火山引擎DataLeap的Catalog系统搜索实践(三):Learning to rank与后续工作
Learning to rank
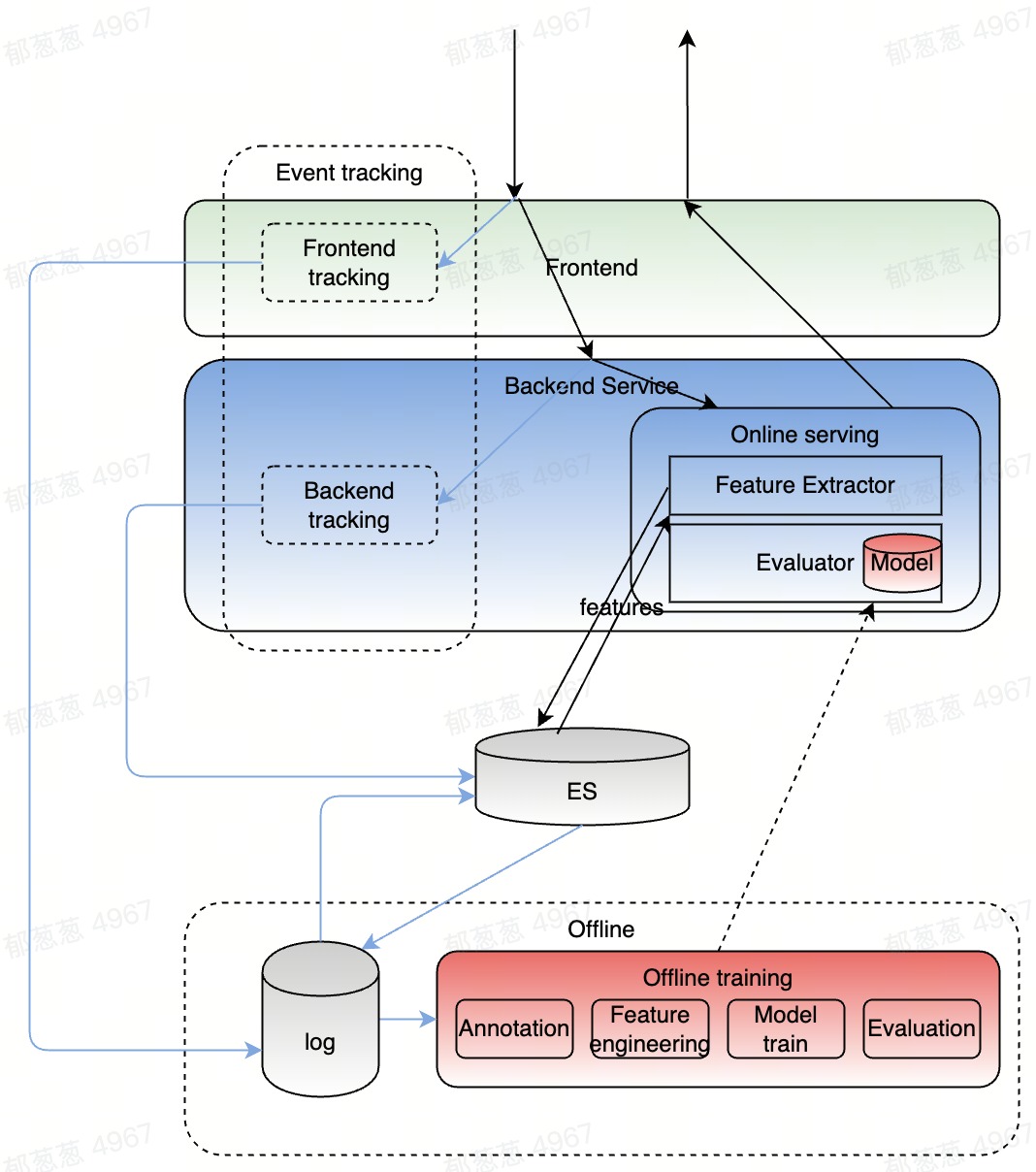
数据标注
特征
- 文本特征
- 输入相关的文本特征
- 输入长度,比如有多少个词,总长度等等
- 输入语言类型,中文或英文
- 文本匹配度相关的特征
- 基于词袋的CQR
- Elasticsearch查询返回分数,基于BM25
- 数据权威性
- 热度:AssetRank, 基于资产的使用量和血缘关系,通过Weighted PageRank算法计算得到的资产热度
- 元数据完整度,包含资产的业务元数据,如项目,主题,产品线等
- 资产的最近1天/7天/30天的全平台使用总次数
- 资产所处的生命周期:如上线,待下线,废弃等
- 资产的总点赞数
- 用户个性化数据,分为三大类
- 静态个性化数据
- 负责人:当前用户是否是该资产的负责人
- 收藏:当前用户是否收藏了该资产
- 点赞:当前用户是否点赞了该资产
- 历史搜索查询行为数据
- 当前用户历史上最近1天/7天/30天全平台使用该资产的次数
- 当前用户历史上最近1天/7天/30天在Data Catalog平台查询点击该资产的次数
- 协同数据
- 同部门人员历史上最近1天/7天/30天在Data Catalog平台查询点击该资产的次数
- 当前用户历史上最近1天/7天/30天在Data Catalog平台查询点击该资产所属部门所有资产的次数
- 当前用户历史上最近1天/7天/30天在Data Catalog平台查询点击该资产所属负责人所有资产的次数
- 数据时效性,用户会更倾向于使用最近创建或者有数据更新的资产
- 资产创建时间
- 资产数据的最近更新时间等
模型
- Pointwise,对每个输入,对每个召回的资产单独打分(通常是Regression),然后按照分数进行排序。
- 优点:简单直观。
- 缺点:排序实际上不需要对资产进行精确打分,这类方法没有考虑召回资产之间的互相关系,考虑到用户在一组资产中只会点击其中一个,排名靠后的和排名靠前的资产在损失函数上的贡献没有体现。
- Pairwise,对每个输入,考虑召回结果中所有资产的二元组合<资产1, 资产2>, 采取分类模型,预测两个资产的相对排序关系。
- 优点:基于点击与原有相关性分数排序标注简单,相比pointwise考虑到选项之间关系。
- 缺点:同样没有考虑排序前后顺序的重要性不同,样本生成复杂,开销大。对异常标注敏感,错误点影响范围大。
- Listwise,考虑给定输入下的召回资产集合的整体序列,优化整个序列,通常使用NDCG作为优化目标。
- 优点:优化整个序列,考虑序列内资产之间的关系。
- 缺点:单条样本训练量大。样本过少,则无法对所有样本预测得到好的效果。
评估
- NDCG,归一化折损累计增益。NDCG是推荐和搜索中比较常用的评估方法,用来整体评估排序结果的准确性。
- AUC,AUC主要反映排序能力的相对性,用于在正负样本不均衡的情况衡量离线模型拟合情况。
- 重放有点击历史数据的点击率,使用待评估的模型预测有点击的历史输入,排序后得到Top3, Top5, Top10 点击率作为参考。这种方式比较直观,缺点是不能反映出在无点击历史数据上的效果。
衡量指标
- 搜索结果页透出的信息过少,用户不得不点击结果进入资产详情,即使只想查看一些简单的信息。
- 用户在系统上探索的兴趣较小,只搜熟悉的资产或者确定能搜到的输入。
其它模式
后续工作
- 血缘中的搜索。当一个资产的一级下游就超过上千个时,想从当前资产的众多下游中查找到相关的资产并不容易,因此提供基于血缘的筛选和搜索是一个不错的选择。
- 多租户之间模型的迁移。作为支持多租户的公有云服务,由于租户之间数据的差异,新租户的冷启动问题,以较小的数据量和成本来支持不同租户都有好的搜索体验,也是一个值得挑战的方向。
火山引擎DataLeap的Catalog系统搜索实践(三):Learning to rank与后续工作的更多相关文章
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 字节跳动构建Data Catalog数据目录系统的实践(上)
作为数据目录产品,Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景,并服务于数据开发和数据治理的产品体系.本文介绍了字节跳动 Data ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- JuiceFS 在火山引擎边缘计算的应用实践
火山引擎边缘云是以云计算基础技术和边缘异构算力结合网络为基础,构建在边缘大规模基础设施之上的云计算服务,形成以边缘位置的计算.网络.存储.安全.智能为核心能力的新一代分布式云计算解决方案. 01- 边 ...
- 京东基于Spark的风控系统架构实践和技术细节
京东基于Spark的风控系统架构实践和技术细节 时间 2016-06-02 09:36:32 炼数成金 原文 http://www.dataguru.cn/article-9419-1.html ...
随机推荐
- 【日常收支账本】【Day03】完成编辑账本界面的新增动账记录功能——通过ElementTree加XPath实现
一.项目地址 https://github.com/LinFeng-BingYi/DailyAccountBook 二.新增 1. 解析xml文件 1.1 功能详述 解析所设计的xml文件格式,并将所 ...
- C语言输入一行字符,分别统计出其中英文字母、空格、数字与其它字符得个数。
#include<stdio.h> void main() { char c; int letter = 0, space = 0, digit = 0, other = 0; print ...
- 删除当前文件夹不是.vue文件,电脑命令符
::-----------------------------------------@echo offsetlocal EnableDelayedExpansionset _thisFilePath ...
- 浮点类型(double与float及其它们的输入输出)
<1>浮点类型 (1)两种类型 double 字长64位(8个字节),有效数字15,范围大概为2.2* 10^-308 ~ 1.79*10^308,0,nan; float字长32位(4个 ...
- [CF1854C] Expected Destruction
题目描述 You have a set $ S $ of $ n $ distinct integers between $ 1 $ and $ m $ . Each second you do th ...
- 【案例教程】LoadRunner订票系统WebTours部署
题目: 使用LoadRunner自带的测试项目--航班订票管理系统WebTours,网站地址为:http://127.0.0.1:1080/WebTours/ (用户名为jojo,密码为bean),完 ...
- springBoot——多环境开发
不常用的application.properties版的 常用的:application.yml版 #多环境开发,设置启用环境 spring: profiles: active: test --- # ...
- spring报错-Caused by: java.lang.IllegalArgumentException: Unsupported class file major version 63
这个错误原因是因为JDK版本过高,改一下版本就行了 把里面的19改成8 这样就行了
- Shell下处理JSON数据工具向导
目录 下载离线安装包 安装 源码包安装 选项及含义 JQ 程序代码演示在线平台 JQ 语法 基本过滤器 身份运算符 --- . 标识符-索引 --- .foo`, `.foo.bar 对象索引 --- ...
- 使用cgroup控制内存
关键文件 memory.limit_in_bytes memory.soft_limit_in_bytes memory.memsw.limit_in_bytes tasks cgroup.procs ...