Hugging News #0814: Llama 2 学习资源大汇总 🦙
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」。本期 Hugging News 有哪些有趣的消息,快来看看吧!
重磅更新
Llama 2 学习资源大汇总!

Llama 2 是由 Meta 推出的新型开放式大型语言模型。我们很高兴能够将其全面集成入 Hugging Face,并全力支持其发布。通过 Hugging Face,它可以免费用于研究和商业用途。预训练模型基于 2 万亿令牌进行训练,上下文长度是 Llama 1 的两倍!你可以在 Hugging Face 上找到具有 70 亿、130 亿和 700 亿参数的模型
通过与 Meta 合作,我们已经顺利地完成了对 Llama 2 的集成,你可以在 Hub 上找到 12 个开放模型 (3 个基础模型以及 3 个微调模型,每个模型都有 2 种 checkpoint: 一个是 Meta 的原始 checkpoint,一个是 Transformers 格式的 checkpoint)。以下列出了 Hugging Face 支持 Llama 2 的主要工作:
Llama 2 已入驻 Hub: 包括模型卡及相应的许可证。
支持 Llama 2 的 Transformers 库
使用单 GPU 微调 Llama 2 小模型的示例
Text Generation Inference (TGI) 已集成 Llama 2,实现快速高效的生产化推理
推理终端 (Inference Endpoints) 已集成 Llama 2
我们为大家准备了两篇文章,帮助大家更好的学习理解和使用 Llama 2。在第一篇文章中,我们讨论了以下几点:
为什么选择 Llama 2?
Demo 演示
使用 Transformers 进行推理
使用推理终端(Inference Endpoints)进行推理
使用 PEFT 进行微调
如何提示(prompt) Llama 2
在第二篇文章中,我们对 Llama 2 进行了如下的讨论:
Llama 2 是什么?
你可以用来测试 Llama 2 的不同的 playgrounds
Llama 2 模型背后的研究
Llama 2 的性能如何,基准测试
如何正确设置对话模型的提示
如何使用 PEFT 对 Llama 2 进行训练
如何部署 Llama 2 以进行推断
https://www.philschmid.de/llama-2
Llama 2 现已登陆 Hugging Chat

现在在 Hugging Chat 可以尝试免费使用 Llama 2 70B 聊天模型(在页面右上角选择模型 Llama-2-70b-chat-hf 即可),享受超快的推断速度、网络搜索功能!
http://hf.co/chat
这个项目由以下技术支持:
文本生成推理(Text-generation-inference),用于生产环境的大型语言模型服务工具: https://github.com/huggingface/text-generation-inference
Hugging Face 的开源的大型语言模型用户界面 Chat UI: https://github.com/huggingface/chat-ui
Llama 2 模型:https://huggingface.co/meta-llama
使用 Autotrain 对 Llama 2 进行微调

这个视频讲述了如何使用 Hugging Face 的 Autotrain 在 Google Colab 的免费版本上对 Llama 2 进行训练。这是在 Google Colab 的免费版本或者在本地计算机上使用自定义数据集进行 llama-v2 微调的简单的方法,这个方法也适用于任何其他 LLM。AutoTrain 是自动训练和部署机器学习模型的一种方式,可以与 Hugging Face 的生态系统无缝集成。
https://youtube.com/watch?v=3fsn19OI_C8&ab_channel=AbhishekThakur
用几行代码就可使用自己的数据训练 Llama 2!
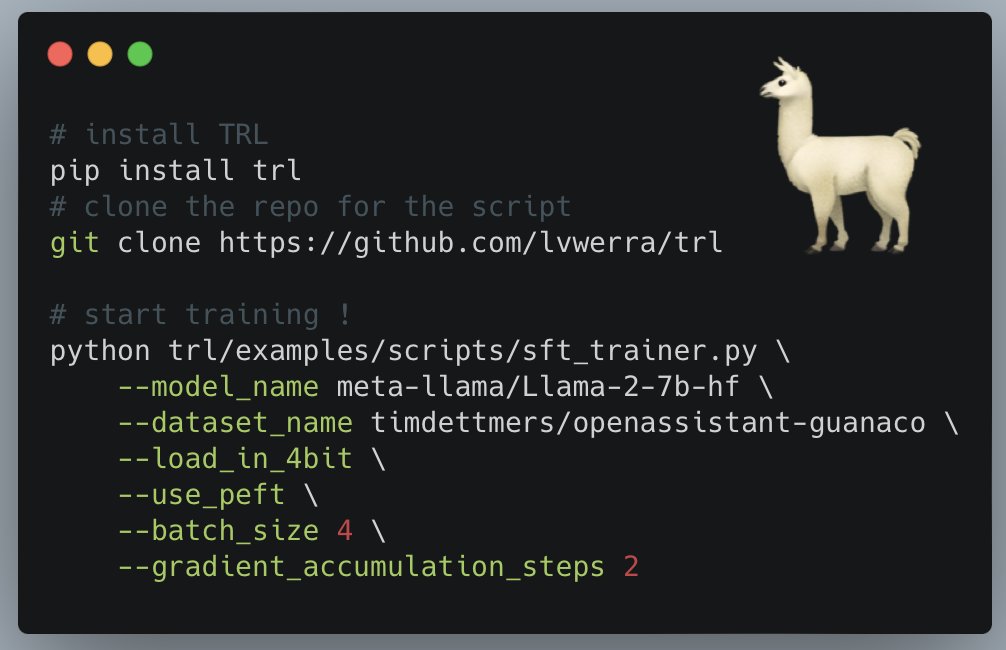
你可以在短短几行代码中对所有 Llama-2 模型使用自己的数据进行训练!通过使用 4-bit 和 PEFT,即使在单个 A100 GPU 上,这个脚本也可以用于 70B 模型的训练。你可以在 T4 GPU 上进行 7B 的训练(即在 Colab 上可以免费获取的资源),或者在 A100 GPU 上进行 70B 的训练。
4-bit 在这里指的是四位量化(4-bit quantization),是一种将模型的权重量化为更低比特数的技术。在深度学习中,通常模型的权重会以较高的浮点数表示,这需要更大的存储和计算资源。通过量化,可以将权重表示为更短的二进制位数,从而减小模型的存储需求和计算成本。四位量化意味着权重将被表示为只有 4 个二进制位的数字,这样可以大幅减小权重的表示大小。然而,量化也会引入一定的信息损失,因为权重的精度被降低了。为了缓解这种损失,通常会使用特殊的量化技术,如对称量化或非对称量化,以尽量保留模型的性能。
PEFT(Parameter Efficient Fine-Tuning)是一种用于微调神经网络模型的技术,旨在在保持模型性能的同时,显著减少微调所需的计算资源和时间。这对于在资源有限的环境下进行模型微调非常有用。PEFT 的主要思想是通过使用较小的学习率来微调模型的一部分参数,而不是对整个模型的所有参数进行微调。具体来说,PEFT 将模型的参数分为不同的组,然后在每个组上应用不同的学习率。这样可以将微调的计算开销分布到多个小批次中,从而减少了每个小批次的计算负担,使得模型可以在较小的设备上进行高效微调。
你可以轻松地使用 SFTTrainer 和官方脚本对 Llama2 模型进行微调。例如,要对 llama2-7b 在 Guanaco 数据集上进行微调,请运行以下命令(已在单个 NVIDIA T4-16GB 上进行了测试):
'''
python examples/scripts/sft_trainer.py --model_name meta-llama/Llama-2-7b-hf --dataset_name timdettmers/openassistant-guanaco --load_in_4bit --use_peft --batch_size 4 --gradient_accumulation_steps 2
'''
了解更多:https://hf.co/docs/trl/main/en/lora_tuning_peft#finetuning-llama2-model
完整脚本:https://github.com/lvwerra/trl/blob/main/examples/scripts/sft_trainer.py
以上就是本期的 Hugging News,新的一周开始了,我们一起加油!
额外内容:
Hugging Face 加入 PyTorch 基金会并成为首要成员

本周,作为一个深度学习社区的中立家园,PyTorch 基金会宣布 Hugging Face 已加入为首要成员。
Hugging Face 一直是 PyTorch 生态系统的长期支持者和贡献者,通过提供强大的模型和资源加速了 AI 技术的研究、开发和应用,特别是在自然语言处理领域。
“我们的使命一直是民主化 AI,使之可供所有人使用。我们与 PyTorch 的目标实现从业者减少进入门槛的目标是真正一致的。通过加入 PyTorch 基金会,我们可以进一步放大这种影响,并支持生态系统中非常重要的 PyTorch 框架。”Hugging Face 开源负责人 Lysandre Debut 表示。“我们相信这两个生态系统有很大的重叠,与基金会合作将使我们能够弥合差距,向机器学习社区提供最好的软件和最好的工具。”
Hugging Face 的模型中心和开源库促进了 AI 开源社区内的协作和知识共享,使 Hugging Face 与不断壮大的 PyTorch 基金会非常匹配。他们继续通过创建用户友好的工具和资源以及提供易于使用和有文档记录的库来推动行业的采用和协作。
作为首要成员,Hugging Face 获得了一席 PyTorch 基金会治理委员会的席位。该委员会通过我们的章程、使命和愿景声明制定政策,描述基金会倡议的总体范围、技术愿景和方向。
TRL 正式推出,来训练你的首个 RLHF 模型吧

正式向大家介绍 TRL——Transformer Reinforcement Learning。这是一个超全面的全栈库,包含了一整套工具用于使用强化学习 (Reinforcement Learning) 训练 transformer 语言模型。从监督调优 (Supervised Fine-tuning step, SFT),到训练奖励模型 (Reward Modeling),再到近端策略优化 (Proximal Policy Optimization),实现了全面覆盖!并且 TRL 库已经与 transformers 集成,方便你直接使用!
文档地址在这里:https://hf.co/docs/trl/
小编带大家简单看看 API 文档里各个部分对应了什么需求:
Model Class: 涵盖了每个公开模型各自用途的概述
SFTTrainer: 帮助你使用 SFTTrainer 实现模型监督调优
RewardTrainer: 帮助你使用 RewardTrainer 训练奖励模型
PPOTrainer: 使用 PPO 算法进一步对经过监督调优的模型再调优
Best-of-N Samppling: 将“拔萃法”作为从模型的预测中采样的替代方法
DPOTrainer: 帮助你使用 DPOTrainer 完成直接偏好优化
文档中还给出了几个例子供 宝子们参考:
Sentiment Tuning: 调优模型以生成更积极的电影内容
Training with PEFT: 执行由 PEFT 适配器优化内存效率的 RLHF 训练
Detoxifying LLMs: 通过 RLHF 为模型解毒,使其更符合人类的价值观
StackLlama: 在 Stack exchange 数据集上实现端到端 RLHF 训练一个 Llama 模型
Multi-Adapter Training: 使用单一模型和多适配器实现优化内存效率的端到端训练
宝子们快行动起来,训练你的第一个 RLHF 模型吧!
Hugging News #0814: Llama 2 学习资源大汇总 🦙的更多相关文章
- C#开源资源大汇总
C#开源资源大汇总 C#开源资源大汇总 一.AOP框架 Encase 是C#编写开发的为.NET平台提供的AOP框架.Encase 独特的提供了把方面(aspects)部署到运行 ...
- [转]swift 学习资源 大集合
今天看到了一个swift的学习网站,里面收集了很多学习资源 [转自http://blog.csdn.net/sqc3375177/article/details/29206779] Swift 介绍 ...
- swift 学习资源 大集合
今天看到一个swift学习网站,其中我们收集了大量的学习资源 Swift 介绍 Swift 介绍 来自 Apple 官方 Swift 简单介绍 (@peng_gong) 一篇不错的中文简单介绍 [译] ...
- Git学习资源收集汇总
伴随着知乎上一个问题:GitHub 是怎么火起来的?被顶起200+的回答说到:Github不是突然火起来的,在Ruby社区Github其实从一开始就很流行,我们2009年搞Ruby大会就邀请了Gith ...
- 读书分享全网学习资源大合集,推荐Python3标准库等五本书「02」
0.前言 在此之前,我已经为准备学习python的小白同学们准备了轻量级但超无敌的python开发利器之visio studio code使用入门系列.详见 1.PYTHON开发利器之VS Code使 ...
- 读书分享全网学习资源大合集,推荐Python学习手册等三本书「01」
0.前言 在此之前,我已经为准备学习python的小白同学们准备了轻量级但超无敌的python开发利器之visio studio code使用入门系列.详见 1.PYTHON开发利器之VS Code之 ...
- 【分享】Python学习资源大合集
地址:http://www.hejizhan.com/html/xueke/520/x520_03.html Python安装软件合集(Windows)(78) Python教程——游戏编程(13) ...
- [爬虫资源]各大爬虫资源大汇总,做我们自己的awesome系列
大数据的流行一定程序导致的爬虫的流行,有些企业和公司本身不生产数据,那就只能从网上爬取数据,笔者关注相关的内容有一定的时间,也写过很多关于爬虫的系列,现在收集好的框架希望能为对爬虫有兴趣的人,或者 ...
- 优秀Python学习资源收集汇总(强烈推荐)
Python是一种面向对象.直译式计算机程序设计语言.它的语法简捷和清晰,尽量使用无异义的英语单词,与其它大多数程序设计语言使用大括号不一样,它使用縮进来定义语句块.与Scheme.Ruby.Perl ...
- [转]优秀Python学习资源收集汇总
Python是一种面向对象.直译式计算机程序设计语言.它的语法简捷和清晰,尽量使用无异义的英语单词,与其它大多数程序设计语言使用大括号不一样,它使用縮进来定义语句块.与Scheme.Ruby.Perl ...
随机推荐
- 2020-12-10:i++是原子操作吗?为什么?
福哥答案2020-12-10: 不是原子操作.i++分为三个阶段:1.内存到寄存器.2.寄存器自增.3.写回内存.这三个阶段中间都可以被中断分离开.***[评论](https://user.qzone ...
- Java 网络编程 —— 非阻塞式编程
线程阻塞概述 在生活中,最常见的阻塞现象是公路上汽车的堵塞.汽车在公路上快速行驶,如果前方交通受阻,就只好停下来等待,等到公路顺畅,才能恢复行驶. 线程在运行中也会因为某些原因而阻塞.所有处于阻塞状态 ...
- Selenium - 元素操作(4) - alert弹窗处理
Selenium - 元素操作 alert弹窗 Alert弹出框由于不是html的页面元素,而是JavaScript的控件:所以不能右键检查,用传统的方法去操作. 例如这种弹窗: # 获取告警弹框的文 ...
- 一些JS过滤方法
一般过滤器我们都会卸载过滤filter文件内 本文这里就直接写正常methods格式的 //过滤空格 filterSpaces(data) { return data.replace(/\s+/g, ...
- 去掉DosBox烦人的Status Windows
首先我们上成品动态图 很干净,很清爽有没有! 步骤 1.找到并选中DosBox快捷方式,鼠标右键点击选择属性 2.修改目标后面的参数,默认是 -userconf ,再添加一个 -noconsole 就 ...
- 手把手教你如何在 Linux 上源码安装最新版本 R
如果你使用的 Linux 系统 GCC 版本太低,又没有 root 权限(即使有 root 权限又担心升级 GCC 带来的风险):同时你又不想额外多安装多一个 Anaconda 或者 Minicond ...
- Git 多账号配置
本地登录多账号并连接对应的远程仓库,主要就是 密钥配对,我这里刚开始配了密钥也将密钥复制到ssh但是还是连接不到第二个远程仓库,后来发现是需要 密钥代理 1.在当前项目下更改git账号信息: git ...
- MultiscaleResNet50:AnEfficientandAccurateApproachforIma
目录 标题:<51. Multi-scale ResNet-50: An Efficient and Accurate Approach for Image Recognition> 背景 ...
- 数据库系统架构:从HBase到InfluxDB的变革
目录 数据库系统架构:从 HBase 到 InfluxDB 的变革 2. 技术原理及概念 2.1 基本概念解释 2.2 技术原理介绍 2.3 相关技术比较 3. 实现步骤与流程 3.1 准备工作:环境 ...
- 记一次 .NET 某企业采购平台 崩溃分析
一:背景 1. 讲故事 前段时间有个朋友找到我,说他们的程序有偶发崩溃的情况,让我帮忙看下怎么回事,针对这种 crash 的程序,用 AEDebug 的方式抓取一个便知,有了 dump 之后接下来就可 ...