[C++]二叉链-二叉树存储
二叉链存二叉树
预备知识
感谢:
代码参考:CSDN博主「云雨澄枫」的原创文章
代码解析
结构体 BiNode
template<class T>
struct BiNode{
T data;
BiNode<T> *lchild,*rchild;
};
Node 结点
这个结构体就是用来存储二叉链的每一个节点的
- data
表示这个节点所存的值
- *lchild & *rchild
表示指向 左子树 和 右子树 的指针
这样的结构能很好地存下二叉树:
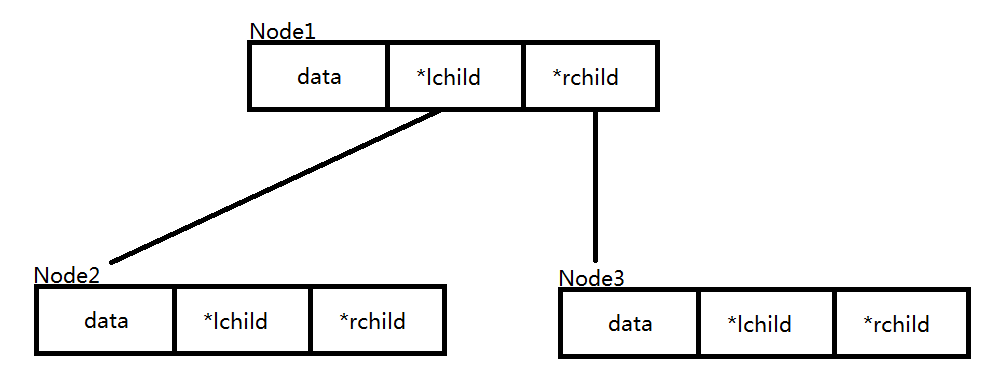
(具体的建树方法会放在后面解释)
类 BiTree
template <class T>
class BiTree{
public:
//构造 & 折构
BiTree(){root = Creat(root);}
~BiTree(){Release(root);}
//遍历
void PreOrder(){PreOrder(root);}
void InOrder(){InOrder(root);}
void PostOrder(){PostOrder(root);}
void LeverOrder();
//树的深度
int Depth(){Depth(root);}
//叶子结点数量
void CaculateLeafNum(){CaculateLeafNum(root);}
//交换左右子树
void swap(){swap(root);}
private:
BiNode<T> *root;//<-根节点在这里
BiNode<T> *Creat(BiNode<T> *bt);
void Release(BiNode<T> *bt);
void PreOrder(BiNode<T> *bt);
void InOrder(BiNode<T> *bt);
void PostOrder(BiNode<T> *bt);
int Depth(BiNode<T> *root);
void CaculateLeafNum(BiNode<T>* root);
void swap(BiNode<T> *root);
};
这便是树的主体
一个 BiTree 的类就代表一颗二叉树
- public
在这里定义了一些之后会用到的函数以及构造函数和折构函数
这里知道有这些东西即可
- private
这里则有一些 public 会用到的函数
以及这个树的根节点
构造函数 & 折构函数
- 构造函数
在类中 是这样写的:
BiTree(){root = Creat(root);}
构造这个树是通过 Creat 这个函数来实现的
Creat_Code:
template <class T>
BiNode<T> *BiTree<T>::Creat(BiNode<T> *bt)
{
T t;
cin >> t;
if(t == '#')
bt = NULL;
else {
bt = new BiNode<T>;
bt->data = t;
bt->lchild = Creat(bt->lchild);
bt->rchild = Creat(bt->rchild);
}
return bt;
}
在讲构造函数之前
还需要提一嘴其输入方式
这里是采用前序遍历的方式进行输入
同时还需要以 "#" 输入叶子结点的空子结点
例子:
cin:
ABD#G###CE##F##
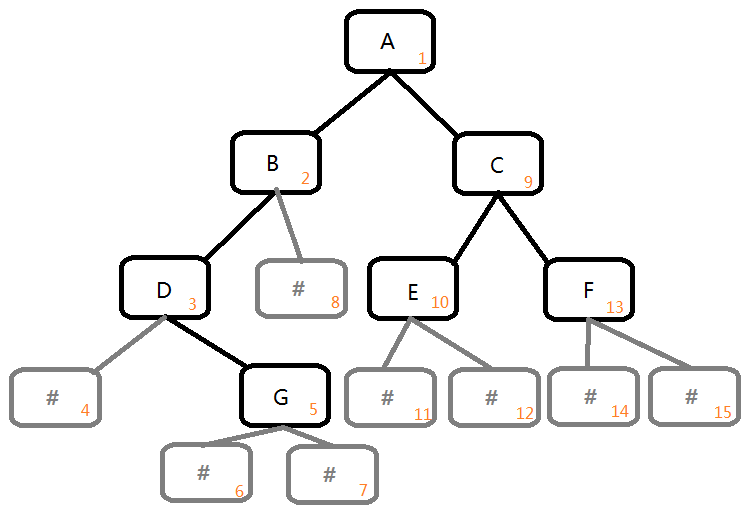
- 图中的序号即代表 cin 中的第几个字符
知道了输入的顺序之后
代码就变得好理解很多了
创建一个结点的时候
首先输入这个结点的值(就是 t)
若其值是 "#" 那就不继续往下面创造新结点了
直接让 bt 为 空指针
并把这个指针返回
若其值不为 "#"
那说明后面可能还有结点需要添加
就继续在左右子结点上调用 Creat函数
bt = new BiNode<T>;
这行代码可能还需要解释一下
new 是用来开辟新的内存空间的关键字
这里相当于开辟了一个新的结点结构体
而 bt 存下了这个结点结构体的指针
- 折构函数
~BiTree(){Release(root);}
折构函数和构造函数一样是用类名来作为函数名的
不过需要在前面加一个 "~"
这个函数调用了 Release 这个函数
template<class T>
void BiTree<T>::Release(BiNode<T> *bt){
if(bt != NULL){
Release(bt->lchild);
Release(bt->rchild);
delete bt;
}
}
delete 用于删除内存的关键词
这个函数因该很好理解
就是从上往下搜
从下往上删
就不过多解释了
遍历函数
这个分两部分将
第一部分 : 前/中/后序遍历
这些代码原理相同 就随便挑一个讲好了
template <class T>
void BiTree<T>::PreOrder(BiNode<T> *bt){
if (bt == NULL)
return;
else {
cout << bt->data;
PreOrder(bt->lchild);
PreOrder(bt->rchild);
}
}
从 root结点 开始搜索
如果不是空结点 那就直接输出
然后往两边找
决定前中后的只在于
输出与往两侧搜索语句的顺序
第二部分 : 层序遍历
还是用这个图
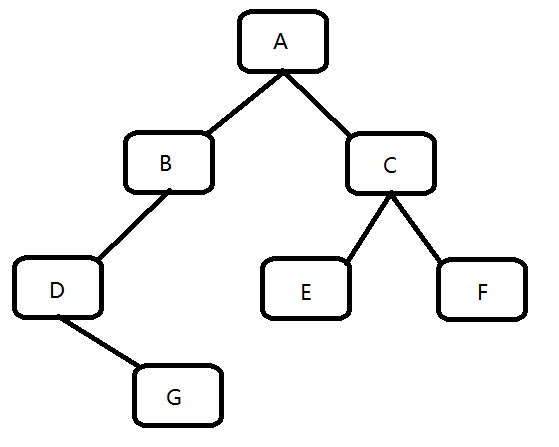
Code:
template<class T>
void BiTree<T>::LeverOrder(){
int front = -1,rear = -1;
BiNode<T> *Q[100];
if(root == NULL) return;
Q[++rear] = root;
while(front != rear){
BiNode<T> *q = Q[++front];
cout << q->data;
if(q->lchild != NULL) Q[++rear] = q->lchild;
if(q->rchild != NULL) Q[++rear] = q->rchild;
}
}
这里是用一个数组和两个变量来实现了队列的功能
接下来我们来模拟一下
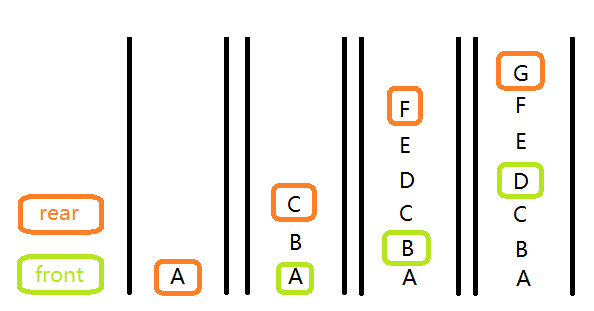
这样就可以实现层序遍历了
求树的深度
Code:
template<class T>
int BiTree<T>::Depth(BiNode<T> *root){
int hl,hr;
if(root == NULL)
return 0;
else{
hl = Depth(root->lchild);
hr = Depth(root->rchild);
return max(hl,hr) + 1;
}
}
深度要找的是最深的叶子结点的层数
因此直接左右找取最大值即可
求叶子结点数量
Code:
template<class T>
void BiTree<T>::CaculateLeafNum(BiNode<T> *root){
if(!root) return;
if(root->lchild == NULL && root->rchild == NULL) Leaf_Count++;
CaculateLeafNum(root->lchild);
CaculateLeafNum(root->rchild);
}
首先我们要知道叶子结点的特征:
没有儿子节点
(就是所有儿子节点都为 NULL)
所以左右搜找到无儿子 +1 即可
交换左右子树
template<class T>
void BiTree<T>::swap(BiNode<T> *root){
BiNode<T> *temp;
if(root == NULL)
return;
else{
temp = root->lchild;
root->lchild = root->rchild;
root->rchild = temp;
swap(root->lchild);
swap(root->rchild);
}
}
由于二叉链的本质就是指针的堆叠
因此直接交换指针的存值就可以了
Code
#include<bits/stdc++.h>
using namespace std;
template<class T>
struct BiNode{
T data;
BiNode<T> *lchild,*rchild;
};
template <class T>
class BiTree{
public:
//构造 & 折构
BiTree(){root = Creat(root);}
~BiTree(){Release(root);}
//遍历
void PreOrder(){PreOrder(root);}
void InOrder(){InOrder(root);}
void PostOrder(){PostOrder(root);}
void LeverOrder();
//树的深度
int Depth(){Depth(root);}
//叶子结点数量
void CaculateLeafNum(){CaculateLeafNum(root);}
//交换左右子树
void swap(){swap(root);}
private:
BiNode<T> *root;
BiNode<T> *Creat(BiNode<T> *bt);
void Release(BiNode<T> *bt);
void PreOrder(BiNode<T> *bt);
void InOrder(BiNode<T> *bt);
void PostOrder(BiNode<T> *bt);
int Depth(BiNode<T> *root);
void CaculateLeafNum(BiNode<T>* root);
void swap(BiNode<T> *root);
};
int Leaf_Count = 0;
template <class T>
BiNode<T> *BiTree<T>::Creat(BiNode<T> *bt)
{
T t;
cin >> t;
if(t == '#')
bt = NULL;
else {
bt = new BiNode<T>;
bt->data = t;
bt->lchild = Creat(bt->lchild);
bt->rchild = Creat(bt->rchild);
}
return bt;
}
template<class T>
void BiTree<T>::Release(BiNode<T> *bt){
if(bt != NULL){
Release(bt->lchild);
Release(bt->rchild);
delete bt;
}
}
template <class T>
void BiTree<T>::PreOrder(BiNode<T> *bt){
if(bt == NULL)
return;
else {
cout << bt->data;
PreOrder(bt->lchild);
PreOrder(bt->rchild);
}
}
template<class T>
void BiTree<T>::InOrder(BiNode<T> *bt){
if(bt == NULL)
return;
else{
InOrder(bt->lchild);
cout << bt->data;
InOrder(bt->rchild);
}
}
template<class T>
void BiTree<T>::PostOrder(BiNode<T> *bt){
if(bt == NULL)
return;
else{
PostOrder(bt->lchild);
PostOrder(bt->rchild);
cout << bt->data;
}
}
template<class T>
void BiTree<T>::LeverOrder(){
int front = -1,rear = -1;
BiNode<T> *Q[100];
if(root == NULL) return;
Q[++rear] = root;
while(front != rear){
BiNode<T> *q = Q[++front];
cout << q->data;
if(q->lchild != NULL) Q[++rear] = q->lchild;
if(q->rchild != NULL) Q[++rear] = q->rchild;
}
}
template<class T>
int BiTree<T>::Depth(BiNode<T> *root){
int hl,hr;
if(root == NULL)
return 0;
else{
hl = Depth(root->lchild);
hr = Depth(root->rchild);
return max(hl,hr) + 1;
}
}
template<class T>
void BiTree<T>::CaculateLeafNum(BiNode<T> *root){
if(!root) return;
if(root->lchild == NULL && root->rchild == NULL) Leaf_Count++;
CaculateLeafNum(root->lchild);
CaculateLeafNum(root->rchild);
}
template<class T>
void BiTree<T>::swap(BiNode<T> *root){
BiNode<T> *temp;
if(root == NULL)
return;
else{
temp = root->lchild;
root->lchild = root->rchild;
root->rchild = temp;
swap(root->lchild);
swap(root->rchild);
}
}
int main(){
BiTree<char>* bitree=new BiTree<char>;
cout<<"前序遍历";
bitree->PreOrder();
cout << endl;
cout<<"中序遍历";
bitree->InOrder();
cout << endl;
cout<<"后序遍历";
bitree->PostOrder();
cout << endl;
cout<<"层序遍历";
bitree->LeverOrder();
cout << endl;
cout<<"深度:"<<bitree->Depth()<<endl;
bitree->CaculateLeafNum();
cout<<"叶子结点个数:"<<Leaf_Count<<endl;
bitree->swap();
cout<<"左右子树交换后的层序:";
bitree->LeverOrder();
return 0;
}
[C++]二叉链-二叉树存储的更多相关文章
- 二叉搜索树 & 二叉树 & 遍历方法
二叉搜索树 & 二叉树 & 遍历方法 二叉搜索树 BST / binary search tree https://en.wikipedia.org/wiki/Binary_searc ...
- HDU3791二叉搜索树(二叉树)
Problem Description 判断两序列是否为同一二叉搜索树序列 Input 开始一个数n,(1<=n<=20) 表示有n个需要判断,n= 0 的时候输入结束.接下去一行是一 ...
- 二叉苹果树 - 二叉树树型DP
传送门 中文题面: 题目描述 有一棵苹果树,如果树枝有分叉,一定是分 2 叉(就是说没有只有 1 个儿子的结点,这棵树共有N 个结点(叶子点或者树枝分叉点),编号为1-N,树根编号一定是1. 我们用一 ...
- 数据结构图文解析之:二叉堆详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构-二叉搜索树的js实现
一.树的相关概念 1.基本概念 子树 一个子树由一个节点和它的后代构成. 节点的度 节点所拥有的子树的个数. 树的度 树中各节点度的最大值 节点的深度 节点的深度等于祖先节点的数量 树的高度 树的高度 ...
- 二叉堆 及 大根堆的python实现
Python 二叉堆(binary heap) 二叉堆是一种特殊的堆,二叉堆是完全二叉树或者是近似完全二叉树.二叉堆满足堆特性:父节点的键值总是保持固定的序关系于任何一个子节点的键值,且每个节点的左子 ...
- javascript实现二叉搜索树
在使用javascript实现基本的数据结构中,练习了好几周,对基本的数据结构如 栈.队列.链表.集合.哈希表.树.图等内容进行了总结并且写了笔记和代码. 在 github中可以看到 点击查看,可以 ...
- 二叉树的二叉链表存储结构及C++实现
前言:存储二叉树的关键是如何表示结点之间的逻辑关系,也就是双亲和孩子之间的关系.在具体应用中,可能要求从任一结点能直接访问到它的孩子. 一.二叉链表 二叉树一般多采用二叉链表(binary linke ...
- [数据结构]——二叉树(Binary Tree)、二叉搜索树(Binary Search Tree)及其衍生算法
二叉树(Binary Tree)是最简单的树形数据结构,然而却十分精妙.其衍生出各种算法,以致于占据了数据结构的半壁江山.STL中大名顶顶的关联容器--集合(set).映射(map)便是使用二叉树实现 ...
- C#实现二叉树--二叉链表结构
二叉树的简单介绍 关于二叉树的介绍请看这里 : 二叉树的简单介绍 http://www.cnblogs.com/JiYF/p/7048785.html 二叉链表存储结构: 二叉树的链式存储结构是指,用 ...
随机推荐
- BugKu-Misc-Photo的自我修养
下载附件 打开002文件夹,发现一张照片 看到PNG右下疑似有半个字符,怀疑PNG宽高被修改 拿到测PNG宽高的脚本 点击查看代码 import binascii import struct crcb ...
- spring-mvc系列:详解@RequestMapping注解(value、method、params、header等)
目录 一.@RequestMapping注解的功能 二.@RequestMapping注解的位置 三.@RequestMapping注解的value属性 四.@RequestMapping注解的met ...
- K8S | Config应用配置
绕不开的Config配置: 一.背景 在自动化流程中,对于一个应用来说,从开发阶段的配置管理,到制作容器镜像,再到最后通过K8S集群发布为服务,整个过程涉及到的配置非常多: 应用环境:通常是指代码层面 ...
- 测试与爬虫—抓包神器之Charles
前言 之前我们讲到过fiddler(https://www.cnblogs.com/zichliang/p/16067941.html),wireshark(https://www.cnblogs.c ...
- [shell]在curl测试的data参数中引用变量
在curl测试的data参数中引用变量 前言 在使用curl接口进行接口传参时,常会使用如下方法: #!/bin/bash url="http://192.168.0.10:8000/api ...
- 简述redis的单线程模式
前言 在redis版本6之前,网络IO和键值对读写都是由一个线程来完成的.而redis的其他功能,比如持久化.异步删除.集群数据同步等,是由其他线程完成的. 为什么采用单线程 多线程有助于提升吞吐率( ...
- LeetCode买卖股票之一:基本套路(122)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 关于<LeetCode买卖股票>系列 在L ...
- 回归克里格、普通克里格插值在ArcGIS中的实现
本文介绍基于ArcMap软件,实现普通克里格.回归克里格方法的空间插值的具体操作. 目录 1 背景知识准备 2 回归克里格实现 2.1 采样点与环境变量提取 2.2 子集要素划分 2.3 异常值提 ...
- Jmeter获取Websocket多帧消息的实现方法
由于需要对WebSocket进行压力测试,因此又回归到了JMeter的使用.网络上缺少具体的获取多帧消息的操作,且自己也踩了两个坑,总结一下可行的操作供大家参考. 一.情况说明 ...
- 火山引擎DataLeap的数据血缘用例与设计概述
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 数据血缘描述了数据的来源和去向,以及数据在多个处理过程中的转换.数据血缘是组织内使数据发挥价值的重要基础能力. ...