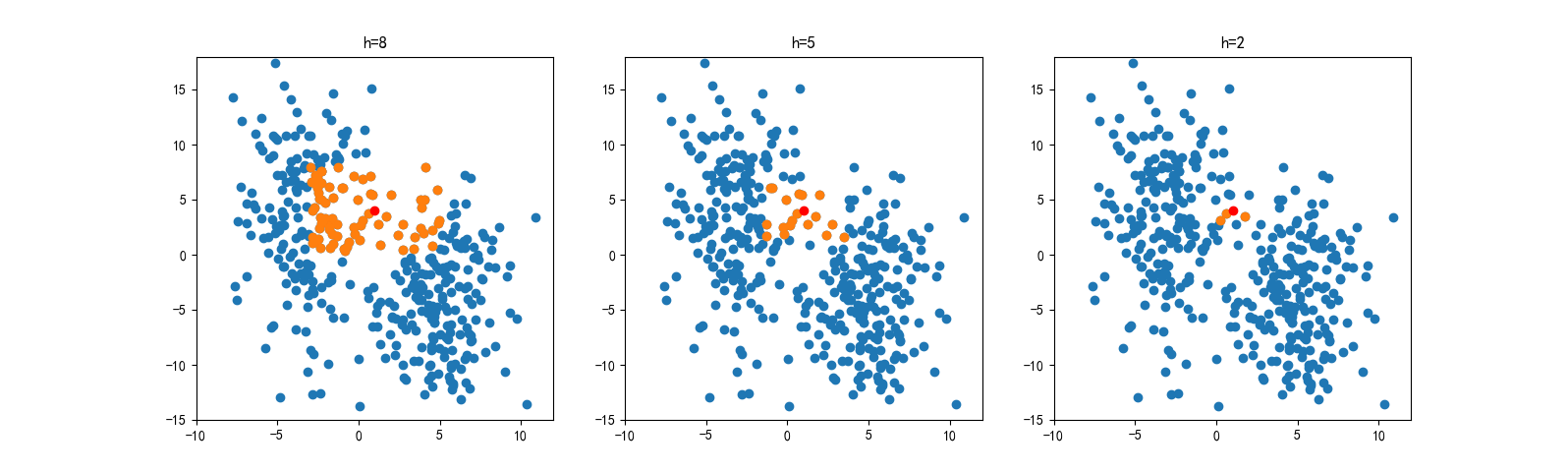
下面我们可以看到三种不同大小的地砖估计出来的概率密度,如下图所示:
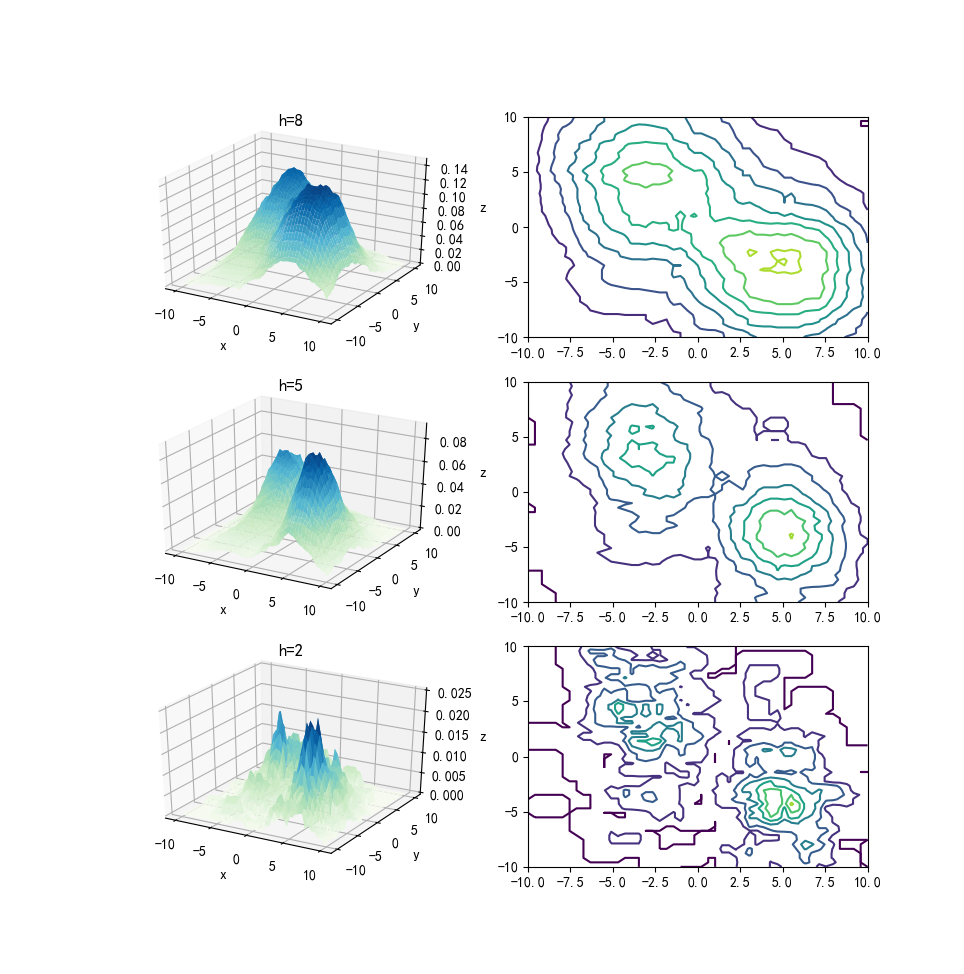
所以说。。咳咳,这里直接放原话。

4.一盆球和无限球
假设我们不再是400个球,我们有。。400000个球,怎么样,真·天降正义,首先乒乓球的分布是这样的:
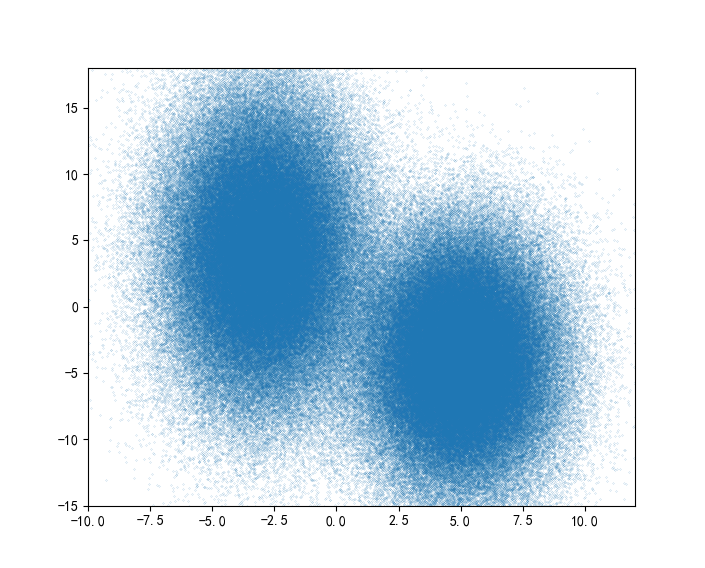
我们再次用边长为8、5、2的地砖对乒乓球进行概率密度估计,如下图所示
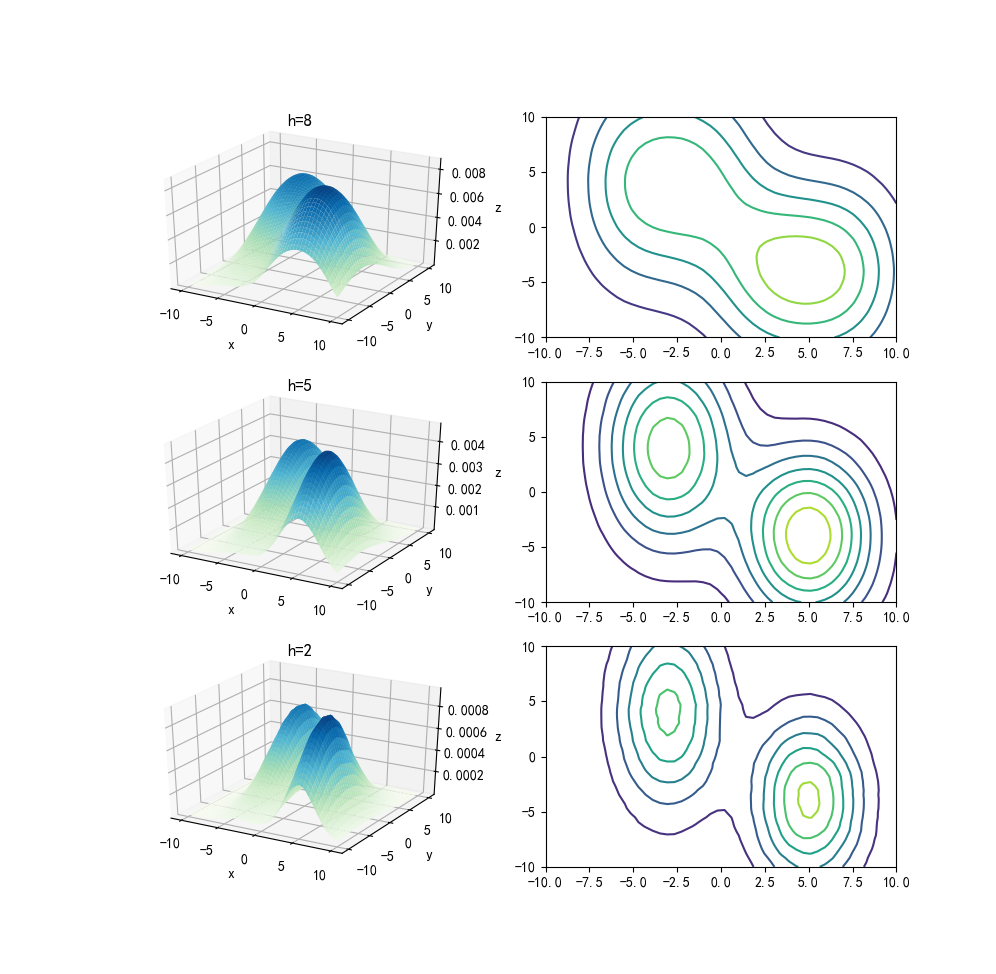
说白了其实都差不多,显而易见的事情,这里再放出一个原话
当n趋近于无穷大时,\(p_n(x)\)将收敛于光滑的\(p(x)\)曲线
代码附录
jupyter格式
环境:python 3.7
#%%
# 生成数据
import matplotlib.pyplot as plt
%matplotlib auto
import numpy as np
n = 200000
datax = np.hstack([np.random.randn(n)*2-3,
np.random.randn(n)*2+5])
datay = np.hstack([np.random.randn(n)* 6+4,
np.random.randn
(n)*5-4])
xi = np.array([1,4])
xv,yv = datax,datay
pos = np.vstack([datax,datay])
#%%
# 散点图
plt.figure(1)
plot_pos = 131
for h in [8,5,2]:
plt.subplot(plot_pos)
plot_pos += 1
Vn = h ** 2
u = (pos - xi.reshape(-1,1))/h # u = (x - xi)/h
ix,iy = pos[:,(abs(u)<=0.5).all(axis=0)]
plt.xlim([-10,12])
plt.ylim([-15,18])
plt.title("h="+str(h))
plt.scatter(xv,yv,s=0.01)
plt.scatter(ix,iy)
plt.scatter(xi[0],xi[1],c='r')
plt.show()
#%%
# 三维概率密度图 和 等高线图
def px(x):
u = (pos - x.reshape(-1,1))/ h # u = (x - xi)/h
ix,iy = pos[:,(abs(u)<=0.5).all(axis=0)]
k = len(ix)
return k / (Vn * n)
w = 50
gx = gy = np.linspace(-10,10,w)
gxv,gyv = np.meshgrid(gx,gy)
fgxv = gxv.ravel()
fgyv = gyv.ravel()
plt.figure(3)
plot_pos = 321
for i in [8,5,2]:
h = i
fpx = np.array([px(x) for x in np.vstack([fgxv,fgyv]).T])
fpx = fpx.reshape(w,w)
ax = plt.subplot(plot_pos,projection='3d')
plot_pos += 1
ax.plot_surface(gxv,gyv,fpx,cmap='GnBu')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.set_title('h='+str(h))
ax = plt.subplot(plot_pos)
plot_pos += 1
ax.contour(gxv,gyv,fpx)
plt.show()
作图直观理解Parzen窗估计(附Python代码)的更多相关文章
- 机器学习 —— 基础整理(三)生成式模型的非参数方法: Parzen窗估计、k近邻估计;k近邻分类器
本文简述了以下内容: (一)生成式模型的非参数方法 (二)Parzen窗估计 (三)k近邻估计 (四)k近邻分类器(k-nearest neighbor,kNN) (一)非参数方法(Non-param ...
- XGBoost参数调优完全指南(附Python代码)
XGBoost参数调优完全指南(附Python代码):http://www.2cto.com/kf/201607/528771.html https://www.zhihu.com/question/ ...
- 【路径规划】 Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenet Frame (附python代码实例)
参考与前言 2010年,论文 Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenet Frame 地址:https ...
- 机器学习/逻辑回归(logistic regression)/--附python代码
个人分类: 机器学习 本文为吴恩达<机器学习>课程的读书笔记,并用python实现. 前一篇讲了线性回归,这一篇讲逻辑回归,有了上一篇的基础,这一篇的内容会显得比较简单. 逻辑回归(log ...
- 使用条件随机场模型解决文本分类问题(附Python代码)
对深度学习感兴趣,热爱Tensorflow的小伙伴,欢迎关注我们的网站!http://www.tensorflownews.com.我们的公众号:磐创AI. 一. 介绍 世界上每天都在生成数量惊人的文 ...
- 【转】XGBoost参数调优完全指南(附Python代码)
xgboost入门非常经典的材料,虽然读起来比较吃力,但是会有很大的帮助: 英文原文链接:https://www.analyticsvidhya.com/blog/2016/03/complete-g ...
- [转载]基于Redis的Bloomfilter去重(附Python代码)
前言: “去重”是日常工作中会经常用到的一项技能,在爬虫领域更是常用,并且规模一般都比较大.去重需要考虑两个点:去重的数据量.去重速度.为了保持较快的去重速度,一般选择在内存中进行去重. 数据量不大时 ...
- outlier异常值检验算法之_箱型图(附python代码)
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
- 深度学习中正则化技术概述(附Python代码)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 磐石 介绍 数据科学研究者们最常遇见的问题之一就是怎样避免过拟合. ...
随机推荐
- MySQL多版本多实例安装启动
多版本,大版本不同测试多实例,一个MySQL5.7.30一个MySQL8.0.20 解压8.0 tar -xvf mysql-8.0.20-linux-glibc2.12-x86_64.tar tar ...
- 一次MySQL索引失效引发的思考
最近公司做了一个千万数量级的项目,由于要求性能比较高,每一个相对慢的查询都需要优化,项目经理是一个比较有经验的开发人员,基本上遇到问题都会先自行处理:或自己分析原因或网络寻求帮助. 但是项目平稳运行一 ...
- hystrix(1) 概述
首先我们来讲一下hystrix解决什么问题.在大型分布式系统中经常会存在下面的几类问题: 1.大型分布式系统中,服务之间相互依赖,如果依赖的服务发生异常,那么当前服务也会出现异常,这样将会导致联级的服 ...
- Jenkins持续集成git、gitlab、sonarqube(7.0)、nexus,自动化部署实战,附安装包,严禁转载!!!
导读 之前用的都是SVN,由于工作需要用到Git,求人不如求己,技多不压身,多学一项技能,未来就少求别人一次,系统的学一遍,自己搭建一整套环境,自动化部署(自动发版),代码质量检测等等(为啥不用doc ...
- 搜索引擎学习(三)Lucene查询索引
一.查询理论 创建查询:构建一个包含了文档域和语汇单元的文档查询对象.(例:fileName:lucene) 查询过程:根据查询对象的条件,在索引中找出相应的term,然后根据term找到对应的文档i ...
- DVWA SQL-injection 附python脚本
SQL-Injection low等级 首先我们将dvwa等级调到low 如图 接下来选择SQL Injection,并在提交框中输入正常值1,查看返回结果 接下来检测是否存在注入,分别输入 1' a ...
- Prime Path(POJ - 3126)【BFS+筛素数】
Prime Path(POJ - 3126) 题目链接 算法 BFS+筛素数打表 1.题目主要就是给定你两个四位数的质数a,b,让你计算从a变到b共最小需要多少步.要求每次只能变1位,并且变1位后仍然 ...
- MarkDown系列教程
编辑了一个Markdown的系列教程,前一部分是摘编自 菜鸟教程 网站 目录 第一篇 Markdown 使用教程 入门
- 一种基于均值不等式的Listwise损失函数
一种基于均值不等式的Listwise损失函数 1 前言 1.1 Learning to Rank 简介 Learning to Rank (LTR) , 也被叫做排序学习, 是搜索中的重要技术, 其目 ...
- JavaScript求数组中元素的最大值
要求: 求数组[2,6,1,77,52,25,7]中的最大值. 实现思路: 声明一个保存最大元素的变量 max 默认最大值max定义为数组中的第一个元素arr[0] 遍历这个数组,把里面每个数组元素和 ...