spark使用jdbc批次提交方式写入phoniex的工具类
一、需求:spark写入phoniex
二、实现方式
1.官网方式
dataFrame.write
.format("org.apache.phoenix.spark")
.mode("overwrite")
.option("table", table)
.option("zkUrl", zkUrl)
.option("skipNormalizingIdentifier", true)
.save()
这个方式底层是使用MapReduce的RecordWriter实现类PhoenixRecordWriter通过jdbc方式写入
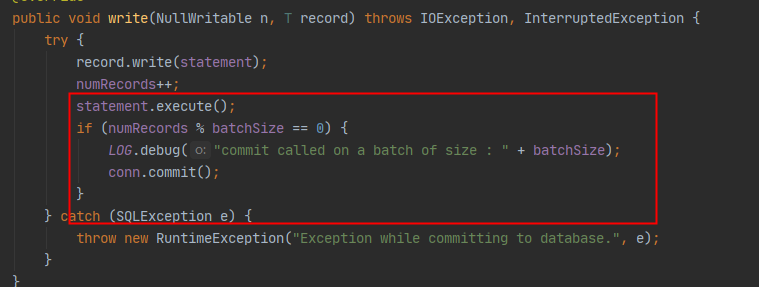
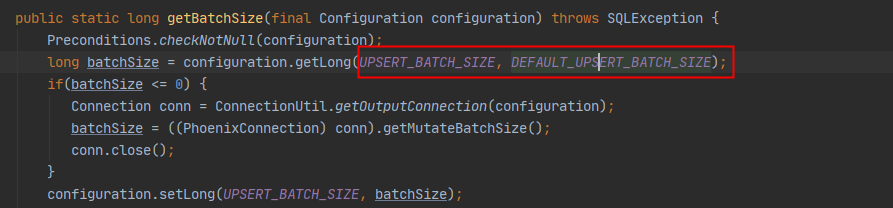
但是默认的batchsize是1000,所以插入速度极慢,但是官网没有说明写入的参数设置,需要去源码里面寻找一下
所以可以通过设置参数来提升速度
.option(PhoenixConfigurationUtil.UPSERT_BATCH_SIZE,batch)
二、自己实现jdbc的通用方式(任何jdbc方式都可以写入)
代码:
object JdbcUtils {
def jdbcBatchInsert(dataFrame: DataFrame, table: String, url: String, pro: Properties, batch: Int): Unit = {
val fields: Array[String] = dataFrame.schema.fieldNames
val schema: Array[StructField] = dataFrame.schema.toArray
val numFields = fields.length
val fieldsSql = fields.map(str => "\"".concat(str).concat("\"")).mkString("(", ",", ")")
val charSql = fields.map(str => "?").mkString(",")
val setters: Array[JDBCValueSetter] = schema.map(f => makeSetter(f.dataType))
val insertSql = s"upsert into $table $fieldsSql values ($charSql) "
System.err.println("插入sql:" + insertSql)
val start = System.currentTimeMillis()
dataFrame.rdd.foreachPartition(partition => {
val connection = DriverManager.getConnection(url, pro)
try {
connection.setAutoCommit(false)
val pstmt: PreparedStatement = connection.prepareStatement(insertSql)
var count = 0
var cnt = 0
partition.foreach(row => {
for (i <- 0 until numFields) {
if (row.isNullAt(i)) {
pstmt.setNull(i + 1, getJdbcType(schema(i).dataType))
} else {
setters(i).apply(pstmt, row, i)
}
}
pstmt.addBatch()
count += 1
if (count % batch == 0) {
pstmt.executeBatch()
connection.commit()
cnt += 1
println(s"${TaskContext.get.partitionId}分区,提交第${cnt}次,${count}tiao")
}
})
pstmt.executeBatch()
connection.commit()
println(s"第${TaskContext.get.partitionId}分区,共提交第${cnt},${count}条")
} finally {
connection.close()
}
})
val end = System.currentTimeMillis()
println(s"插入表$table,共花费时间${(end - start) / 1000}秒")
}
private type JDBCValueSetter = (PreparedStatement, Row, Int) => Unit
/**
* 类型匹配 如果有其他类型 自行添加
*
* @param dataType
* @return
*/
def makeSetter(dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
if (row.isNullAt(pos)) {
stmt.setNull(pos + 1, java.sql.Types.INTEGER)
} else {
stmt.setInt(pos + 1, row.getInt(pos))
}
case LongType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setLong(pos + 1, row.getLong(pos))
case DoubleType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setDouble(pos + 1, row.getDouble(pos))
case FloatType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setFloat(pos + 1, row.getFloat(pos))
case ShortType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setInt(pos + 1, row.getShort(pos))
case ByteType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setInt(pos + 1, row.getByte(pos))
case BooleanType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setBoolean(pos + 1, row.getBoolean(pos))
case StringType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setString(pos + 1, row.getString(pos))
case BinaryType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos))
case TimestampType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos))
case DateType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos))
case t: DecimalType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setBigDecimal(pos + 1, row.getDecimal(pos))
/* case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase(Locale.ROOT).split("\\(")(0)
(stmt: PreparedStatement, row: Row, pos: Int) =>
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos).toArray)
stmt.setArray(pos + 1, array)*/
case _ =>
(_: PreparedStatement, _: Row, pos: Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}
/**
* sql类型匹配 如果有其他类型 自行添加
*
* @param dt
* @return
*/
private def getJdbcType(dt: DataType): Int = {
dt match {
case IntegerType => java.sql.Types.INTEGER
case LongType => java.sql.Types.BIGINT
case DoubleType => java.sql.Types.DOUBLE
case StringType => java.sql.Types.VARCHAR
case _ => java.sql.Types.VARCHAR
}
}
}
测试:
#config是个map集合要不要都可以
val connectionProperties = new Properties();
connectionProperties.setProperty(QueryServices.MAX_MUTATION_SIZE_ATTRIB, config.getOrDefault("phoenix.mutate.maxSize", "500000")); //改变默认的500000
connectionProperties.setProperty(QueryServices.MUTATE_BATCH_SIZE_BYTES_ATTRIB, config.getOrDefault("phoenix.mutate.batchSizeBytes", "1073741824000")) val batch = config.getOrDefault("phoenix.insert.batchSize", "50000").toInt //调用插入方法
JdbcUtils.jdbcBatchInsert(dataFrame, table, phoenixUrl, connectionProperties, batch);
spark使用jdbc批次提交方式写入phoniex的工具类的更多相关文章
- Java中常用的加密方式(附多个工具类)
一.Java常用加密方式 Base64加密算法(编码方式) MD5加密(消息摘要算法,验证信息完整性) 对称加密算法 非对称加密算法 数字签名算法 数字证书 二.分类按加密算法是否需要key被分为两类 ...
- 【JDBC】学习路径5-提取JDBCUtils工具类
回顾我们上面几节的内容,我们发现重复代码非常多,比如注册驱动.连接.关闭close()等代码,非常繁杂. 于是我们将这些重复的大段代码进行包装.提取成JDBCUtils工具类. 第一章:提取注册连接模 ...
- Spark jdbc postgresql数据库连接和写入操作源码解读
概述:Spark postgresql jdbc 数据库连接和写入操作源码解读,详细记录了SparkSQL对数据库的操作,通过java程序,在本地开发和运行.整体为,Spark建立数据库连接,读取数据 ...
- Spark Standalone与Spark on YARN的几种提交方式
不多说,直接上干货! Spark Standalone的几种提交方式 别忘了先启动spark集群!!! spark-shell用于调试,spark-submit用于生产. 1.spark-shell ...
- Spark jdbc postgresql数据库连接和写入操作源代码解读
概述:Spark postgresql jdbc 数据库连接和写入操作源代码解读.具体记录了SparkSQL对数据库的操作,通过java程序.在本地开发和执行.总体为,Spark建立数据库连接,读取数 ...
- spark之JDBC开发(实战)
一.概述 Spark Core.Spark-SQL与Spark-Streaming都是相同的,编写好之后打成jar包使用spark-submit命令提交到集群运行应用$SPARK_HOME/bin#. ...
- spark之JDBC开发(连接数据库测试)
spark之JDBC开发(连接数据库测试) 以下操作属于本地模式操作: 1.在Eclipse4.5中建立工程RDDToJDBC,并创建一个文件夹lib用于放置第三方驱动包 [hadoop@CloudD ...
- Spark使用jdbc时的并行度
Spark SQL支持数据源使用JDBC从其他数据库读取数据. 与使用JdbcRDD相比,应优先使用此功能. 这是因为结果以DataFrame的形式返回,并且可以轻松地在Spark SQL中进行处理或 ...
- 各种数据库使用JDBC连接的方式
Java数据库连接(JDBC)由一组用 Java 编程语言编写的类和接口组成.JDBC 为工具/数据库开发人员提供了一个标准的 API,使他们能够用纯Java API 来编写数据库应用程序.然而各个开 ...
- spark下使用submit提交任务后报jar包已存在错误
使用spark submit进行任务提交,离线跑数据,提交后的一段时间内可以application可以正常运行.过了一段时间后,就抛出以下错误: org.apache.spark.SparkExcep ...
随机推荐
- Go 调用 Java 方案和性能优化分享
简介: 一个基于 Golang 编写的日志收集和清洗的应用需要支持一些基于 JVM 的算子. 作者 | 响风 来源 | 阿里技术公众号 一 背景 一个基于 Golang 编写的日志收集和清洗的应 ...
- [Py] Python 接口数据用 pandas 高效写入 csv
通过 pandas 把 dict 数据封装,调用接口方法写入 csv 文件. import pandas as pd data = [{"name": "a"} ...
- 批量解压上传SAP Note
最近在做印度GST相关的东西,需要手动给系统实施上百个SAP Note,十分繁琐. 标准事务代码SNOTE只支持每次上传一个Note,逐个上传大量Note会很麻烦,为此摸索出一个批量解压上传的流程,下 ...
- 通俗易懂的KMP理论讲解(含手求Next数组)
通俗易懂的KMP理论讲解(含手求Next数组) 1.KMP算法介绍 KMP算法的核心是利用匹配失败后的信息,通过一个 next 数组,保存模式串中前后最长公共子序列的长度,尽量减少模式串与主串的匹配次 ...
- Linux下Nginx 配置前后端接口
一.编辑nginx.conf配置文件命令 ## /usr/local/nginx/ nginx的安装路径 vim /usr/local/nginx/conf/nginx.conf 二.后端接口配置信息 ...
- ༺$Musique$༻
往期链接在文末 最近好喜欢听一些有年代感的歌啊. ~~头图~~ <$ On\ \And \ On $> Hold me close til I get up Time is barely ...
- 智能工作流:Spring AI高效批量化提示访问方案
基于SpringAI搭建系统,依靠线程池\负载均衡等技术进行请求优化,用于解决科研&开发过程中对GPT接口进行批量化接口请求中出现的问题. github地址:https://github.co ...
- vue3.4中KeepAlive的一个bug
KeepAlive可以缓存组件,在不使用include时没有任何问题,可以正常缓存. 但是一旦使用了include,如果动态组件中没有导入ref函数,缓存功能就消失了 比如 editcom.vue & ...
- echarts下划线实现
echarts中无下划线实现,我采用图片填充文本块背景的方式实现 这是从 长空雁叫霜晨月 的博客中得到启发https://www.cnblogs.com/volodya/p/Echarts.html ...
- Flask简单部署至kubernetes
安装Kubernetes.Docker Kubernetes.Docker安装教程 项目地址 Github Flask flask run.py from flask import Flask imp ...