大数据开发-Spark-初识Spark-Graph && 快速入门
1.Spark Graph简介
GraphX 是 Spark 一个组件,专门用来表示图以及进行图的并行计算。GraphX 通过重新定义了图的抽象概念来拓展了 RDD: 定向多图,其属性附加到每个顶点和边。为了支持图计算, GraphX 公开了一系列基本运算符(比如:mapVertices、mapEdges、subgraph)以及优化后的 Pregel API 变种。此外,还包含越来越多的图算法和构建器,以简化图形分析任务。GraphX在图顶点信息和边信息存储上做了优化,使得图计算框架性能相对于原生RDD实现得以较大提升,接近或到达 GraphLab 等专业图计算平台的性能。GraphX最大的贡献是,在Spark之上提供一栈式数据解决方案,可以方便且高效地完成图计算的一整套流水作业。
图计算的模式:
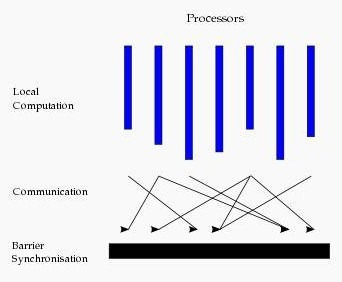
基本图计算是基于BSP的模式,BSP即整体同步并行,它将计算分成一系列超步的迭代。从纵向上看,它是一个串行模式,而从横向上看,它是一个并行的模式,每两个超步之间设置一个栅栏(barrier),即整体同步点,确定所有并行的计算都完成后再启动下一轮超步。
每一个超步包含三部分内容:
计算compute:每一个processor利用上一个超步传过来的消息和本地的数据进行本地计算
消息传递:每一个processor计算完毕后,将消息传递个与之关联的其它processors
整体同步点:用于整体同步,确定所有的计算和消息传递都进行完毕后,进入下一个超步
2.来看一个例子
图描述
## 顶点数据
1, "SFO"
2, "ORD"
3, "DFW"
## 边数据
1, 2,1800
2, 3, 800
3, 1, 1400
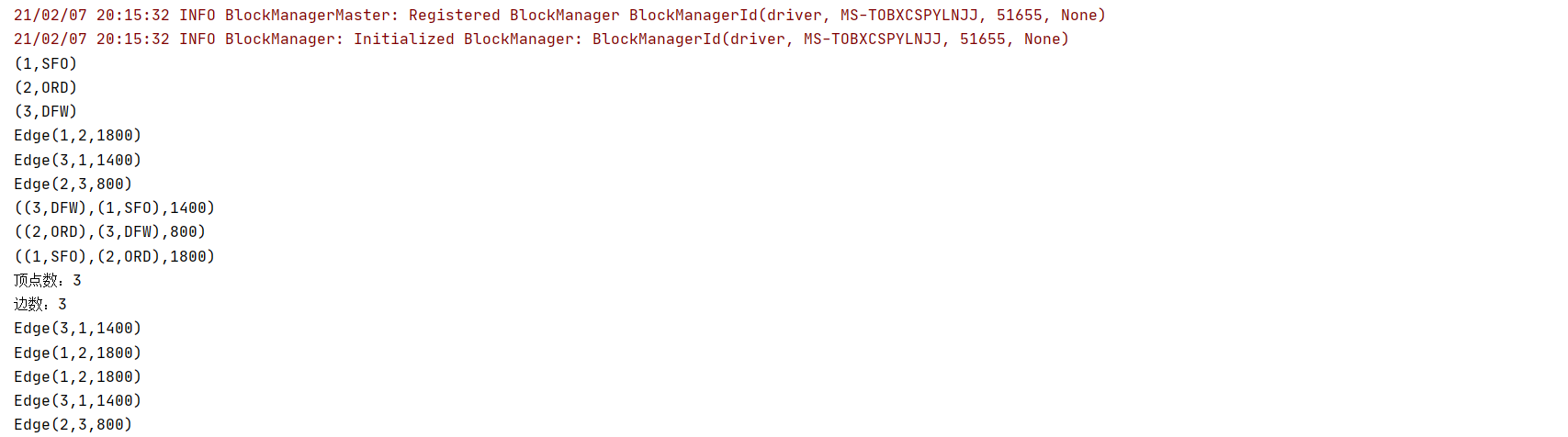
计算所有的顶点,所有的边,所有的triplets,顶点数,边数,顶点距离大于1000的有那几个,按顶点的距离排序,降序输出
代码实现
package com.hoult.Streaming.work
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
object GraphDemo {
def main(args: Array[String]): Unit = {
// 初始化
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("warn")
//初始化数据
val vertexArray: Array[(Long, String)] = Array((1L, "SFO"), (2L, "ORD"), (3L, "DFW"))
val edgeArray: Array[Edge[Int]] = Array(
Edge(1L, 2L, 1800),
Edge(2L, 3L, 800),
Edge(3L, 1L, 1400)
)
//构造vertexRDD和edgeRDD
val vertexRDD: RDD[(VertexId, String)] = sc.makeRDD(vertexArray)
val edgeRDD: RDD[Edge[Int]] = sc.makeRDD(edgeArray)
//构造图
val graph: Graph[String, Int] = Graph(vertexRDD, edgeRDD)
//所有的顶点
graph.vertices.foreach(println)
//所有的边
graph.edges.foreach(println)
//所有的triplets
graph.triplets.foreach(println)
//求顶点数
val vertexCnt = graph.vertices.count()
println(s"顶点数:$vertexCnt")
//求边数
val edgeCnt = graph.edges.count()
println(s"边数:$edgeCnt")
//机场距离大于1000的
graph.edges.filter(_.attr > 1000).foreach(println)
//按所有机场之间的距离排序(降序)
graph.edges.sortBy(-_.attr).collect().foreach(println)
}
}
输出结果
3.图的一些相关知识
例子是demo级别的,实际生产环境下,如果使用到必然比这个复杂很多,但是总的来说,一定场景才会使用到吧,要注意图计算情况下,要注意缓存数据,RDD默认不存储于内存中,所以可以尽量使用显示缓存,迭代计算中,为了获得最佳性能,也可能需要取消缓存。默认情况下,缓存的RDD和图保存在内存中,直到内存压力迫使它们按照LRU【最近最少使用页面交换算法】逐渐从内存中移除。对于迭代计算,先前的中间结果将填满内存。经过它们最终被移除内存,但存储在内存中的不必要数据将减慢垃圾回收速度。因此,一旦不再需要中间结果,取消缓存中间结果将更加有效。这涉及在每次迭代中实现缓存图或RDD,取消缓存其他所有数据集,并仅在以后的迭代中使用实现的数据集。但是,由于图是有多个RDD组成的,因此很难正确地取消持久化。对于迭代计算,建议使用Pregel API,它可以正确地保留中间结果。
吴邪,小三爷,混迹于后台,大数据,人工智能领域的小菜鸟。
更多请关注

大数据开发-Spark-初识Spark-Graph && 快速入门的更多相关文章
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 大数据开发,Hadoop Spark太重?你试试esProc SPL
摘要:由于目标和现实的错位,对很多用户来讲,Hadoop成了一个在技术.应用和成本上都很沉重的产品. 本文分享自华为云社区<Hadoop Spark太重,esProc SPL很轻>,作者: ...
- Hadoop大数据学习视频教程 大数据hadoop运维之hadoop快速入门视频课程
Hadoop是一个能够对大量数据进行分布式处理的软件框架. Hadoop 以一种可靠.高效.可伸缩的方式进行数据处理适用人群有一定Java基础的学生或工作者课程简介 Hadoop是一个能够对大量数据进 ...
- 大数据为什么要选择Spark
大数据为什么要选择Spark Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析. Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- Spark—初识spark
Spark--初识spark 一.Spark背景 1)MapReduce局限性 <1>仅支持Map和Reduce两种操作,提供给用户的只有这两种操作 <2>处理效率低效 Map ...
- 详解Kafka: 大数据开发最火的核心技术
详解Kafka: 大数据开发最火的核心技术 架构师技术联盟 2019-06-10 09:23:51 本文共3268个字,预计阅读需要9分钟. 广告 大数据时代来临,如果你还不知道Kafka那你就真 ...
- 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
点击上方 蓝字关注我们 作者 | 宋哲琦 ✎ 编 者 按 在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统 ...
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
- 大数据开发实战:Stream SQL实时开发一
1.流计算SQL原理和架构 流计算SQL通常是一个类SQL的声明式语言,主要用于对流式数据(Streams)的持续性查询,目的是在常见流计算平台和框架(如Storm.Spark Streaming.F ...
随机推荐
- Linux三剑客grep、awk和sed
grep,sed 和 awk是Linux/Unix 系统中常用的三个文本处理的命令行工具,称为文本处理三剑客.本文将简要介绍这三个命令并给出基本用法. 管道 在介绍这两个命令之前,有必要介绍一下Uni ...
- LeetCode700. 二叉搜索树中的搜索
题目 简单递归 1 class Solution { 2 public: 3 TreeNode* searchBST(TreeNode* root, int val) { 4 if(!root) re ...
- LeetCode108.有序数组转二叉搜索树
题目 1 class Solution { 2 public: 3 TreeNode* sortedArrayToBST(vector<int>& nums) { 4 if(num ...
- 利用iptables防火墙保护web服务器
实例:利用iptables防火墙保护web服务器 防火墙--->路由器-->交换机-->pc机 配置之前,清空下已有的规则,放在规则冲突不生效 工作中,先放行端口写完规则,再DROP ...
- 使用axis1.4生成webservice的客户端代码
webservice服务端: https://blog.csdn.net/ghsau/article/details/12714965 跟据WSDL文件地址生成客服端代码: 1.下载 axis1.4 ...
- 写给 Linux 初学者的一封信
大家好,我是肖邦. 这篇文章是写给 Linux 初学者的,我会分享一些作为初学者应该知道的一些东西,这些内容都是本人从事 Linux 开发工作多年的心得体会,相信会对初学者有所帮助.如果你是 Linu ...
- 生僻标签 fieldset 与 legend 的妙用
谈到 <fieldset> 与 <legend>,大部分人肯定会比较陌生,在 HTML 标签中,属于比较少用的那一批. 我最早知道这两个标签,是在早年学习 reset.css ...
- Databricks 第9篇:Spark SQL 基础(数据类型、NULL语义)
Spark SQL 支持多种数据类型,并兼容Python.Scala等语言的数据类型. 一,Spark SQL支持的数据类型 整数系列: BYTE, TINYINT:表示1B的有符号整数 SHORT, ...
- Py-re正则模块,log模块,config模块,哈希加密
9.re正则表达式模块,用于字符串的模糊匹配 元字符: 第一:点为通配符 用.表示匹配除了换行符以外的所有字符 import re res=re.findall('a..x','adsxwassxdd ...
- vercel是什么神仙网站?
Vercel? vercel是我用过的最好用的网站托管服务.本网站就是基于hexo引擎模板开发,托管在vercel上的. vercel类似于github page,但远比github page强大,速 ...