ES ElasticSearch 7.x 下动态扩大索引的shard数量
ES ElasticSearch 7.x 下动态扩大索引的shard数量
背景
在老版本的ES(例如2.3版本)中, index的shard数量定好后,就不能再修改,除非重建数据才能实现。
从ES6.1开始,ES 支持可以在线操作扩大shard的数量(注意:操作期间也需要对index锁写)
从ES7.0开始,split时候,不再需要加参数 index.number_of_routing_shards
具体参考官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/indices-split-index.html
https://www.elastic.co/guide/en/elasticsearch/reference/6.1/indices-split-index.html
split的过程:
1、创建一个新的目标index,其定义与源index相同,但是具有更多的primary shard。
2、将segment从源index硬链接到目标index。(如果文件系统不支持硬链接,则将所有segment都复制到新索引中,这是一个非常耗时的过程。)
3、创建低级文件后,再次对所有文档进行哈希处理,以删除属于不同shard的documents
4、恢复目标索引,就像它是刚刚重新打开的封闭索引一样。
为啥ES不支持增量resharding?
从N个分片到N + 1个分片。增量重新分片确实是许多键值存储支持的功能。仅添加一个新的分片并将新的数据推入该新的分片是不可行的:这可能是一个索引瓶颈,并根据给定的_id来确定文档所属的分片,这对于获取,删除和更新请求是必需的,会变得很复杂。这意味着我们需要使用其他哈希方案重新平衡现有数据。
键值存储有效执行此操作的最常见方式是使用一致的哈希。当分片的数量从N增加到N + 1时,一致的哈希仅需要重定位键的1 / N。但是,Elasticsearch的存储单位(碎片)是Lucene索引。由于它们以搜索为导向的数据结构,仅占Lucene索引的很大一部分,即仅占5%的文档,将其删除并在另一个分片上建立索引通常比键值存储要高得多的成本。如上节所述,当通过增加乘数来增加分片数量时,此成本保持合理:这允许Elasticsearch在本地执行拆分,这又允许在索引级别执行拆分,而不是为需要重新索引的文档重新编制索引移动,以及使用硬链接进行有效的文件复制。
对于仅追加数据,可以通过创建新索引并将新数据推送到其中,同时添加一个别名来覆盖读取操作的新旧索引,从而获得更大的灵活性。假设旧索引和新索引分别具有M和N个分片,与搜索具有M + N个分片的索引相比,这没有开销。
索引能进行split的前提条件:
1、目标索引不能存在。
2、源索引必须比目标索引具有更少的primary shard。
3、目标索引中主shard的数量必须是源索引中主shard的数量的倍数。
4、处理拆分过程的节点必须具有足够的可用磁盘空间,以容纳现有索引的第二个副本。
操作
下面是具体的实验部分:
tips:实验机器有限,索引的replica都设置为0,生产上至少replica>=1
创建一个索引,2个主shard,没有副本
curl -s -X PUT "http://localhost:9200/twitter?pretty" -H 'Content-Type: application/json' -d'
{
"settings": {
"index.number_of_shards": 2,
"index.number_of_replicas": 0
},
"aliases": {
"my_search_indices": {}
}
}'
# index.number_of_shards:主分片设定个数
# index.number_of_replicas:副本分片设定个数,一个副本就等于把整个索引备份1份
# aliases:设定索引别名"my_search_indices"
# 写入几条测试数据
curl -s -X PUT "http://localhost:9200/my_search_indices/_doc/11?pretty" -H 'Content-Type: application/json' -d '{
"id": 11,
"name":"lee",
"age":"23"
}'
curl -s -X PUT "http://localhost:9200/my_search_indices/_doc/22?pretty" -H 'Content-Type: application/json' -d '{
"id": 22,
"name":"amd",
"age":"22"
}'
# 查询数据
curl -s -XGET "http://localhost:9200/my_search_indices/_search" | jq .
对索引锁写,以便下面执行split操作
curl -s -X PUT "http://localhost:9200/twitter/_settings?pretty" -H 'Content-Type: application/json' -d '{
"settings": {
"index.blocks.write": true
}
}'
# index.blocks.write:写入锁定,只能读,不能写
# 写数据测试,确保锁写生效
curl -s -X PUT "http://localhost:9200/twitter/_doc/33?pretty" -H 'Content-Type: application/json' -d '{
"id": 33,
"name":"amd",
"age":"33"
}'
# 测试写入失败
# 取消 twitter 索引的alias
curl -s -X POST "http://localhost:9200/_aliases?pretty" -H 'Content-Type: application/json' -d '{
"actions" : [
{ "remove" : { "index" : "twitter", "alias" : "my_search_indices" } }
]
}'
curl -s -X GET "http://localhost:9200/_cat/aliases"
第二种方式:
# 取消索引别名
curl -s -X DELETE "http://localhost:9200/twitter/_alias/my_search_indices"
curl -s -X GET "http://localhost:9200/_cat/aliases"
开始执行 split 切分索引的操作,调整后索引名称为new_twitter,且主shard数量为8
curl -s -X POST "http://localhost:9200/twitter/_split/new_twitter?pretty" -H 'Content-Type: application/json' -d '{
"settings": {
"index.number_of_shards": 8,
"index.number_of_replicas": 0
}
}'
# 对新的index添加alias
curl -s -X POST "http://localhost:9200/_aliases?pretty" -H 'Content-Type: application/json' -d '{
"actions" : [
{ "add" : { "index" : "new_twitter", "alias" : "my_search_indices" } }
]
}'
第二种方式:
# 新建索引别名
curl -s -X PUT "http://localhost:9200/new_twitter/_alias/my_search_indices"
结果:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "new_twitter"
}
补充:
查看split的进度,可以使用 _cat/recovery 这个api, 或者在 cerebro 界面上查看。
查看新索引的数据,能正常查看
curl -s -XGET "http://localhost:9200/my_search_indices/_search" | jq .
查看split的进度,可以使用 _cat/recovery 这个api, 或者在 cerebro 界面上查看。
curl -s -X GET "http://localhost:9200/_cat/recovery"
# 对新索引写数据测试,可以看到失败的
curl -s -X PUT "localhost:9200/my_search_indices/_doc/33?pretty" -H 'Content-Type: application/json' -d '{
"id": 33,
"name":"amd",
"age":"33"
}'
# 写入失败
# 打开索引的写功能
curl -s -X PUT "localhost:9200/my_search_indices/_settings?pretty" -H 'Content-Type: application/json' -d '{
"settings": {
"index.blocks.write": false
}
}'
# 再次对新索引写数据测试,可以看到此时,写入是成功的
curl -s -X PUT "localhost:9200/my_search_indices/_doc/33?pretty" -H 'Content-Type: application/json' -d '{
"id": 33,
"name":"amd",
"age":"33"
}'
curl -s -X PUT "localhost:9200/my_search_indices/_doc/44?pretty" -H 'Content-Type: application/json' -d '{
"id": 44,
"name":"intel",
"age":"4"
}'
# 此时,老的那个索引还是只读的,我们确保新索引OK后,就可以考虑关闭或者删除老的 twitter索引了。
测试将新数据写入别名
curl -s -X PUT "localhost:9200/my_search_indices/_doc/44?pretty" -H 'Content-Type: application/json' -d '{
"id": 44,
"name":"amd",
"age":"44"
}'
写入也是ok 的
删除索引
curl -s -X DELETE "http://localhost:9200/new_twitter"
总结
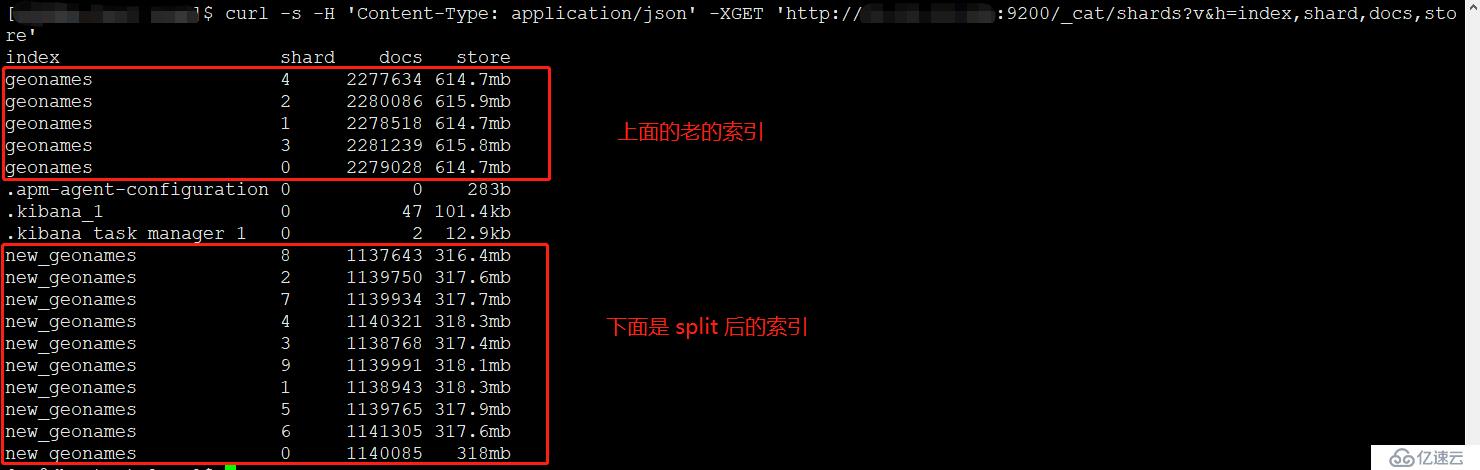
贴一张 生产环境执行后的index的截图,可以看到新的index的每个shard体积只有老index的一半,这样也就分摊了index的压力:
ES ElasticSearch 7.x 下动态扩大索引的shard数量的更多相关文章
- [ES]Elasticsearch在windows下的安装
1.环境 win7 64位 2.下载包环境 https://www.elastic.co/cn/downloads/elasticsearch 选择对应安装包 3.安装过程 解压安装包,例如我的,解压 ...
- ElasticSearch入门 第三篇:索引
这是ElasticSearch 2.4 版本系列的第三篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- ES(ElasticSearch)学习总结
基本概念 一个分布式多用户能力的全文搜索引擎,基于RESTful web接口. Elasticsearch和MongoDB/Redis/Memcache一样,是非关系型数据库.是一个接近实时的搜索平台 ...
- Elasticsearch从入门到放弃:索引基本使用方法
前文我们提到,Elasticsearch的数据都存储在索引中,也就是说,索引相当于是MySQL中的数据库.是最基础的概念.今天分享的也是关于索引的一些常用的操作. 创建索引 curl -X PUT & ...
- 大数据-es(elasticsearch)
elasticsearch elasticsearch是lucene作为核心的实时分布式检索,底层使用倒排索引实现. 倒排索引原理 索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址.由于不 ...
- [ES]elasticsearch章5 ES的分词(二)
Elasticsearch 中文搜索时遇到几个问题: 当搜索关键词如:“人民币”时,如果分词将“人民币”分成“人”,“民”,“币”三个单字,那么搜索该关键词会匹配到很多包含该单字的无关内容,但是如果将 ...
- Elasticsearch Docker环境下安装
Elasticsearch Docker环境下安装 Daemon镜像配置的是https://registry.docker-cn.com Linux:vi /etc/docker/daemon.jso ...
- 【原创】《从0开始学Elasticsearch》—集群健康和索引管理
内容目录 1.搭建Kibana2.集群健康3.索引操作 1.搭建Kibana 正如<Kibana 用户手册>中所介绍,Kibana 是一款开源的数据分析和可视化平台,因此我们可以借助 Ki ...
- elasticsearch 集群、节点、索引、分片、副本概念
原文链接: https://www.jianshu.com/p/297e13045605 集群(cluster): 由一个或多个节点组成, 并通过集群名称与其他集群进行区分 节点(node): 单个 ...
随机推荐
- Java基础—控制流程语句(条件语句与循环结构)
与任何程序设计语言一样,Java使用条件语句和循环结构确定控制流程.Java的控制流程结构与C和C++的控制流程机构一样,只有很少的例外情况.没有goto语句,但break语句可以带标签,可以利用它实 ...
- 十多位全球技术专家,为你献上近十个小时的.Net微服务介绍
.Net Conf: Focus on Microservices 是 .Net Conf 社区在 2020 年 7 月 30 日举办的线上分享活动.整个活动视频长达近 10 个小时.今天我们来看看都 ...
- 2020-04-13:TCP协议本身会导致什么样的安全问题?
福哥答案2020-04-14: 洪泛攻击
- VSCode 自定义Vue snippets, 快速生成Vue模板
命令行 Ctrl+Shift+P # 选择 Configure User Snippets # 选择 Vue.json 原始的Vue.json { // Place your snippets for ...
- golang中type关键字使用
type关键字使用 type是go语法里的重要而且常用的关键字,type绝不只是对应于C/C++中的typedef.搞清楚type的使用,就容易理解go语言中的核心概念struct.interface ...
- 了解JS压缩图片,这一篇就够了
前言 公司的移动端业务需要在用户上传图片是由前端压缩图片大小,再上传到服务器,这样可以减少移动端上行流量,减少用户上传等待时长,优化用户体验. 插播一下,本文案例已整理成插件,已上传npm ,可通过 ...
- 关于Exceptionless日志收集框架会被Fiddler抓包,从而获取到ApiKey的问题
关于Exceptionless日志收集框架会被Fiddler抓包,从而获取到ApiKey的问题 环境:Exceptionless5.0.0.Linux.WPF客户端.Fiddler 问题:在使用Exc ...
- Vue3.0数据响应式原理
在vue2版本中响应式使用的是ES5对象的操作,通过遍历对象Object.defineProperty属性值的变化,实现监听数据 在3.0中使用的ES6版本的Proxy代理对象方式来实现数据的监听,省 ...
- markdown使用手册
github上找到了一个挺全面的项目,mark一下. https://github.com/nicejade/nice-front-end-tutorial/blob/master/tutorial/ ...
- Java多线程_并发容器ConcurrentHashMap/CopyOnWriteArrayList/CopyOnWriteArraySet
ConcurrentHashMap HashMap是线程不安全的,可以使用Collections.synchronizedMap(map)把一个不安全的map变成安全的,但是这里可以直 ...