JUC并发编程学习笔记(十)线程池(重点)
线程池(重点)
线程池:三大方法、七大参数、四种拒绝策略
池化技术
程序的运行,本质:占用系统的资源!优化资源的使用!-> 池化技术(线程池、连接池、对象池......);创建和销毁十分消耗资源
池化技术:事先准备好一些资源,有人要用就拿,拿完用完还给我。
线程池的好处:
1、降低资源消耗
2、提高相应速度
3、方便管理
线程复用、可以控制最大并发数、管理线程
线程池:三大方法
1、newSingleThreadExecutor
单列线程池,只有一条线程;
单例线程池配合callable使用,注意需要在程序运行结束后关闭线程池
package org.example.pool;
import java.util.concurrent.*;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
//Executors->工具类
public class Demo01 {
public static void main(String[] args) {
TestCallable able = new TestCallable();
//三大方法
ExecutorService threadPool = Executors.newSingleThreadExecutor();//单个线程
try {
for (int i = 0; i < 10; i++) {
FutureTask<String> task = new FutureTask<String>(able);
//线程池创建线程
threadPool.execute(task);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//线程池用完,程序结束,关闭线程池
threadPool.shutdown();
}
// Executors.newFixedThreadPool(5);//固定线程池大小
// Executors.newCachedThreadPool();//可伸缩的线程池
}
}
class TestCallable implements Callable<String> {
Lock lock = new ReentrantLock();
@Override
public String call() throws Exception {
TimeUnit.SECONDS.sleep(2);
System.out.println(Thread.currentThread().getName() + ":ok");
return Thread.currentThread().getName() + ":ok";
}
}
注意结果图

在单例线程池中,运行结果发现都是同一条线程在操作资源,整个线程池中只有一条pool-1-thread-1线程。
2、newFixedThreadPool
同样的代码,将线程池切换为固定大小的线程池,设置为5条,这样跑出来的结果又不一样
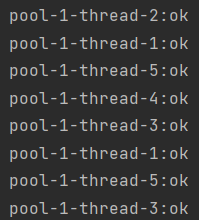
由于设置了线程休眠,所以会导致比较平均的结果出现,但是一般情况下都是五条线程抢占资源,每次结果都是不一定的,看那条线程处理的比较快抢占的比较多。
3、newCachedThreadPool
同样的代码,将线程池切换为可伸缩大小的线程池,这样跑出来的结果又不一样
根据业务代码生成具体条数的线程:如本次业务通过循环或其他因数,同时需要处理10条任务,那么当你线程池中的第一条线程还未完成任务时就会生成一条新的线程来同步处理这些任务,只要你cpu处理速度够快那么理论最高可能同时生成一个具有10条线程(任务数)的一个线程池。
七大参数
源码分析
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newFixedThreadPool(int nThreads) {
//和以上没有区别,只是通过用户调用来完成的,相当于new ThreadPoolExecutor(5, 5,....)
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool() {
//设置了默认是0个线程,但是最大值可以达到大约21亿条,设置了Integer.MAX_VALUE(约21亿)
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,//如果通过Integer.MAX_VALUE来跑线程池一定会照成OOM(溢出)
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
通过观察以上三大方法的创建线程池方式,可以发现,三大方法的本质都是调用ThreadPoolExecutor来创建的
public ThreadPoolExecutor(int corePoolSize,//核心线程池大小
int maximumPoolSize,//最大线程池大小
long keepAliveTime,//超时无调用释放
TimeUnit unit,//超时单位
BlockingQueue<Runnable> workQueue,//阻塞队列
ThreadFactory threadFactory,//线程工厂,创建线程的,一般不用动
RejectedExecutionHandler handler) {//拒绝策略
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
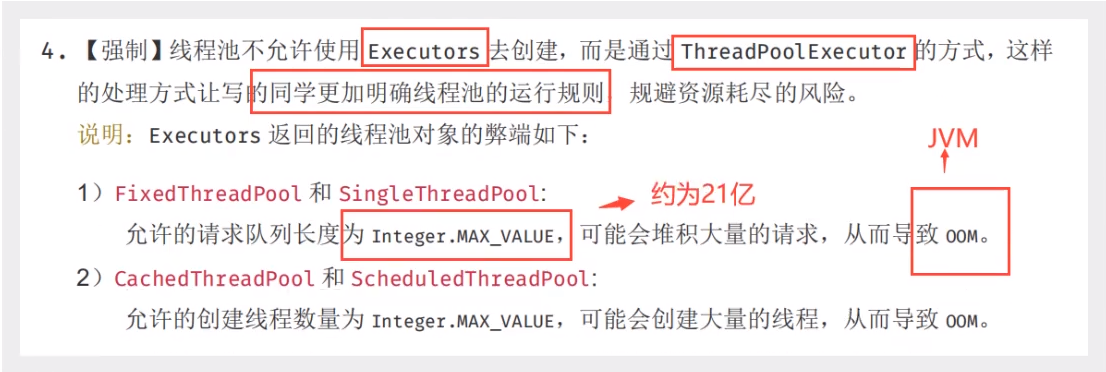
这就是为什么阿里巴巴开发规范中说不要使用Executors来创建线程池而是让我们通过ThreadPoolExecutor来创建,其实就是让我们通过了解线程池的本质来避免一些问题。
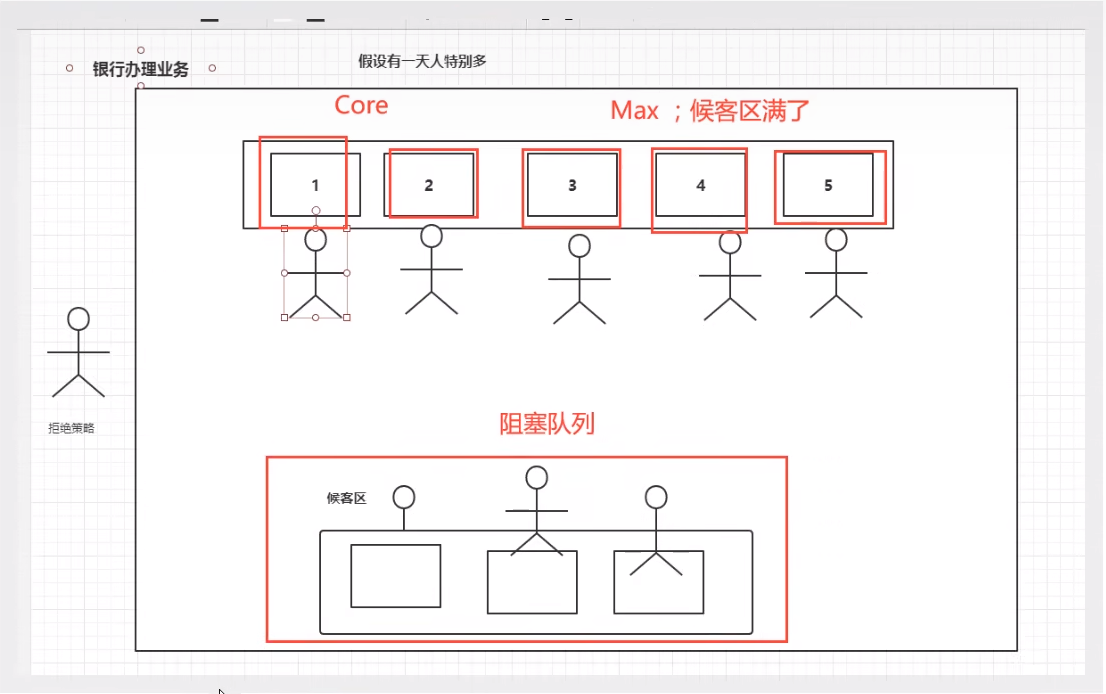
模拟银行业务模块模拟
package org.example.pool;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class Demo02 {
public static void main(String[] args) {
//自定义线程池,工作中只会使用ThreadPoolExecutor
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2,
5,
3,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
new ThreadPoolExecutor.AbortPolicy());//拒绝策略,即当阻塞队列和线程池线程都已经最大化运行没有任何位置可以处置接下来的元素了,就拒绝该元素进入并抛出异常
try {
//最大承载 队列Queue+max
for (int i = 0; i < 10; i++) {
//线程池创建线程
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName() + ":ok");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//线程池用完,程序结束,关闭线程池
threadPool.shutdown();
}
}
}
此时有10个任务,但是最大线程量只有5个,阻塞队列量只有三个,所以注定会有两个无法处理,此时触发拒绝策略,抛出异常并且拒绝该任务。
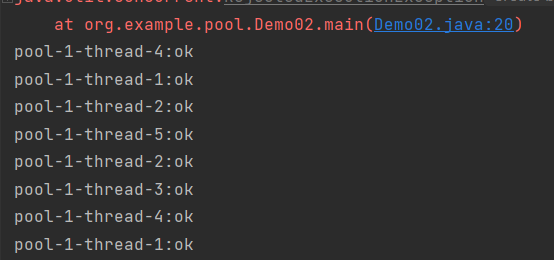
可以看到执行了八个任务,通过五条不同的线程。执行了拒绝策略抛出了异常java.util.concurrent.RejectedExecutionException
四种拒绝策略

四种拒绝策略的描述
//AbortPolicy 队列满了,丢掉任务,抛出异常
//CallerRunsPolicy 哪条线程给的任务回到哪条线程去执行,线程池不执行
//DiscardPolicy 队列满了,丢掉任务,但不抛出异常
//DiscardOldestPolicy 队列满了,尝试去和最早的竞争,如果没成功,依旧丢弃任务,但不抛出异常
小结和拓展
了解:IO密集型、cpu密集型(调优)
/*
* 最大线程到底该如何定义
* 1、CPU 密集型,几何就定义为几,就可以保证cpu效率最高的
* 2、IO 密集型 > 判断你程序中十分耗IO的线程,
* 程序 15个大小任务 io十分占用资源
* */
JUC并发编程学习笔记(十)线程池(重点)的更多相关文章
- JUC并发编程学习笔记
JUC并发编程学习笔记 狂神JUC并发编程 总的来说还可以,学到一些新知识,但很多是学过的了,深入的部分不多. 线程与进程 进程:一个程序,程序的集合,比如一个音乐播发器,QQ程序等.一个进程往往包含 ...
- JUC源码学习笔记5——线程池,FutureTask,Executor框架源码解析
JUC源码学习笔记5--线程池,FutureTask,Executor框架源码解析 源码基于JDK8 参考了美团技术博客 https://tech.meituan.com/2020/04/02/jav ...
- Java并发编程的艺术(十)——线程池(1)
线程池的作用 减少资源的开销 减少了每次创建线程.销毁线程的开销. 提高响应速度 每次请求到来时,由于线程的创建已经完成,故可以直接执行任务,因此提高了响应速度. 提高线程的可管理性 线程是一种稀缺资 ...
- Java并发编程的艺术(十)——线程池
线程池的作用 降低资源消耗.重复利用已有线程,减少线程的创建和销毁造成的消耗. 提高响应速度.当有任务需要处理的时候,就不用再花费重新创建线程的时间了. 提高线程的可管理性.不合理利用线程,会浪费资源 ...
- 并发编程学习笔记(14)----ThreadPoolExecutor(线程池)的使用及原理
1. 概述 1.1 什么是线程池 与jdbc连接池类似,在创建线程池或销毁线程时,会消耗大量的系统资源,因此在java中提出了线程池的概念,预先创建好固定数量的线程,当有任务需要线程去执行时,不用再去 ...
- 并发编程学习笔记(3)----synchronized关键字以及单例模式与线程安全问题
再说synchronized关键字之前,我们首先先小小的了解一个概念-内置锁. 什么是内置锁? 在java中,每个java对象都可以用作synchronized关键字的锁,这些锁就被称为内置锁,每个对 ...
- 并发编程学习笔记(15)----Executor框架的使用
Executor执行已提交的 Runnable 任务的对象.此接口提供一种将任务提交与每个任务将如何运行的机制(包括线程使用的细节.调度等)分离开来的方法.通常使用 Executor 而不是显式地创建 ...
- 并发编程学习笔记(12)----Fork/Join框架
1. Fork/Join 的概念 Fork指的是将系统进程分成多个执行分支(线程),Join即是等待,当fork()方法创建了多个线程之后,需要等待这些分支执行完毕之后,才能得到最终的结果,因此joi ...
- 并发编程学习笔记(8)----ThreadLocal的使用及源码分析
1. ThreadLocal的理解 ThreadLocal,顾名思义,就是线程的本地变量,ThreadLocal会为每个线程创建一个本地变量副本,使得使用ThreadLocal管理的变量在多线程的环境 ...
- 并发编程学习笔记(6)----公平锁和ReentrantReadWriteLock使用及原理
(一)公平锁 1.什么是公平锁? 公平锁指的是在某个线程释放锁之后,等待的线程获取锁的策略是以请求获取锁的时间为标准的,即使先请求获取锁的线程先拿到锁. 2.在java中的实现? 在java的并发包中 ...
随机推荐
- 抽象语法树AST必知必会
1 介绍 AST 打开前端项目中的 package.json,会发现众多工具已经占据了我们开发日常的各个角落,例如 JavaScript 转译.CSS 预处理.代码压缩.ESLint.Prettier ...
- 小白也能看懂的 ROC 曲线详解
作者:PrimiHub-Kevin ROC 曲线是一种坐标图式的分析工具,是由二战中的电子和雷达工程师发明的,发明之初是用来侦测敌军飞机.船舰,后来被应用于医学.生物学.犯罪心理学. 如今,ROC 曲 ...
- 根据图片搜索excel
问题描述:在excel使用中,当我们用大量的excel记录图文信息的时候,如果excel过多,比如成百上千个,里面都是包含大量的图片.这个时候如果想要根据图片快速找到这张图片可能被哪些excel包含, ...
- vs(visual stuiod)中vc++工程的Filter和Folder及vcxproj知识
vs中创建Filter 在一个新项目中右键 - Add - New,默认只有一选项 New Filter. 创建出来的Filter可以理解为是VS的过滤器(虚拟目录),它不会在本地的磁盘上新建目录,而 ...
- 学习JavaScript的路径
学习JavaScript的路径可以按照以下步骤进行: 了解基本概念:首先学习JavaScript的基本概念,包括变量.数据类型.运算符.数组.对象.循环和条件语句等.可以通过阅读相关的教材.在线课程或 ...
- 云服务器中Linux如何安装宝塔面板?
作者:西瓜程序猿 主页传送门:https://www.cnblogs.com/kimiliucn 官方使用手册:https://www.kancloud.cn/chudong/bt2017/42420 ...
- Unity 性能优化Shader分析处理函数:ShaderUtil.GetShaderGlobalKeywords用法
Unity 性能优化Shader分析处理函数:ShaderUtil.GetShaderGlobalKeywords用法 点击封面跳转下载页面 简介 Unity 性能优化Shader分析处理函数:Sha ...
- Vue源码学习(四):<templete>渲染第三步,将ast语法树转换为渲染函数
好家伙, Vue源码学习(三):<templete>渲染第二步,创建ast语法树, 在上一篇,我们已经成功将 我们的模板 转换为ast语法树 接下来我们继续进行操作 1.方法封装 由于 ...
- SQL Server 使用C#窗体与数据库连接,制作数据库查看器
SQL Server 使用C#窗体与数据库连接,制作数据库查看器 本文中心:讨论C#对SQL Server 的增删改查,使用Treeview制作数据库查看器. SSMS部分:确保SQL Server ...
- 主动写入流对@ResponseBody注解的影响
问题回溯 2023年Q2某日运营反馈一个问题,商品系统商家中心某批量工具模板无法下载,导致功能无法使用(因为模板是动态变化的) 商家中心报错(JSON串): {"code":-1, ...