Cassandra架构、设计(集群&表)和性能报告
系统架构:
Cassandra 是 一 套 开 源 分 布 式 No -SQL 数据库系统, 基于一致性哈希算法的 P2P 环形结构。 这种结构 各节点功能完全相 同, 可灵活添加节点来完成系 统的扩充或删除节点, 且无需大规模转移数据, 同 时彻底避免系 统因 单点故障
导致的不稳定性; 每个节点通过 Gossip 机制进行消息同步; 每 个 数据 项 都 会 被 复 制 到 N 个节 点( N 是通过参数配置的副本因 子), 系 统利 用 数据
的复制机将存储在各节点上的数据复制到其他节点上, 实现了数据的高度可获得性与安全性。
数据模型:
Cassandra 使用 宽 列 存 储 模 型, 每 行 数 据 记录是以 Key - Value 形式进行存储, 其中 Key为 唯一标识。 每 个Key- Value 其 中 的 Value 也 称 为Column, 作 为 一 个 三 元 组, 包 含 有
Column Name 、 Column Value 与 timestamp ; 每 个 CF 由一个 Key及其对应的若干个 Column 标识组成。一个
keyspace 包含若干 个 CF , 类似关系 型数据库中一个
database 可有 多 个table 。
下 图 为 一 个Column 型数据模型。

CPA理论:
NoSQL 典 型 遵 循 由 Eric Brewer 提 出 的CAP 理论 , 依据此理论, 在一个大规模的分布式数据系统中, 有三个需求是彼此循环依赖的, 一致性( consistency ) 、 可 用 性 ( availability ) 、 分 区 耐受性( partition tolerance ) 。
一致性: 对所有数据库客户 端 使 用 同 样 查 询 都 可 得 到 相 同 的 数 据;
可用性: 所 有 数 据 库 客 户 端 都 可 读 写 数 据;
分区耐受性: 数 据 库 分 散 到 多 个 服 务 器 上, 即使发生 网 络 故 障, 仍 可 提 供 服 务。
CAP 理 论 可简单描述 为 :
一 个 分 布 式 系 统 不 能 同 时 满 足 以上三个 特 性, 最 多 只 能 同 时 满 足 两 个。
Cassandra 主要支持 可 用 性 和 分 区 耐 受 性。
在 Cassandra 中 , 数据 具 备 最 终 一 致 性, 集 群 整 体 的 完 全
可用 性。
存储机制
Cassandra 依赖本地的文件系统通过内存与磁盘的双重存储机制来保证数 据的持久性 。
Cassandra 有三 个重 要 的 数 据 结 构, 记录 于 内 存
的 Memtable , 保 存 在 磁 盘 中 的 Commit Log和
SSTable 。
Memtable 记 录 最 近 的 修 改, 而SSTable 记录着数据库 所承载的 绝大部分数据。通常 情 况 下, 一 个 Cassandra 表 会 对 应 着 一 个
Memtable 和多 个SSTable 。
Cassandra 接收到 客户端发送来的数据, 首先将写操作记录到 位于磁
盘的 CommitLog 中; 上述操作成功 后, 更新位于内存中 的 Memtable 数 据 结 构。 持 续 的 写 入 数据, 使得 Memtable 逐渐增长, 当 其数据量到 达某个阈 值时, Cassandra 的数据迁移被触发, 一 方面将
Memtable 刷 写 到 本 地 磁 盘 上 成 为 永 久 的SSTable , 另一方面将 CommitLog 中 的 写 入记录移除。 对于读操作, 客 户 端 先 查 询
Memtable 中的数据, 若无法获取所需信息, 则 检索本地磁盘。
Cassandra 会定期执行压紧compact 操作, 将同一条数据不同的版本进行合并, 过时数据也会在此过程中被删除; 分层数据压缩, 有效减少数据体积
及磁盘 I / O 。
系统设置(集群)
针对实时气象数据存储系统, 用户对该系统读取的性能需求远远高于写入数据。 通过对副本数进行合理设置, 可分散读取压力 。 对于5 节点集群, 将副本数设置为 3 ;
Row 分区 模式:
采用自动分区方式, 使不同的 Row Key 均匀分布在各节点上, 有利于数据读取压力的分散。
Cassandra 表设计
作为典型的非结构化数据,气象数据可以由多维索引 来确定一个唯一的数据。
业务用户常见的操作包括“最新数据”“左右翻页”“上下翻页”等。
数据表
根据不同数据类型建立相应数据表, 用于存储数据内容, 包括:
ECMWFHR(高分辨率数值预报产品 )、
SATELLITE ( 卫 星 资料)、
UPPERAIR (高空站点资料)、
SINGLERADAR (雷达资料) 等。
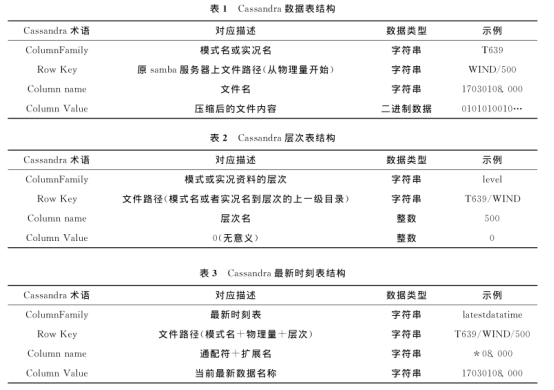
以“ T639 ”为 例 说明 数据表结构(表 1 )。
建表 语 句: CREATE TABLE "T639 "
( "dataPath " text , column1 text ,
value blob , PRIMARY KEY (" dataPath " ,
column1 ) ) ;
层次表
用于存储所有模式或实况的层次信息, 表名为level ; 用 户 在 客户 端进行上下翻页操作, 从level 表中获取当前层次的上一层或下一层信息; 利用层次表与数据表, 可检索到不同层次的数据(表2 )。
建表语 句: CREATE TABLE level (
"dataPath " text , column1 int , value int , PRIMARY KEY (" dataPath " , column1 )) ;
最新时刻表
用于存储各类数据的最新时刻信息, 表名 为latestdatatime 。 利 用 最新时刻表, 用户能通过客户端快速查找到最新数据文件名。 用户根据完整索引 (文件路径与最新数据文件名), 例: T639 / WIND / 500 / 17030108. 000 , 即可在“数据表”中获取到对应数据(表 3 )。
建表语句: CREATE TABLE latestdatatime
( " dataPath " text , column1 text , value text ,PRIMARY KEY (" dataPath " , column1 )) ;
存储系统性能测试
测试环境
选用5台相同配置的服务器用来搭建分布式存储系统。 服 务 器 操作 系 统 为 Red Hat Enter -prise Linux Server release 7. 1 , 处理器参数为Intel ( R ) Xeon ( R ) CPU E5 - 2620 v2 @ 2. 10GHz , 主频为2. 1 GHz ; 内 存大小为 256 GB ;6 块4TB SATA 硬盘; 服务器间通过万兆光纤连接。Cassandra 数据库版本为2. 2. 5 。
高可用性测试
由 5 个节点所组成分布式存储系统, 其结构上具有如下特点。
( 1 )服务器双网卡绑定, 即将两个物理网卡虚拟成一个逻辑网卡; 提升服务器之间的传输带宽,实现网卡冗余。
( 2 )用于集群内部数据交换的两台万兆光纤交换机, 采取级联方式, 可互为备份。
( 3 ) 6 块SATA 硬盘, 其中 2 块做 RAID1, 安装操作 系 统 及 软 件; 另 外 4 块 4TB 用 作 两 个RAID0 , 用于存储数据。
( 4 )服务器集群为环形结构, 没有 master 节点, 各节点功能完全一样。
按照表4中内容, 对系统的基础设施层(包括网络设备、存储设备等)、 软件层(数据库) 进行测试, 来验证系统的高可用 性; 从表中结论可知, 系统中用于内部数据交换的光纤或网卡、交换机及任一 Cassandra 服务器故障, 均不影响 MICAPS4客户端调取数据。

读取性能测试
通过读取数据的脚本文件(可获取数据字节数信息, 表5中 ECMWF _ HR / TMP / 100 目 录下数 据 字 节 数 为 132642 字 节, SATELLITE /
FY2E / L1 / IR3 / EQUAL 下数据字节数为554944字节,
T639 / WIND / 100 下数据字节数为1449052字节), 模拟单用户及50 用 户 、 100 用 户 客户 端对同一类型数据进行读取, 共分 3 组, 即对三种不同类型的数据进行测试, 测试性能见表5 , 注意测试结果包含网络传输时间。
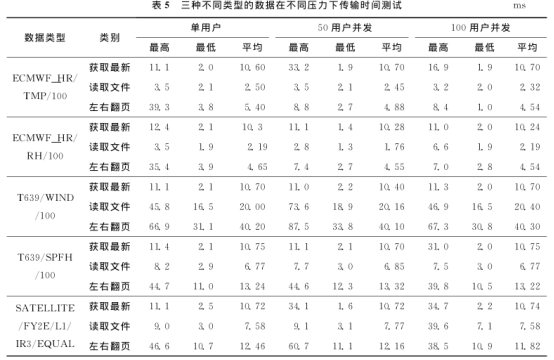
从数据读取的测试结果可以看出 :
( 1 )50 用户并发和100 用 户 并发 客户 端 同 时 对 同 一 类 型数据进行 读 取 的 时 间 与 单 用 户 读 取 时 间 相 当 。以 T639 / WIND/100 为 例, 50 用 户 并 发 和 100用 户 并发与单用 户 读取相 关数据 所 花 费 的 平 均时间 均在20 ms 左右。
( 2 ) 在100 用 户 并发情况下, 从数据库 中 调 取数据 所消 耗 的 时 间 均 以 ms量级为 单 位 ( 包 含 网 络 传 输 时 间 ) , 时 间 远 远 小于在samba 服 务 器 上 读 取 数 据 的 时 间 。
( 3) 数据读取时 间 和 单 个 数 据 的 字 节 数 近 似 成 正 比,即单个数 据 文 件 字 节 数 越 大, 读 取 数 据 所 花 费的时间 则 越长。
结语
利用 Cassandra 分布式数据库搭建的存储环境, 提高了实时气象数据存储效率与检索速度, 通过统一的数据平台, 实现了运维人员对该系统“零”维护。 通过在实际业务环境中进行测试, 验证了该分布式数据环境的高可用性; 以毫秒级为单位的数据读取时间, 能很好地满足业务对数据时效性的需求。
Cassandra架构、设计(集群&表)和性能报告的更多相关文章
- Docker Swarm和Kubernetes在大规模集群中的性能比较
Contents 这篇文章主要针对Docker Swarm和Kubernetes在大规模部署的条件下的3个问题展开讨论.在大规模部署下,它们的性能如何?它们是否可以被批量操作?需要采取何种措施来支持他 ...
- 腾讯云Elasticsearch集群规划及性能优化实践
一.引言 随着腾讯云 Elasticsearch 云产品功能越来越丰富,ES 用户越来越多,云上的集群规模也越来越大.我们在日常运维工作中也经常会遇到一些由于前期集群规划不到位,导致后期业务增长集群 ...
- ABP架构设计交流群-上海线下交流会的内容分享(有高清录像视频的链接)
点这里进入ABP系列文章总目录 ABP架构设计交流群-7月18日上海线下交流会内容分享 因为最近工作特别忙,很久没有更新博客了,真对不起关注我博客和ABP系列文章的朋友! 原计划在7月11日举行的AB ...
- 庐山真面目之四微服务架构Consul集群和Nginx版本实现
庐山真面目之四微服务架构Consul集群和Nginx版本实现 一.简介 在上一篇文章<庐山真面目之三微服务架构Consul版本实现>中,我们已经探讨了如何搭建基于单节点Consu ...
- 庐山真面目之六微服务架构Consul集群、Ocelot网关集群和Nginx版本实现
庐山真面目之六微服务架构Consul集群.Ocelot网关集群和Nginx版本实现 一.简介 在上一篇文章<庐山真面目之五微服务架构Consul集群.Ocelot网关和Nginx版本实 ...
- 庐山真面目之七微服务架构Consul集群、Ocelot网关集群和IdentityServer4版本实现
庐山真面目之七微服务架构Consul集群.Ocelot网关集群和IdentityServer4版本实现 一.简介 在上一篇文章<庐山真面目之六微服务架构Consul集群.Ocelot网 ...
- java架构师负载均衡、高并发、nginx优化、tomcat集群、异步性能优化、Dubbo分布式、Redis持久化、ActiveMQ中间件、Netty互联网、spring大型分布式项目实战视频教程百度网盘
15套Java架构师详情 * { font-family: "Microsoft YaHei" !important } h1 { background-color: #006; ...
- Hadoop架构及集群
Hadoop是一个由Apache基金会所开发的分布式基础架构,Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了 ...
- JAVA架构师眼中的高并发架构,分布式架构 应用服务器集群
前言 高并发经常会发生在有大活跃用户量,用户高聚集的业务场景中,如:秒杀活动,定时领取红包等. 为了让业务可以流畅的运行并且给用户一个好的交互体验,我们需要根据业务场景预估达到的并发量等因素,来设计适 ...
随机推荐
- EasyExcel的基本使用方法
在Java语言领域,说到Excel处理工具,大家首先想到的可能是阿帕奇的poi,poi在处理数据量不大的excel文件上确实非常强大,但是随着后来excel从03(一个excel文件中最多有65536 ...
- IndexFlatL2、IndexIVFFlat、IndexIVFPQ三种索引方式示例
上文针对Faiss安装和一些原理做了简单说明,本文针对标题所列三种索引方式进行编码验证. 首先生成数据集,这里采用100万条数据,每条50维,生成数据做本地化保存,代码如下: import numpy ...
- PMP各种图比较记忆
1.控制图:监控过程是否稳定,是否具有可预测的绩效,在问题还未发生时解决.需要关注控制图中的平均值.控制界限.规格界限的含义.控制上.下限一般设为±3个西格玛.过程失控的情况包括数据点在控制界限外,以 ...
- 使用Tensorflow搭建自编码器(Autoencoder)
自编码器是一种数据压缩算法,其中数据的压缩和解压缩函数是数据相关的.从样本中训练而来的.大部分自编码器中,压缩和解压缩的函数是通过神经网络实现的. 1. 使用卷积神经网络搭建自编码器 导入MNIST数 ...
- 洛谷P1036.选数(DFS)
题目描述 已知 n个整数 x1,x2,-,xn,以及11个整数k(k<n).从n个整数中任选k个整数相加,可分别得到一系列的和.例如当n=4,k=3,4个整数分别为3,7,12,19时,可得全部 ...
- 调试备忘录-RS485 MODBUS RTU协议简述
目录--点击可快速直达 目录 写在前面 先简单说下什么是MODBUS? 参考文章 写在前面 最近在做和物联网有关的小项目,有一个传感器通讯用到了RS485 MODBUS RTU协议,所以就写个随笔记录 ...
- 设计模式:桥接模式及代码示例、桥接模式在jdbc中的体现、注意事项
0.背景 加入一个手机分为多种款式,不同款式分为不同品牌.这些详细分类下分别进行操作. 如果传统做法,需要将手机,分为不同的子类,再继续分,基本属于一个庞大的多叉树,然后每个叶子节点进行相同名称.但是 ...
- 很挫的 SHFileOperation 用法 2011-07-18 11:42
今天编写一个局域网文件拷贝的demo .其中有一个 SHFileOperation 的用法,这个函数有个参数SHFILEOPSTRUCT.查看msdn有如下解释: pFromAddress of a ...
- 为什么?为什么?Java处理排序后的数组比没有排序的快?想过没有?
先看再点赞,给自己一点思考的时间,微信搜索[沉默王二]关注这个有颜值却假装靠才华苟且的程序员.本文 GitHub github.com/itwanger 已收录,里面还有我精心为你准备的一线大厂面试题 ...
- 输入url后的加载过程~
1)查找域名对应的IP地址: 2)建立连接(TCP的三次握手): 3)构建网页: 4)断开连接(TCP的四次挥手): TCP的三次握手:为了准确无误的把数据送到目标处,TCP协议采用了三次握手策略,用 ...