《编译原理》阅读笔记:p18
《编译原理》学习第 3 天,p18总结,总计 14页。
一、技术总结
1.assembler
(1)计算机结构
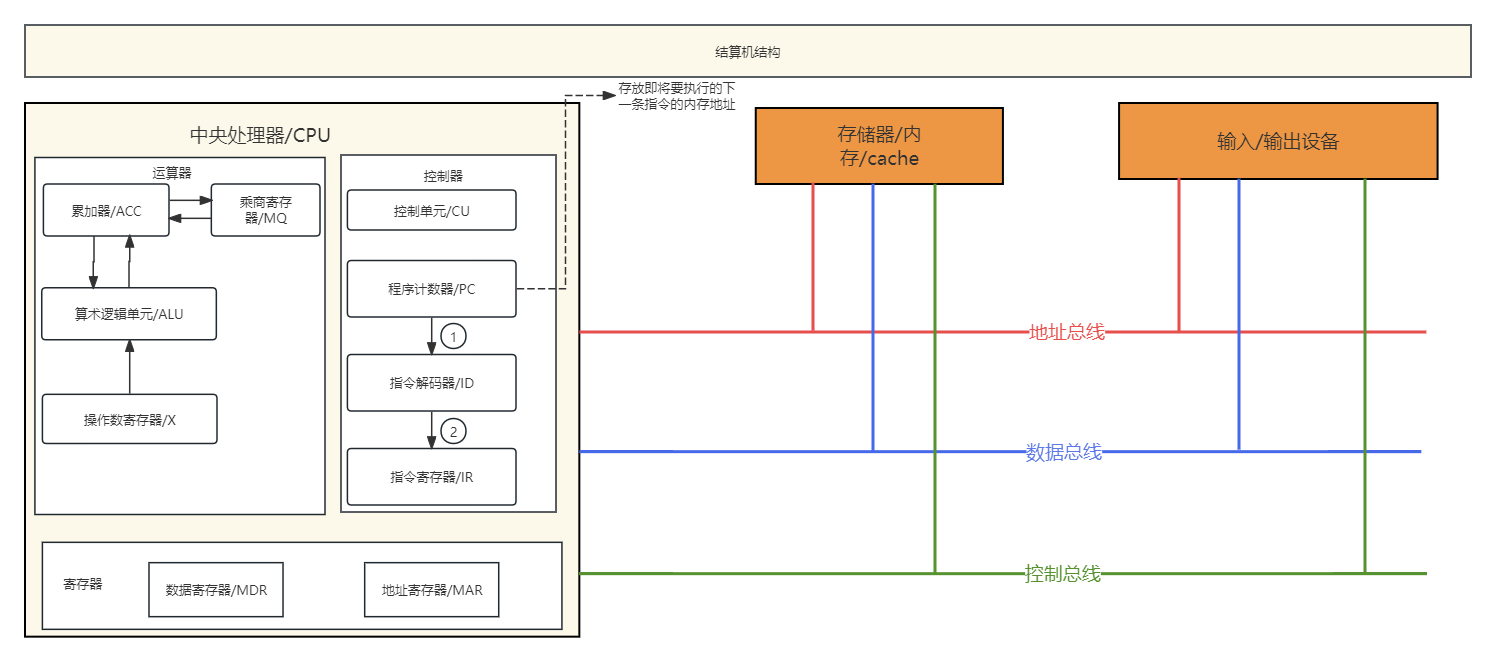
要想学习汇编的时候更好的理解,要先了解计算机的结构,以下是本人学习汇编时总结的一张图,每当学习汇编时,看到“计数器”,“解码器”,“寄存器”,“数据总线”等概念时,就知道说的这些东西在哪个位置。
(2)assembly code(汇编代码)
p17,Some compilers produce assembly code, as in (1.5), that is passed to an assembler for further processing.
MOVF id3, R2
MULF #60.0, R2
MOVF id2, R1
ADDF R2, R1
MOVF R1,id1
上面汇编代码对应的代码为:
temp1 := id3 * 60.0
id1: = id2 + temp1
这里提到了汇编代码,所以我们在阅读本书时需要有一点汇编语言基础:
(3)指令(instruction)
如MOVF, F表示Floating-point numbers。注意,指令有两种语法,分别是Intel 语法和AT&T语法。支持Intel语法的主要是Windows系统,支持AT&T语法的主要是Unix系统。
Intel 语法:mov dest, src
AT&T 语法:mov src, dest
参考:https://en.wikipedia.org/wiki/X86_assembly_language
p15, The first and second operands of each instruction specify a source and destination, respectively....This code moves the contents of address id3 into register2, then multiplies it with the real-constant 60.0.——书里使用的是AT&T语法,本书作者之一Alfred V.Aho与AT&T的关系:Alfred V.Aho is head of the Computation Principle Research Department at AT&T Bell Laboratories in Murray Hill New Jersey。
(4)#号
表示intermediate data。
2.machine code
0001 01 00 00000000
0011 01 10 00000010
0010 01 00 00000100
如上所示称为machine code, 当我们看到“machine code”这个词的时候我们要想到上面的代码。
二、其它
进入六月以来,每天都忙于加班,疲于奔命,阅读《编译原理》几乎无进度,然而内心觉得这并不是我想要的,因为长此以往,就会停不前,还是要每天学习一些新的东西;二是,自己也不喜欢这样重复的去做相同的事。所以,我又折回来继续看书了。
四、参考资料
1. 编程
(1)Alfred V. Aho,Monica S. Lam,Ravi Sethi,Jeffrey D. Ullman,《编译原理(英文版·第1版)》:https://book.douban.com/subject/5416783/
2. 英语
(1)Etymology Dictionary:https://www.etymonline.com
(2) Cambridge Dictionary:https://dictionary.cambridge.org

欢迎搜索及关注:编程人(a_codists)
《编译原理》阅读笔记:p18的更多相关文章
- 编译原理学习笔记·语法分析(LL(1)分析法/算符优先分析法OPG)及例子详解
语法分析(自顶向下/自底向上) 自顶向下 递归下降分析法 这种带回溯的自顶向下的分析方法实际上是一种穷举的不断试探的过程,分析效率极低,在实际的编译程序中极少使用. LL(1)分析法 又称预测分析法, ...
- Java 实现《编译原理》中间代码生成 -逆波兰式生成与计算 - 程序解析
Java 实现<编译原理>中间代码生成 -逆波兰式生成与计算 - 程序解析 编译原理学习笔记 (一)逆波兰式是什么? 逆波兰式(Reverse Polish notation,RPN,或逆 ...
- Stanford公开课《编译原理》学习笔记(2)递归下降法
目录 一. Parse阶段 CFG Recursive Descent(递归下降遍历) 二. 递归下降遍历 2.1 预备知识 2.2 多行语句的处理思路 2.3 简易的文法定义 2.4 文法产生式的代 ...
- Stanford公开课《编译原理》学习笔记(1~4课)
目录 一. 编译的基本流程 二. Lexical Analysis(词法分析阶段) 2.1 Lexical Specification(分词原则) 2.2 Finite Automata (典型分词算 ...
- MOOC 编译原理笔记(一):编译原理概述以及程序设计语言的定义
编译原理概述 什么是编译程序 编译程序指:把某一种高级语言程序等价地转换成另一张低级语言程序(如汇编语言或机器代码)的程序. 高级语言程序-翻译->机器语言程序-运行->结果. 其中编译程 ...
- 《Windows内核安全与驱动开发》阅读笔记 -- 索引目录
<Windows内核安全与驱动开发>阅读笔记 -- 索引目录 一.内核上机指导 二.内核编程环境及其特殊性 2.1 内核编程的环境 2.2 数据类型 2.3 重要的数据结构 2.4 函数调 ...
- 跟vczh看实例学编译原理——三:Tinymoe与无歧义语法分析
文章中引用的代码均来自https://github.com/vczh/tinymoe. 看了前面的三篇文章,大家应该基本对Tinymoe的代码有一个初步的感觉了.在正确分析"print ...
- 跟vczh看实例学编译原理——二:实现Tinymoe的词法分析
文章中引用的代码均来自https://github.com/vczh/tinymoe. 实现Tinymoe的第一步自然是一个词法分析器.词法分析其所作的事情很简单,就是把一份代码分割成若干个tok ...
- 跟vczh看实例学编译原理——一:Tinymoe的设计哲学
自从<序>胡扯了快一个月之后,终于迎来了正片.之所以系列文章叫<看实例学编译原理>,是因为整个系列会通过带大家一步一步实现Tinymoe的过程,来介绍编译原理的一些知识点. 但 ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
随机推荐
- dotnet OpenXML 文本删除线解析方法
本文来告诉大家如何解析读取在 OpenXML 里面存放的文本删除线,本文使用 PowerPoint 作为例子来告诉大家如何读取然后在 WPF 应用里面显示 在开始之前,期望大家已了解如何在 dotne ...
- Windows 对全屏应用的优化
全屏应用对应的是窗口模式应用,全屏应用指的是整个屏幕都是被咱一个应用独占了,屏幕上没有显示其他的应用,此时的应用就叫全屏应用.如希沃白板这个程序.本文主要告诉大家从微软官方的文档以及考古了解到的 Wi ...
- SpringBoot项目添加2FA双因素身份认证
什么是 2FA(双因素身份验证)? 双因素身份验证(2FA)是一种安全系统,要求用户提供两种不同的身份验证方式才能访问某个系统或服务.国内普遍做短信验证码这种的用的比较少,不过在国外的网站中使用双因素 ...
- Visual Studio 2019 自带混淆工具DotFuscator不需要去网络下载
http://t.zoukankan.com/daizhipeng-p-13492298.html 大家是否还在困扰发布的项目dll容易被人反编译呢,VS2019默认是没有安装DotFuscator的 ...
- 使用Binlog日志恢复误删的MySQL数据实战
前言 "删库跑路"是程序员经常谈起的话题,今天,我就要教大家如何删!库!跑!路! 开个玩笑,今天文章的主题是如何使用Mysql内置的Binlog日志对误删的数据进行恢复,读完本文, ...
- Steam中将XBox手柄默认布局改为任天堂手柄布局的方法
1. 在Steam菜单栏找到"查看",选择大屏幕模式. 2. 进入大屏幕模式后,在菜单界面找到"设置". 3. 在设置界面找到"控制器",选 ...
- Golang 版本 支付宝支付SDK app支付接口2.0
参考技术贴: https://blog.csdn.net/ming2316780/article/details/86505883 对接文档: https://opendocs.alipay.com/ ...
- arcmap利用合并工具修改字段名称、类型、顺序
- JavaScript前端时间库moment.js
1.获取当前时间 moment().format("YYYY-MM-DD HH:mm:ss"); moment().format("YYYY-MM-DD"); ...
- ❤️🔥 Solon Cloud Event 新的事务特性与应用
1.Solon Cloud Event? 是 Solon 分布式事件总线的解决方案.也是 Solon "最终一致性"分布式事务的解决方案之一 2.事务特性 事务?就是要求 Even ...