火山引擎DataLeap的Data Catalog系统公有云实践
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
Data Catalog公有云整体架构
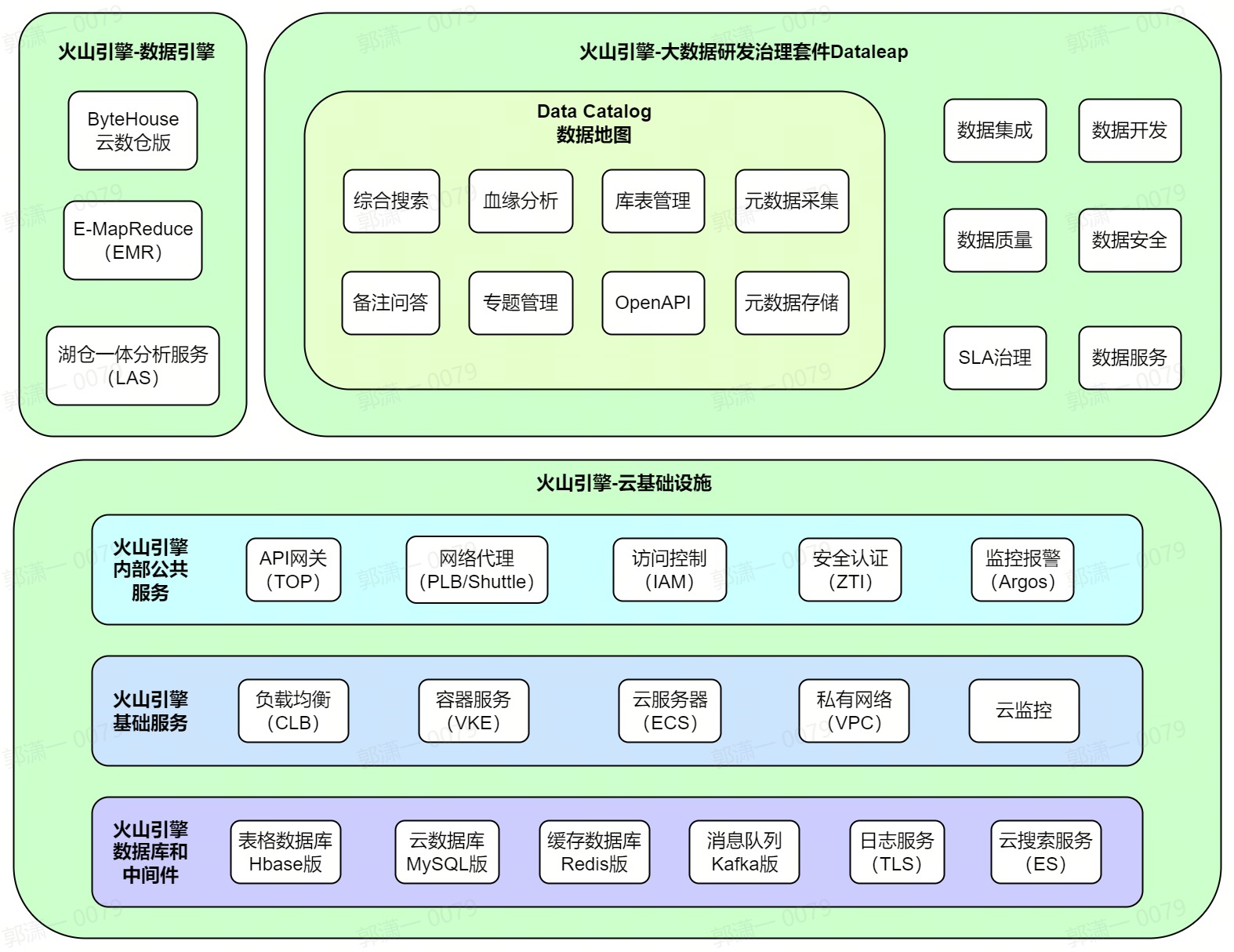
- 数据引擎:是火山引擎提供的数据分析、数据仓库和数据湖相关产品,包括ByteHouse/EMR/LAS等产品。通常Data Catalog会从这类系统内采集元并存储元数据,进行处理加工后,再提供搜索、血缘分析等功能;另外,库表管理模块也会依赖这类系统提供对应的接口来做建库建表等操作。
- 内部公共服务:是火山引擎为支持公司内部产品上公有云提供的若干公共基础服务,主要作用是方便内部产品能快速在公有云部署,提供和公司内部兼容性比较高的公共服务,降低改造和迁移成本。其中Data Catalog使用较多的包括:API网关、网络代理、访问控制、安全认证、监控报警等。
- 基础服务:这类服务或产品相较于上面说的内部公共服务主要区别是,他们是火山引擎对外售卖的标准云服务,内外部用户都可使用,且和业界主流云厂商能力是基本对齐的,不过会和公司内部一些类似的基础服务会有不少差异。Data Catalog主要使用这类基础服务来进行自身服务的部署运维,并且进行较多的兼容性改造,包括容器部署、网络打通、内外部CICD和监控报警流程一致性等方面。
- 数据库和中间件:是和业界主流云厂商对齐的存储和中间件领域的标准云服务,和公司内部对应组件也会有若干差异,Data Catalog为此也做了多版本的兼容。Data Catalog在元数据存储上使用到了Hbase/MySQL/ES/Redis,然后在元数据采集和同步场景使用了Kafka,同时用到了日志服务来提高研发运维效率。
Data Catalog公有云遇到的挑战
网络和数据安全
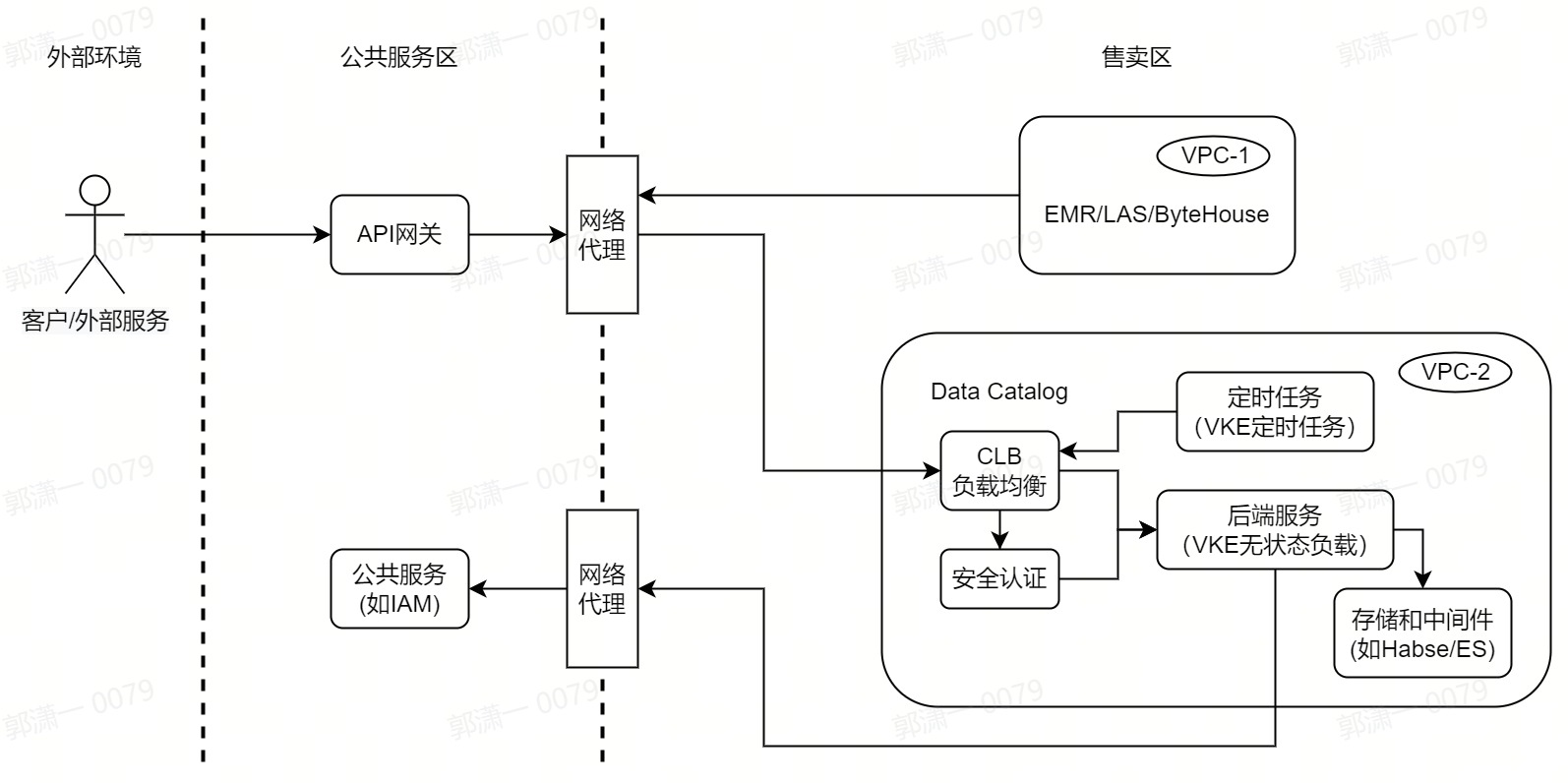
- 服务部署:为了能够在售卖区部署,经过调研我们选择火山引擎提供的容器服务(VKE)和负载均衡(CLB)来进行基础服务部署和构建,其中CLB提供四层负载均衡能力,容器服务是高性能 Kubernetes 容器集群管理服务。Data Catalog基于容器服务提供的无状态负载(Deployment)、定时任务(CronJob)、服务(Service)等云原生容器管理功能进行基本服务和调度任务部署,同时也使用火山引擎的存储和中间件,以上组件均在同一个VPC内,能够保证网络连通以及数据安全。
- 网络打通:为解决上文所说的网络隔离问题,经过调研我们使用了公司通用的网络代理服务(PLB/Shuttle),该网络代理可做到网络打通的同时保证四层网络流量的安全,从而达到我们和各依赖方如公共服务(API网关、IAM等、独立部署的云服务(EMR/LAS等)的网络连通目标。
- 数据安全:火山引擎部署环境做网络隔离,主要是保证安全性,我们虽然使用网络代理打通网络,但是仍需保证各个环节的安全性,考虑到服务间交互都是通过HTTP请求,我们对和外部交互的接口都增加了SSL和双向认证的机制,同时在安全认证方面,我们没有使用Nginx或Java原生的方案,而是借助于火山引擎内部安全服务中的ZTI团队的envoy组件来实现,同时使用sidecar模式和我们后端服务容器集成部署,既降低了服务端部署改造成本,也解耦了服务端业务逻辑和安全认证逻辑。
多租户适配
点击跳转大数据研发治理套件 DataLeap了解更多
火山引擎DataLeap的Data Catalog系统公有云实践的更多相关文章
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- 字节跳动构建Data Catalog数据目录系统的实践(上)
作为数据目录产品,Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景,并服务于数据开发和数据治理的产品体系.本文介绍了字节跳动 Data ...
- 以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
背景 字节跳动 Data Catalog 产品早期,是基于 LinkedIn Wherehows 进行二次改造,产品早期只支持 Hive 一种数据源.后续为了支持业务发展,做了很多修修补补的工作,系统 ...
- jQuery源代码解析(1)—— jq基础、data缓存系统
闲话 jquery 的源代码已经到了1.12.0版本号.据官网说1版本号和2版本号若无意外将不再更新,3版本号将做一个架构上大的调整.但预计能兼容IE6-8的.或许这已经是最后的样子了. 我学习jq的 ...
随机推荐
- ACTF 2023 部分WP
来自密码手的哀嚎: 玩不了一点,太难了. CRYPTO MDH Description Malin's Diffile-Hellman Key Exchange. task.sage from has ...
- 《最新出炉》系列初窥篇-Python+Playwright自动化测试-27-处理单选和多选按钮-番外篇
1.简介 前边几篇文章是宏哥自己在本地弄了一个单选和多选的demo,然后又找了网上相关联的例子给小伙伴或童鞋们演示了一下如何使用playwright来处理单选按钮和多选按钮进行自动化测试,想必大家都已 ...
- Android 面试知识总结
Android知识点 1. 四大组件 分别是Activity.Service.ContentProvider.BroadcastReceiver. Activity称为活动,属于展示型组件,主要负责显 ...
- jmeter二次开发自定义函数助手
需求:在工作中,需要使用唯一的字符串来作为订单ID,于是想到了UUID,要求uuid中不能有特殊字符包括横线,所以就有了重新写一个uuid进行使用: 准备:idea 依赖包: 注意事项:必须有包且包的 ...
- H5自适应
一.设置html的font-size,使用rem作为单位 假设设计稿宽度750px,屏幕宽高750px, 1.1rem=屏幕宽度/设计稿宽度*100px,适合用px表示宽度 1rem=100px re ...
- MongoDB中的分布式集群架构
MongoDB 中的分布式集群架构 前言 Replica Set 副本集模式 副本集写和读的特性 Sharding 分片模式 分片的优势 MongoDB 分片的组件 分片键 chunk 是什么 分片的 ...
- JDK8提供的常用计量单位
时间计量单位:Duration @DurationUnit(ChronoUnit.HOURS) private Duration serverTimeout; 空间计量单位:DataSize @Dat ...
- Python 潮流周刊第 32 期(摘要)
本周刊由 Python猫 出品,精心筛选国内外的 250+ 信息源,为你挑选最值得分享的文章.教程.开源项目.软件工具.播客和视频.热门话题等内容.愿景:帮助所有读者精进 Python 技术,并增长职 ...
- 安装服务器提示A debugger has been found running in your system. Please, unload it from memory and restart
解决方法:运行msconfig,取消调试模式,重启电脑再安装
- 从零玩转设计模式之抽象工厂设计模式-chouxiangshejimoshi
title: 从零玩转设计模式之抽象工厂设计模式 date: 2022-12-08 16:05:03.28 updated: 2022-12-11 23:03:16.842 url: https:// ...