CeiT:商汤提出结合CNN优势的高效ViT模型 | 2021 arxiv
论文提出CeiT混合网络,结合了CNN在提取低维特征方面的局部性优势以及Transformer在建立长距离依赖关系方面的优势。CeiT在ImageNet和各种下游任务中达到了SOTA,收敛速度更快,而且不需要大量的预训练数据和额外的CNN蒸馏监督,值得借鉴
来源:晓飞的算法工程笔记 公众号
论文: Incorporating Convolution Designs into Visual Transformers

Introduction
在视觉领域中,纯Transformer架构往往需要大量的训练数据或额外的监督来达到与CNN相当的性能。为了克服这些限制,论文对直接使用Transformer架构的潜在缺点进行了分析,发现Transformer主要缺乏了CNN的平移不变性以及局部性。于是,论文将CNN在提取低维特征方面的局部性优势以及Transformer在建立长距离依赖关系方面的优势进行结合,提出了Convolution-enhanced image Transformer(CeiT)混合网络。
论文对原生Transformer做了三处修改:
- 设计了Image-to-Tokens(I2T)模块,从生成的低维特征中提取token序列,而不是将原始输入图像直接分割成token序列。
- 提出Locally-enchanced Feed-Forward(LeFF)层替换每个encoder中的feed-forward层,LeFF能够促进相邻token之间的相关性。
- 在Transformer的顶部附加Layer-wise Class token Attention(LCA),能够综合多层特征作为最终输出。
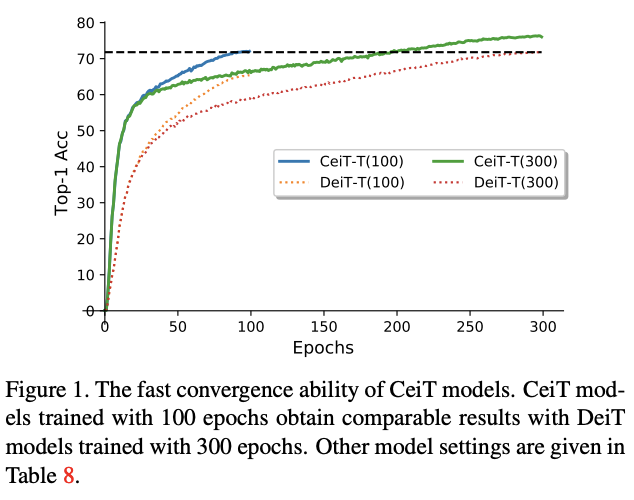
在ImageNet和七个下游任务的实验结果表明,CeiT的性能和泛化能力比之前的Transformer和CNN更优,而且不需要大量的训练数据和额外的CNN蒸馏。此外,CeiT模型的收敛性更好,训练迭代次数减少了3倍,极大地降低了训练成本。
Methodology
Image-to-Tokens with Low-level Features
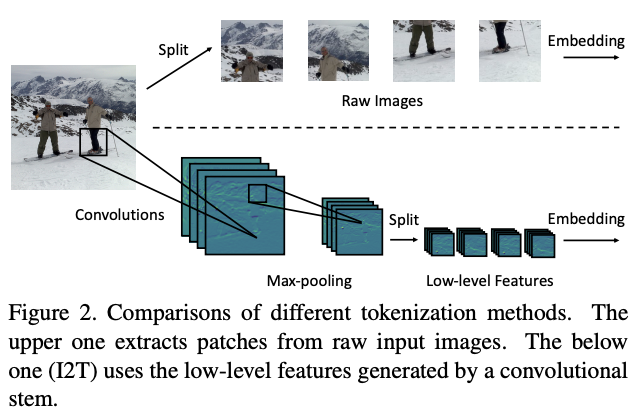
为了优化初始token序列的生成,论文提出了简单而有效的Imageto-Tokens(I2T)模块,从生成的低维特征中提取token序列,而不是将原始输入图像直接分割。如图2所示,I2T模块是由卷积层和最大池化层组成的轻量级stem结构,卷积层后面会进行BN操作。整个模块可表示为:
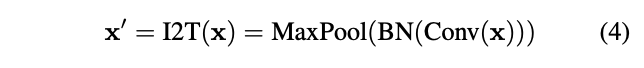
其中\(x^{'}\in \mathbb{R}^{\frac{H}{S}\times \frac{W}{S}\times D}\),\(S\)为卷积的stride参数,\(D\)为卷积输出的通道数。
在得到输出特征图后,根据空间维度从中切割图像块序列。为了保持生成的标记数量与ViT一致,论文将图像块的分辨率缩减为\((\frac{P}{S} ,\frac{P}{S})\),在实践中设定\(S = 4\)。最后,通过embedding操作将图像块序列转换为token序列。
I2T模块能够充分发挥CNN在提取低层次特征方面的优势,并且能够通过缩小图像块的大小来降低embedding的训练难度。与用ResNet-50来提取后两个阶段的高层特征的混合类型Transformer对比,I2T模块要轻量得多。
Locally-Enhanced Feed-Forward Network
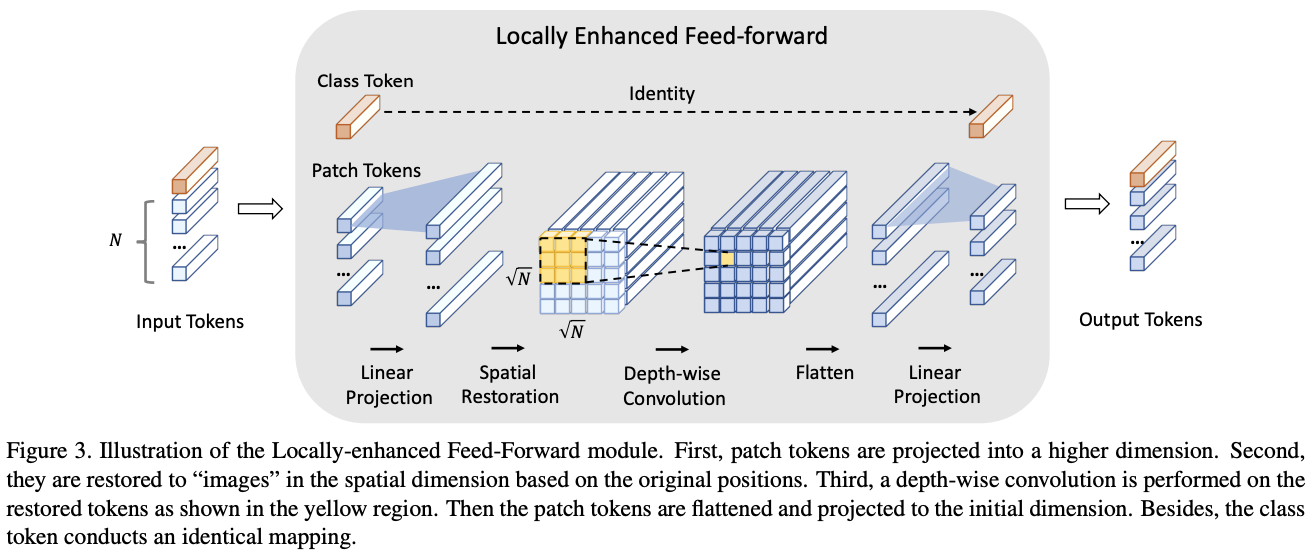
为了将CNN提取局部信息的优势与Transformer建立长距离依赖关系的能力相结合,论文提出了Locally-enhanced FeedForward Network(LeFF)层。在每个encoder模块中,保持MHSA模块不变来保留捕捉token间全局相似性的能力,将原来的前馈网络层用LeFF取代,LeFF的结构如图3。

LeFF模块的执行如公式5-11所示,每条公式对应以下一条处理:
- 定义MSA模块生成的输出为\(x^h_t \in\mathbb{R}^{(N+1)\times C}\),将其区分为图像token序列\(x^h_p\in \mathbb{R}^{N\times C}\)和一个class token \(x^h_c\in \mathbb{R}^C\)。
- 对图像token序列进行线性投影,扩展到更高维度的\(x^{l1}_p\in \mathbb{R}^{N\times (e×C)}\),其中\(e\)是扩展率。
- 根据相对于原始图像的位置,将图像token序列进行空间维度的还原,得到还原特征图\(x^s_p\in \mathbb{R}^{\sqrt{N}\times \sqrt{N}\times(e\times C)}\)。
- 对还原的特征图进行内核大小为\(k\)的深度卷积处理,增强每个token与相邻的\(k^2 - 1\)个token的特征相关性,得到增强特征图\(x^d_p\in \mathbb{R}^{\sqrt{N}\times \sqrt{N}\times(e\times C)}\)。
- 将还原特征图中拉平为\(x^f_p\in \mathbb{R}^{N\times (e\times C)}\)的序列。
- 将序列中的token映射回初始维度,得到最终的token序列\(x^{l2}_p\in \mathbb{R}^{N\times C}\),
- 将最终的token序列与class tken连接,得到最终输出\(x^{h+1}_t\in \mathbb{R}^{(N+1)\times C}\)。
需要注意,在每次线性投影和深度卷积之后,都会增加进行BatchNorm和GELU处理。
Layer-wise Class-Token Attention
在CNN中,特征图的感受域随着网络的加深而增加。在ViT中也有类似的现象,自注意计算范围随深度增加而增加。因此,特征的表达在不同层会有所不同。为了整合不同层的信息,论文设计了Layer-wise Class-token Attention(LCA)模块。标准的ViT只使用第\(L\)层(最后)的class token \(x^{(L)}_c\)作为最终特征,而LCA则综合不同层的class token作为最终特征。
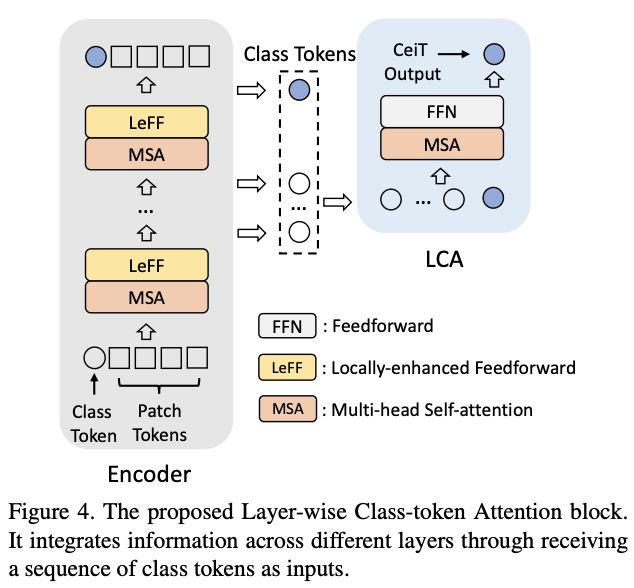
如图4所示,LCA将一串class token \(X_c = [x^{(1)}_c,\cdots,x^{(l)}_c,\cdots,x^{(L)}_c]\)作为输入,其中\(l\)表示层深度。LCA遵循Transformer block的标准实现,包含一个MSA和一个FFN层。LCA的MSA层只计算第\(L\)个class token \(x^{(L)}_c\)和其他class token之间的单向相似性,这样可以将计算复杂度从\(O(n^2)\)降低到\(O(n)\)。聚合后的\(x^{(L)}_c\)的对应值被送入FFN层,从而得到最终特征\(x^{(L)^{'}}_c\)。
Computational Complexity Analysis

论文设计了不同大小的CeiT模型,并对修改所带来的额外计算复杂性(以FLOPs为单位)进行了分析。一般来说,在计算成本略有增加的情况下,CeiT可以有效地结合CNN和Transformer的优势获得更高的性能和更好的收敛性,具体的计算复杂度分析可以看看原文。
Experiment

训练配置。
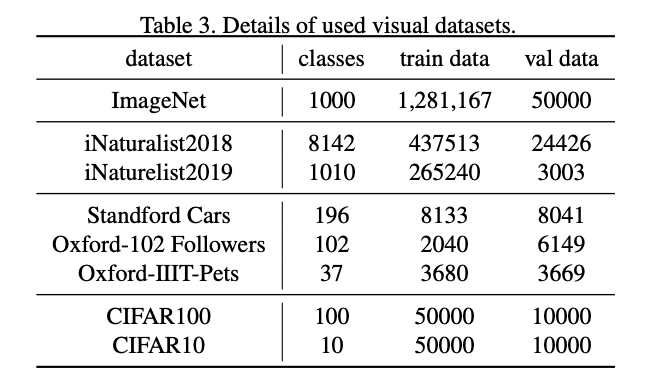
使用的数据集。

ImageNet结果。
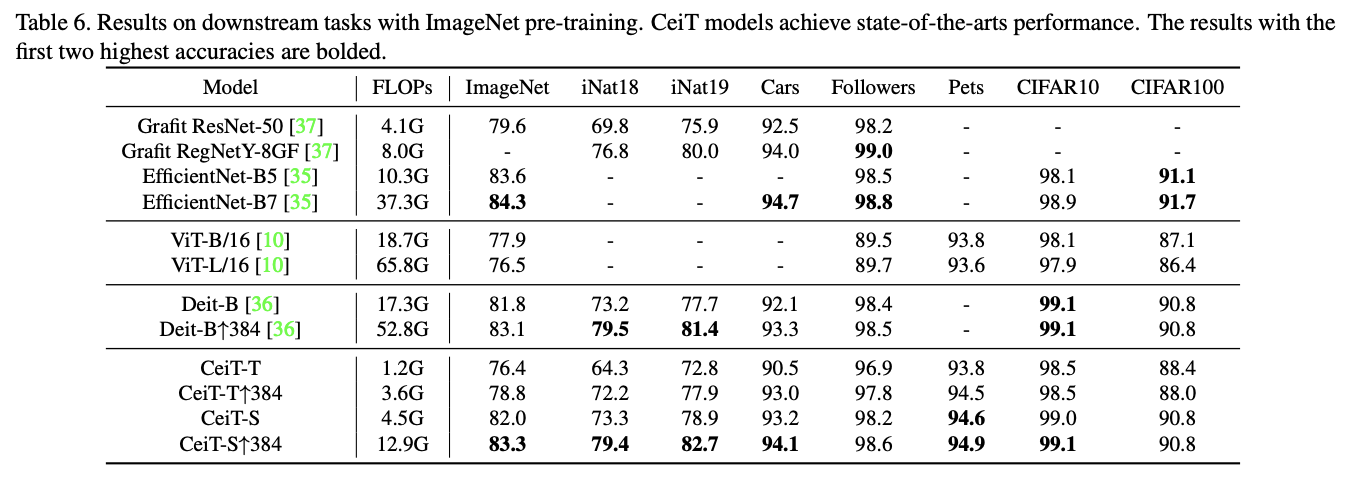
ImageNet预训练迁移结果。
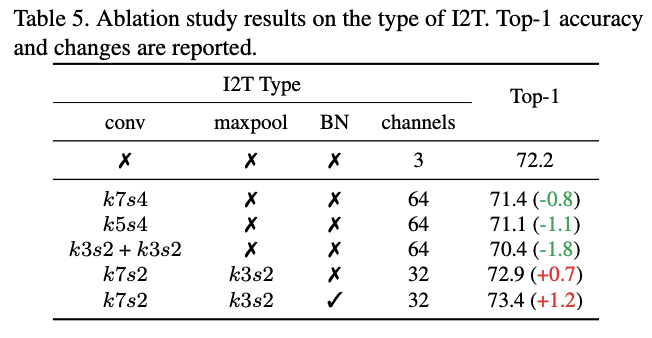
I2T模块参数的对比实验。
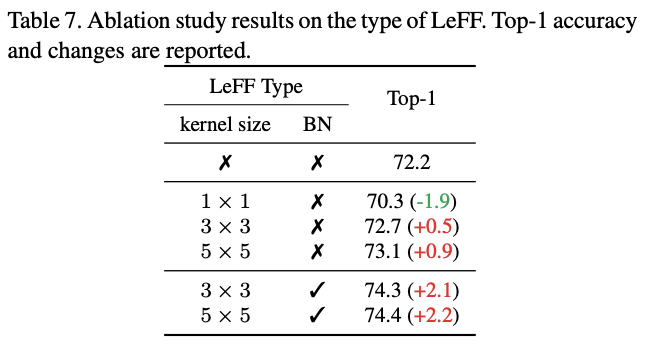
LeFF模块参数的对比实验。
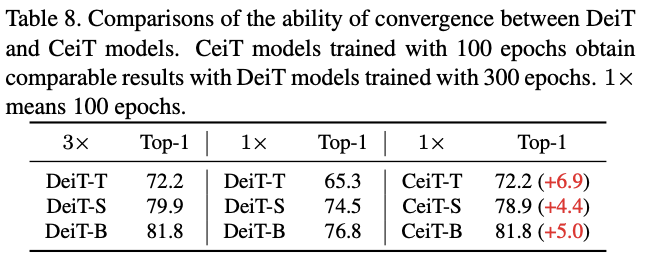
不同模型大小在不同周期下的收敛效果对比。
Conclusion
论文提出CeiT混合网络,结合了CNN在提取低维特征方面的局部性优势以及Transformer在建立长距离依赖关系方面的优势。CeiT在ImageNet和各种下游任务中达到了SOTA,收敛速度更快,而且不需要大量的预训练数据和额外的CNN蒸馏监督,值得借鉴。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

CeiT:商汤提出结合CNN优势的高效ViT模型 | 2021 arxiv的更多相关文章
- 商汤提出解偶检测中分类和定位分支的新方法TSD,COCO 51.2mAP | CVPR 2020
目前很多研究表明目标检测中的分类分支和定位分支存在较大的偏差,论文从sibling head改造入手,跳出常规的优化方向,提出TSD方法解决混合任务带来的内在冲突,从主干的proposal中学习不同的 ...
- 旷视向左、商汤向右,AI一哥之名将落谁家
编辑 | 于斌 出品 | 于见(mpyujian) AI风口历经多年洗礼之后,真正意义上的AI第一股终于要来了. 相比于聚焦在语音识别技术上的科大讯飞.立足互联网产业的百度.发力人形机器人领域的优必选 ...
- 商汤科技汤晓鸥:其实不存在AI行业,唯一存在的是“AI+“行业
https://mp.weixin.qq.com/s/bU-TFh8lBAF5L0JrWEGgUQ 9 月 17 日,2018 世界人工智能大会在上海召开,在上午主论坛大会上,商汤科技联合创始人汤晓鸥 ...
- 2019 计蒜之道 初赛 第一场 商汤AI园区的n个路口(中等) (树形dp)
北京市商汤科技开发有限公司建立了新的 AI 人工智能产业园,这个产业园区里有 nn 个路口,由 n - 1n−1 条道路连通.第 ii 条道路连接路口 u_iui 和 v_ivi. 每个路口都布有 ...
- 计蒜客 第四场 C 商汤科技的行人检测(中等)平面几何好题
商汤科技近日推出的 SenseVideo 能够对视频监控中的对象进行识别与分析,包括行人检测等.在行人检测问题中,最重要的就是对行人移动的检测.由于往往是在视频监控数据中检测行人,我们将图像上的行人抽 ...
- 谷歌大脑提出:基于NAS的目标检测模型NAS-FPN,超越Mask R-CNN
谷歌大脑提出:基于NAS的目标检测模型NAS-FPN,超越Mask R-CNN 朱晓霞发表于目标检测和深度学习订阅 235 广告关闭 11.11 智慧上云 云服务器企业新用户优先购,享双11同等价格 ...
- 商汤开源的mmdetection技术报告
目录 1. 简介 2. 支持的算法 3. 框架与架构 6. 相关链接 前言:让我惊艳的几个库: ultralytics的yolov3,在一众yolov3的pytorch版本实现算法中脱颖而出,收到开发 ...
- 面试 | 商汤科技面试经历之Promise红绿灯的实现
说在前面 说实话,刚开始在听到这个面试题的实话,我是诧异的,红绿灯?这不是单片机.FPGA.F28335.PLC的实验吗?! 而且还要用Promise去写,当时我确实没思路,只好硬着头皮去写,下来再r ...
- SenseTime Ace Coder Challenge 暨 商汤在线编程挑战赛 A. 地铁站
//其实比赛的时候就想到这方法了,但看到数据太吓人,就没写//看着标程,实际上就是这方法,太坑爹…… /* 假设值为k,对于图中任意两点,圆1半径k/t1,圆2半径k/t2 圆1与圆2的交集为可以设置 ...
- SenseTime Ace Coder Challenge 暨 商汤在线编程挑战赛 D. 白色相簿
从某一点开始,以层次遍历的方式建树若三点a.b.c互相连接,首先必先经过其中一点a,然后a可以拓展b.c两点,b.c两点的高度是相同的,若b(c)拓展时找到高度与之相同的点,则存在三点互相连接 //等 ...
随机推荐
- Yolov5代码详解——detect.py
首先执行扩展包的导入: import argparse import os import platform import sys from pathlib import Path import t ...
- 动态库 DLL 封装二:dll封装方法
例:我新建的工程是,带lib的MFC规则的DLL 主要有三个文件需要写东西 ( .h / .cpp / .def ) 示例: // a.h ...... #ifdef __cplusplus e ...
- 从 Oracle 到 MySQL 数据库的迁移之旅
目录 引言 一.前期准备工作 1.搭建新的MySQL数据库 2 .建立相应的数据表 2.1 数据库兼容性分析 2.1.1 字段类型兼容性分析 2.1.2 函数兼容性分析 2.1.3 是否使用存储过程? ...
- SpringBoot使用Redis做缓存结合自带注解
配置Spring Cache <dependency> <groupId>org.springframework.boot</groupId> <artifa ...
- 争论不休的一个话题:金额到底是用Long还是BigDecimal?
在网上一直流传着一个争论不休的话题:金额到底是用Long还是用BigDecimal?这个话题一出在哪都会引起异常无比激烈的讨论.... 比如说这个观点:算钱用BigDecimal是常识 有支持用Lon ...
- LRU缓存及其实现
缓存是我们日常开发中来提高性能最直接的方式,经常会听到有人说:性能不行?是因为你没加缓存!常见的缓存有外部缓存服务以及程序内部缓存,外部缓存服务包括:Redis.Memcached等,内部缓存就是我们 ...
- EasyNLP玩转文本摘要(新闻标题)生成
简介: 本⽂将提供关于PEGASUS的技术解读,以及如何在EasyNLP框架中使⽤与PEGASUS相关的文本摘要(新闻标题)生成模型. 作者:王明.黄俊 导读 文本生成是自然语言处理领域的一个重要研究 ...
- SQL 开发任务超 50% !滴滴实时计算的演进与优化
摘要:Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算.可部署在各种集群环境,对各种大小的数据规模进行快速计算.滴滴基于 Apache Flink 做了大 ...
- 为余势负天工背,云原生内存数据库Tair助力用户体验优化
简介:作为双11大促承载流量洪峰的利器,Tair支撑了电商交易核心体验场景.不仅在数十亿QPS的峰值下保持着亚毫秒级别的顺滑延迟,同时在电商交易核心体验场景上也做出了技术创新. 作者 | 漠冰 ...
- PostgreSQL数据目录深度揭秘
简介: PostgreSQL是一个功能非常强大的.源代码开放的客户/服务器关系型数据库管理系统(RDBMS),被业界誉为"先进的开源数据库",支持NoSQL数据类型,主要面向企业复 ...