由浅入深,揭秘企业级OLAP数据引擎ByteHouse
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
在字节跳动各产品线飞速成长的过程中,对数据分析能力也提出了更高的要求,现有的主流数据分析产品都没办法完全满足业务要求。因此,字节跳动在 ClickHouse 引擎基础上重构了技术架构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等能力,推出了云原生数据仓库 ByteHouse。
我们可以从下面几个方面认识 ByteHouse:
极致性能:
在延续了 ClickHouse 单表查询强大性能的同时,新增了自研的查询优化器,在多表关联查询和复杂查询场景下性能提升若干倍,实现了在各类型查询中都达到极致性能。
新一代 MPP 架构,存算分离:
使用新式架构,Shared-nothing 的计算层和 Shared-everything 的存储层,可以性能损耗很小的情况下,实现存储层与计算层的分离,独立按需扩缩容。
资源隔离,读写分离:
对硬件资源进行灵活切割分配,按需扩缩容。资源有效隔离,读写分开资源管理,任务之间互不影响,杜绝了大查询打满所有资源拖垮集群的现象。
丰富功能:
ByteHouse 提供客户丰富的企业级能力,如:兼容 ANSI-SQL 2011 标准、支持多租户、库表资产管理、基于角色的权限管理以及多样的性能诊断工具等。
ByteHouse 架构设计
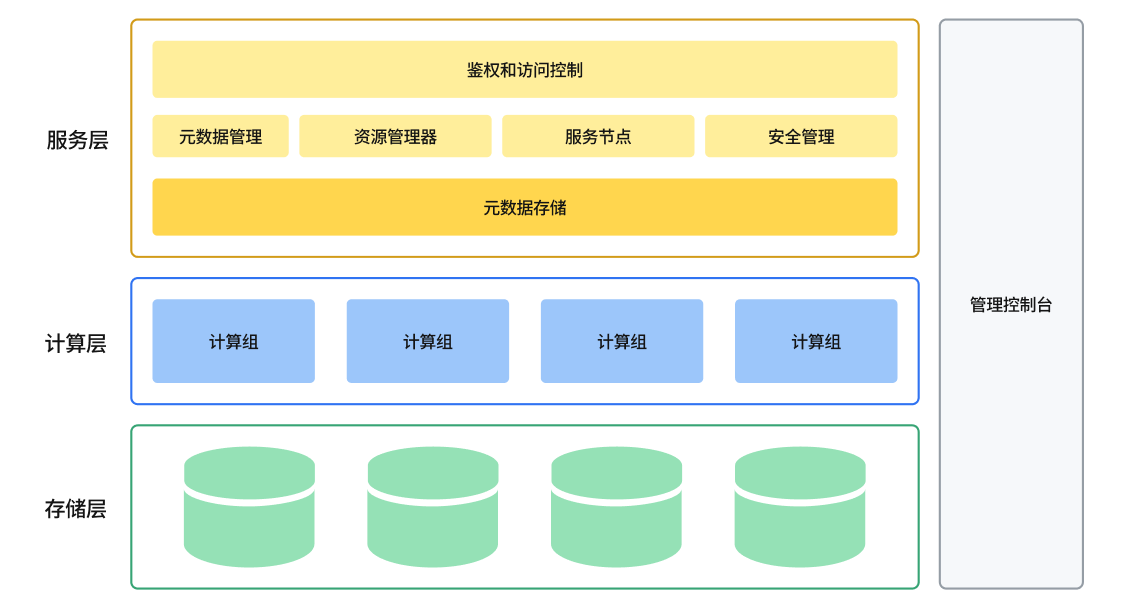
ByteHouse 整体架构图
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。
服务层
服务层包括了所有与用户交互的内容,包括用户管理、身份验证、查询优化器,事务管理、安全管理、元数据管理,以及运维监控、数据查询等可视化操作功能。
服务层主要包括如下组件:
资源管理器
资源管理器(Resource Manager)负责对计算资源进行统一的管理和调度,能够收集各个计算组的性能数据,为查询、写入和后台任务动态分配资源。同时支持计算资源隔离和共享,资源池化和弹性扩缩等功能。资源管理器是提高集群整体利用率的核心组件。
服务节点
服务节点(CNCH Server)可以看成是 Query 执行的 master 或者是 coordinator。每一个计算组有 1 个或者多个 CNCH Server,负责接受用户的 query 请求,解析 query,生成逻辑执行计划,优化执行计划,调度和执行 query,并将最终结果返回给用户。计算组是 Bytehouse 中的计算资源集群,可按需进行横向扩展。
服务节点是无状态的,意味着用户可以接入任意一个服务节点(当然如果有需要,也可以隔离开),并且可以水平扩展,意味着平台具备支持高并发查询的能力。
元数据服务
元数据服务(Catalog Service)提供对查询相关元数据信息的读写。Metadata 主要包括 2 部分:Table 的元数据和 Part 的元数据。表的元数据信息主要包括表的 Schema,partitioning schema,primary key,ordering key。Part 的元数据信息记录表所对应的所有 data file 的元数据,主要包括文件名,文件路径,partition, schema,statistics,数据的索引等信息。
元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对于访问频度高的元数据会进行缓存。
元数据服务自身只负责处理对元数据的请求,自身是无状态的,可以水平扩展。
安全管理
权限控制和安全管理,包括入侵检测、用户角色管理、授权管理、访问白名单管理、安全审计等功能。
计算层
通过容器编排平台(如 Kubernetes)来实现计算资源管理,所有计算资源都放在容器中。
计算组是计算资源的组织单位,可以将计算资源按需划分为多个虚拟集群。每个虚拟集群里包含 0 到多台计算节点,可按照实际资源需求量动态的扩缩容。
计算节点主要承担的是计算任务,这些任务可以是用户的查询,也可以是一些后台任务。用户查询和这些后台任务,可以共享相同的计算节点以提高利用率,也可以使用独立的计算节点以保证严格的资源隔离。
计算组是无状态的,可以快速水平扩展。
存储层
采用 HDFS 或 S3 等云存储服务作为数据存储层。用来存储实际数据、索引等内容。
数据表的数据文件存储在远端的统一分布式存储系统中,与计算节点分离开来。底层存储系统可能会对应不同类型的分布式系统。例如 HDFS,Amazon S3, Google cloud storage,Azure blob storage,阿里云对象存储等等。底层存储是天然支持高可用、容量是无限扩展的。
不同的分布式存储系统,例如 S3 和 HDFS 有很多不同的功能和不一样的性能,会影响到我们的设计和实现。例如 HDFS 不支持文件的 update, S3 object move 操作时重操作需要复制数据等。
通过存储的服务化,计算层可以支持 ByteHouse 自身的计算引擎之外,将来还可以便捷地对接其他计算引擎,例如 Presto、Spark 等。
数据导入导出
ByteHouse 包括一个数据导入导出(Data Express)模块,负责数据的导入导出工作。
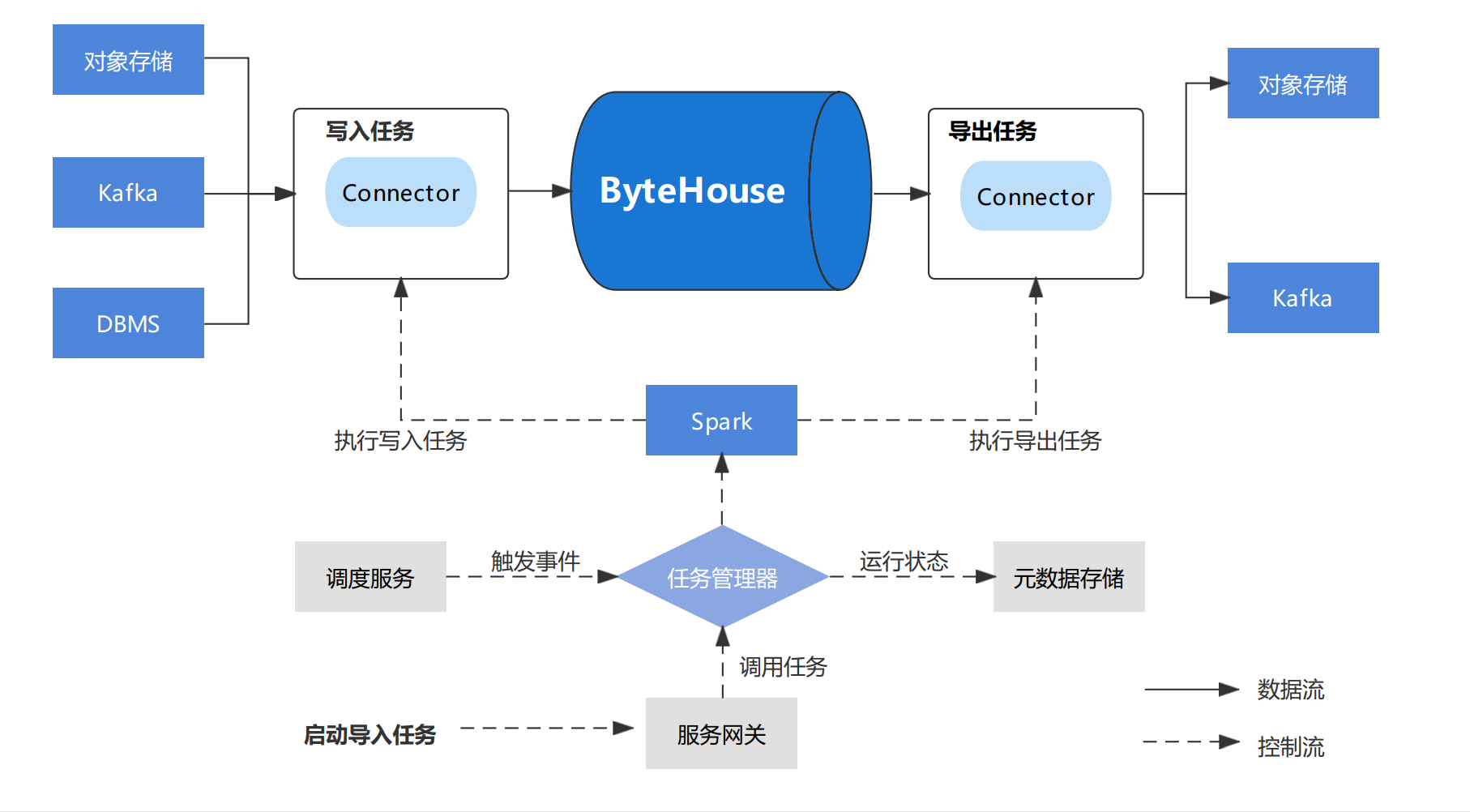
Data Express 模块架构图
Data Express 为数据导入/导出作业提供工作流服务和快速配置模板,用户可以从提供的快速模板创建数据加载作业。
DataExpress 利用 Spark 来执行数据迁移任务。
主要模块:
- JobServer
- 导入模板
- 导出模板
JobServer 管理所有用户创建的数据迁移作业,同时运行外部事件触发数据迁移任务。
启动任务时,JobServer 将相应的作业提交给 Spark 集群,并监控其执行情况。作业执行状态将保存在我们的元存储中,以供 Bytehouse 进一步分析。
ByteHouse 支持离线数据导入和实时数据导入。
离线导入
离线导入数据源:
Object Storage:S3、OSS、Minio
Hive (1.0+)
Apache Kafka /Confluent Cloud/AWS Kinesis
本地文件
RDS
离线导入适用于希望将已准备好的数据一次性加载到 ByteHouse 的场景,根据是否对目标数据表进行分区,ByteHouse 提供了不同的加载模式:
全量加载:全量将用最新的数据替换全表数据。
增量加载:增量加载将根据其分区将新的数据添加到现有的目标数据表。ByteHouse 将替换现有分区,而非进行合并。
支持的文件类型
ByteHouse 的离线导入支持以下文件格式:
Delimited files (CSV, TSV, etc.)
Json (multiline)
Avro
Parquet
Excel (xls)
实时导入
ByteHouse 能够连接到 Kafka,并将数据持续传输到目标数据表中。与离线导入不同,Kafka 任务一旦启动将持续运行。ByteHouse 的 Kafka 导入任务能够提供 exactly-once 语义。您可以停止/恢复消费任务,ByteHouse 将记录 offset 信息,确保数据不会丢失。
支持的消息格式
ByteHouse 在流式导入中支持以下消息格式:
Protobuf
JSON
总结
云原生数据仓库 ByteHouse 是一个具备极致性能、能够存储和计算资源分别按需扩缩容、功能丰富的数据分析产品,是一个面向海量数据、高实时要求的一个企业级 OLAP 数据引擎。
ByteHouse 在字节跳动的众多场景中有着丰富的经验积累,尤其是在实时数据分析场景和海量数据灵活查询场景,都有超大规模的应用。ByteHouse 基于自研技术优势和超大规模的使用经验,为企业大数据团队带来新的选择和支持,以应对复杂多变的业务需求,高速增长的数据场景。目前,ByteHouse 已在火山引擎上提供免费试用,欢迎大家来尝试,并为我们提出宝贵建议。
点击跳转 云原生数据仓库ByteHouse 了解更多
由浅入深,揭秘企业级OLAP数据引擎ByteHouse的更多相关文章
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
- HDP 企业级大数据平台
一 前言 阅读本文前需要掌握的知识: Linux基本原理和命令 Hadoop生态系统(包括HDFS,Spark的原理和安装命令) 由于Hadoop生态系统组件众多,导致大数据平台多节点的部署,监控极其 ...
- 【2019V2全新发布】ComponentOne .NET开发控件集,新增.NET Core数据引擎
ComponentOne .NET开发控件集 2019V2正式发布,除持续完善并加入全新的.NET开发控件外,还针对产品架构稳定性.易用性.与.NET Core平台深度集成.已有控件功能增强等多个方面 ...
- Tapdata肖贝贝:实时数据引擎系列(三) - 流处理引擎对比
摘要:本文将选取市面上一些流计算框架包括 Flink .Spark .Hazelcast,从场景需求出发,在核心功能.资源与性能.用户体验.框架完整性.维护性等方面展开分析和测评,剖析实时数据框架 ...
- FIREDAC数据引擎
以前使用过BDE.ADO.DBX等数据引擎,后来发现它们都没有UNIDAC好用, 所以在很长的一段时间内中间件都使用UNIDAC作为数据引擎. 偶然的机会,使用了DELPHI XE5自带的FIREDA ...
- MySql中启用InnoDB数据引擎的方法
1.存储引擎是什么? Mysql中的数据用各种不同的技术存储在文件(或者内存)中.这些技术中的每一种技术都使用不同的存储机制.索引技巧.锁定水平并且最终提供广泛的不同的功能和能力.通过选择不同的技术, ...
- key-list类型内存数据引擎介绍及使用场景
“互联网数据目前基本使用两种方式来存储,关系数据库或者key value.但是这些互联网业务本身并不属于这两种数据类型,比如用户在社会化平台中的关系,它是一个list,如果要用关系数据库存储就需要转换 ...
- 修改mysql数据引擎的方法- 提高数据库性能
前言:同学告我说,他为了能使得数据查询变得快一点,修改的数据引擎,故查询一下,总结一下. 登录mysql后,查看当前数据库支持的引擎和默认的数据库引擎,使用下面命令: mysql>show en ...
- 搭建企业级全网数据定时备份方案[cron + rsync]
1.1.1. 服务端的配置[192.168.25.141] Rsync的端口是:873 man rsyncd.conf 查看帮助 Rsync是Redhat默认自带的,这里只是做了rsync服务器端的后 ...
- python,java操作mysql数据库,数据引擎设置为myisam时能够插入数据,转为innodb时无法插入数据
今天想给数据库换一个数据引擎,mysiam转为 innodb 结果 python 插入数据时失败,但是自增id值是存在的, 换回mysiam后,又可以插入了~~ 想换php插入试试,结果php数据引擎 ...
随机推荐
- 解码注意力Attention机制:从技术解析到PyTorch实战
在本文中,我们深入探讨了注意力机制的理论基础和实际应用.从其历史发展和基础定义,到具体的数学模型,再到其在自然语言处理和计算机视觉等多个人工智能子领域的应用实例,本文为您提供了一个全面且深入的视角.通 ...
- JUC并发编程学习笔记(七)常用的辅助类
常用的辅助类 CountDownLatch 这是一个JUC计数器辅助类,计数器有加有减,这是减. 使用方法 package org.example.demo; import java.util.con ...
- window.onload 触发时机问题
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- 28. 干货系列从零用Rust编写正反向代理,项目日志的源码实现
wmproxy wmproxy已用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,四层TCP/UDP转发,内网穿透,后续将实现websocket代理等,会将实现 ...
- tableau用数值呈现条形图的总计
创建计算字段 创建计算字段:销售额总计,键入函数: IF Size()=1 THEN 0 ELSE Sum([销售额]) END 创建视图 将度量"销售额"拖放至列,将维度&quo ...
- 每天5分钟复习OpenStack(十二)Ceph FileStore 和 BlueSotre
一个最小化的Ceph集群需要三个组件MON MGR OSD.上一章我们部署了MON,本章节我们完成剩下MGR 和OSD 的部署.在文末我们将重点介绍下什么是FileStore和BlueStore,并详 ...
- 09 - Shell流程控制语句
1. if-else语句 能够使用if条件语句进行条件判断 1.1 if 语法 if 条件 then 命令 fi if 条件; then 命令; fi 1.2 if-else 语法 if 条件 the ...
- [ABC265F] Manhattan Cafe
Problem Statement In an $N$-dimensional space, the Manhattan distance $d(x,y)$ between two points $x ...
- idea用不了 idea.bat文件闪退
由于idea的智能,在破解之后会留下一些问题,根据网上搜出来的解决办法. 1.C:\Users\dell\AppData\Roaming\JetBrains\IntelliJIdea2022.2 在这 ...
- CentOS 8.1成功安装最新Node.js 20教程(含用到的全部命令和截图演示)
yum换镜像和源 CentOS 已经停止维护的问题.2020 年 12 月 8 号,CentOS 官方宣布了停止维护 CentOS Linux 的计划,并推出了 CentOS Stream 项目,Ce ...