通过 KoP 将 Kafka 应用迁移到 Pulsar
通过 KoP 将 Kafka 应用迁移到 Pulsar
版权声明:原文出自 https://github.com/streamnative/kop ,由 Redisant 进行整理和翻译
什么是 KoP
KoP(Pulsar on Kafka)通过在 Pulsar Broker 上引入 Kafka 协议处理程序,为 Apache Pulsar 带来原生 Apache Kafka 协议支持。 通过将 KoP 协议处理程序添加到您现有的 Pulsar 集群,您可以将现有的 Kafka 应用程序和服务迁移到 Pulsar,而无需修改代码。 这使 Kafka 应用程序能够利用 Pulsar 的强大功能,例如:
- 通过企业级多租户简化运营
- 使用rebalance-free架构简化操作
- 使用 Apache BookKeeper 分层存储
- 使用 Pulsar Functions 进行Serverless事件处理
KoP 作为 Pulsar 协议处理插件,在 Pulsar broker 启动时加载。 它通过在 Apache Pulsar 上提供原生 Kafka 协议支持,帮助减少人们采用 Pulsar 实现业务的障碍。
通过整合两个流行的事件流生态系统,KoP 解锁了新的用例。 您可以利用每个生态系统的优势,使用 Apache Pulsar 构建一个真正统一的事件流平台,以加速实时应用程序和服务的开发。
KoP 利用 Pulsar 已有的组件(例如主题发现、分布式日志库 - ManagedLedger、游标等)在 Pulsar 上实现了 Kafka wire 协议。
下图说明了 KoP 是如何在 Pulsar 中实现的:
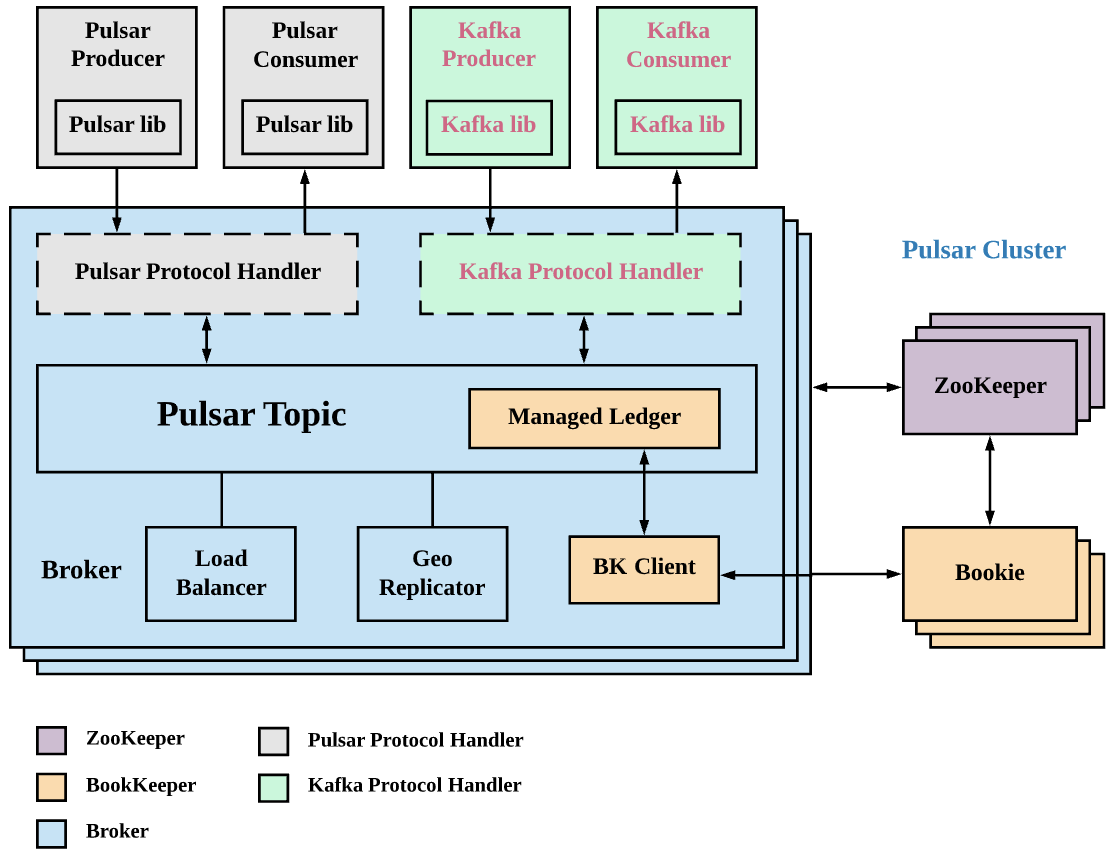
安装 KoP
如果您有 Apache Pulsar 集群,则可以通过直接下载 KoP 协议处理程序并将其安装到 Pulsar Broker,在现有 Pulsar 集群上启用 Kafka-on-Pulsar。 它需要三个步骤:
- 下载 KoP 协议处理程序,然后将其复制到您的 Pulsar
protocols目录。 - 在 Pulsar
broker.conf或standalone.conf文件中设置 KoP 协议处理程序的配置。 - 重启 Pulsar broker 以加载 KoP 协议处理程序。
然后你可以启动你的Broker并使用 KoP。 以下是每个步骤的详细说明。
下载 KoP 协议处理程序
您可以在这里直接下载 KoP 协议处理程序。
chen_ubuntu@LAPTOP-IH0640SI:~/start_pulsar/apache-pulsar-2.10.3/protocols$ ls
pulsar-protocol-handler-kafka-2.10.3.3.nar
配置 KoP
将 .nar 文件复制到 Pulsar protocols 目录后,您需要通过在 Pulsar 配置文件 broker.conf 或 standalone.conf 中添加配置来配置 Pulsar broker 以插件形式运行 KoP 协议处理程序。
在
broker.conf或standalone.conf文件中设置 KoP 协议处理程序的配置。messagingProtocols=kafka
protocolHandlerDirectory=./protocols
allowAutoTopicCreationType=partitioned
narExtractionDirectory=./unpacked
属性名 默认值 建议值 messagingProtocols kafka protocolHandlerDirectory ./protocols Location of KoP NAR file allowAutoTopicCreationType non-partitioned partitioned narExtractionDirectory /tmp/pulsar-nar Location of unpacked KoP NAR file 默认情况下,
allowAutoTopicCreationType设置为未分区。 由于主题在 Kafka 中默认是分区的,因此最好避免为 Kafka 客户端创建非分区主题,除非 Kafka 客户端需要与现有的非分区主题进行交互。默认情况下,
/tmp/pulsar-nar目录位于/tmp目录下。 如果我们将 KoP NAR 文件解包到/tmp目录,一些类可能会被系统自动删除,这将产生一个ClassNotFoundException或NoClassDefFoundError错误。 因此,建议将narExtractionDirectory选项设置为其他路径。设置 Kafka listeners
# Use `kafkaListeners` here for KoP 2.8.0 because `listeners` is marked as deprecated from KoP 2.8.0
kafkaListeners=PLAINTEXT://127.0.0.1:9092
# This config is not required unless you want to expose another address to the Kafka client.
# If it’s not configured, it will be the same with `kafkaListeners` config by default
kafkaAdvertisedListeners=PLAINTEXT://127.0.0.1:9092
kafkaListeners是一个以逗号分隔的侦听器列表以及 Kafka 绑定以进行侦听的主机/IP 和端口。
kafkaAdvertisedListeners是一个以逗号分隔的侦听器列表及其主机/IP 和端口。如下设置偏移量管理,因为 KoP 的偏移量管理取决于 “Broker Entry Metadata”。 KoP 2.8.0 或更高版本需要它。
brokerEntryMetadataInterceptors=org.apache.pulsar.common.intercept.AppendIndexMetadataInterceptor
禁止删除非活动主题。 这不是必需的,但在 KoP 中非常重要。 目前,Pulsar 会删除分区主题的非活动分区,而不会删除分区主题的元数据。 在这种情况下,KoP 无法创建丢失的分区。
brokerDeleteInactiveTopicsEnabled=false
启动 Pulsar
./bin/pulsar-daemon standalone
测试 KoP
使用 Kafka Assistant 连接到 KoP
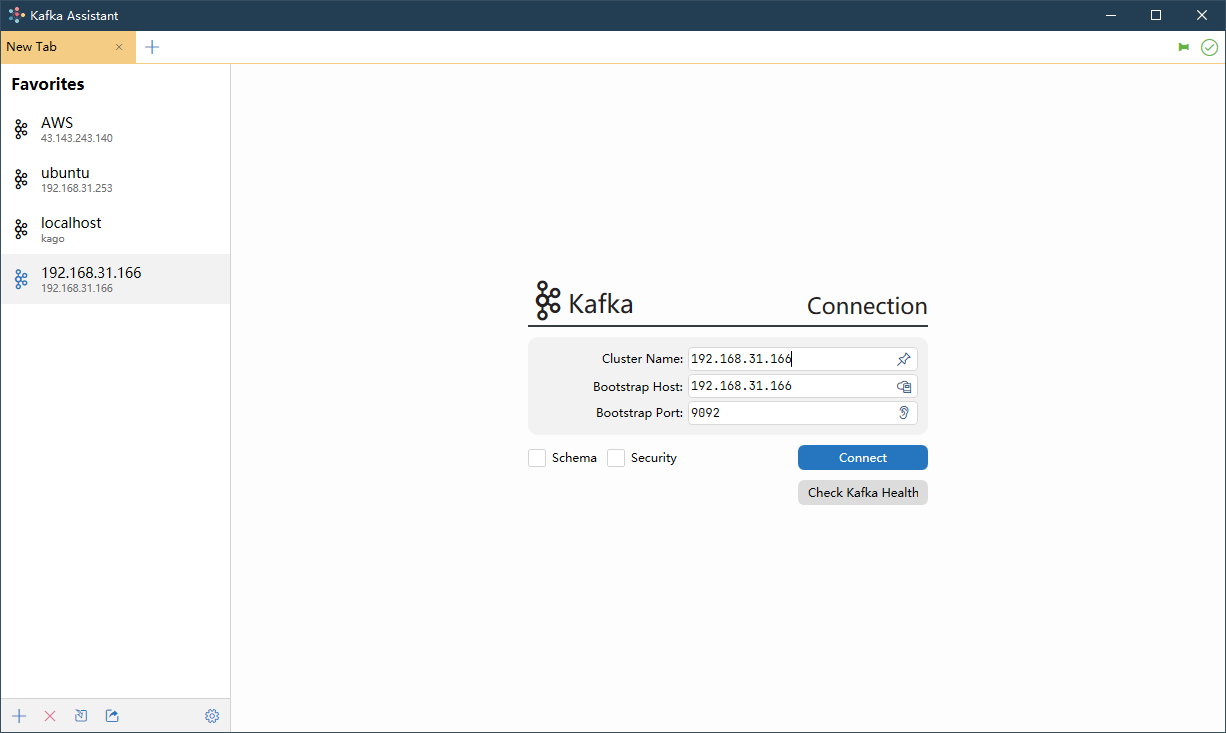
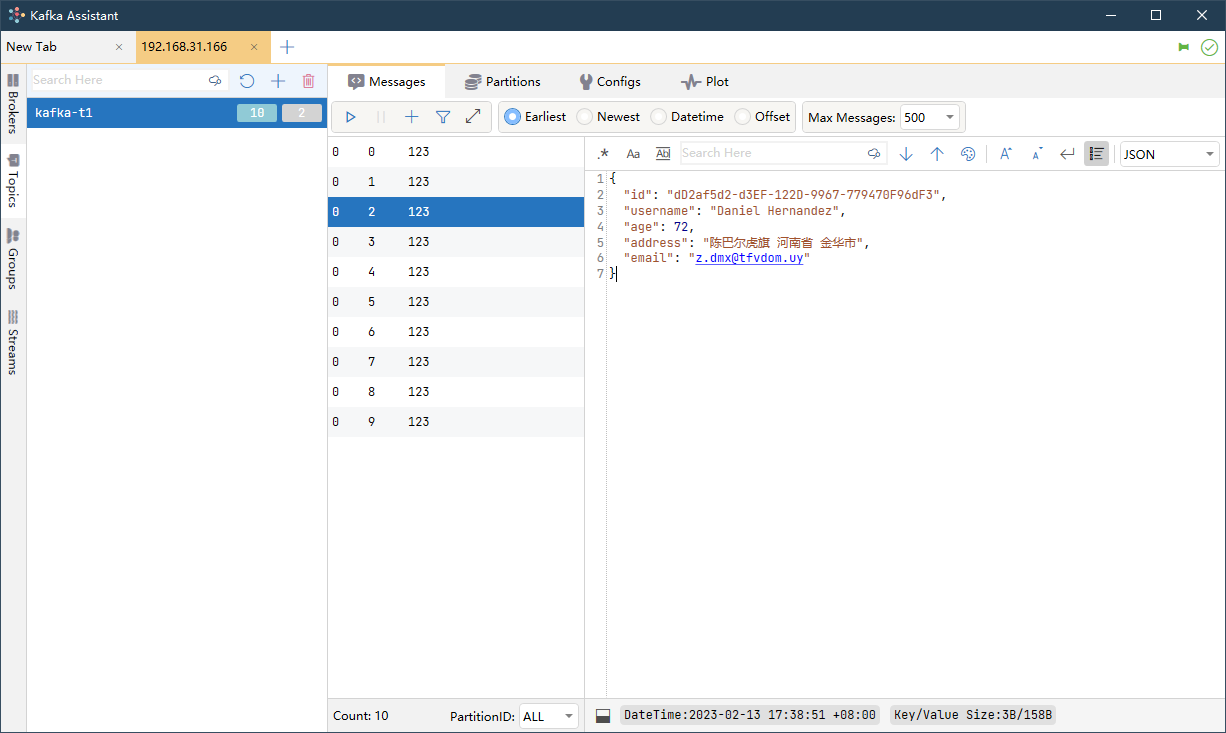
创建主题并发送一些消息
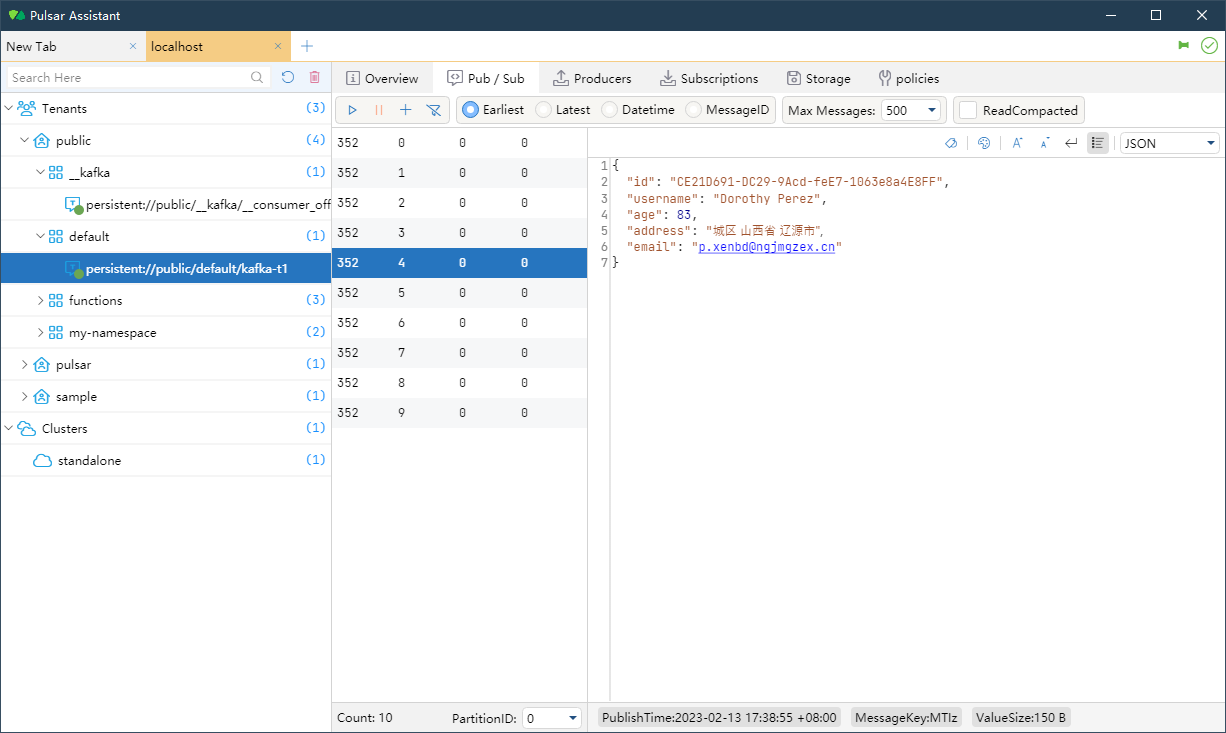
使用 Pulsar Assistant 连接到 Pulsar Broker 并接收消息
通过 KoP 将 Kafka 应用迁移到 Pulsar的更多相关文章
- [bigdata] kafka基本命令 -- 迁移topic partition到指定的broker
版本 0.9.2 创建topic bin/kafka-topics.sh --create --topic topic_name --partition 6 --replication-factor ...
- kafka数据迁移实践
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 作者:mikealzhou 本文重点介绍kafka的两类常见数据迁移方式:1.broker内部不同数据盘之间的分区数据迁移:2.不同broker ...
- Kafka数据迁移
1.概述 Kafka的使用场景非常广泛,一些实时流数据业务场景,均依赖Kafka来做数据分流.而在分布式应用场景中,数据迁移是一个比较常见的问题.关于Kafka集群数据如何迁移,今天笔者将为大家详细介 ...
- kafka的迁移干货
随着业务的发展, 服务器所在网段/机群不允许kafka继续保留在那, 需要移动到先机器上. 哎呀上面是废话,总的说就是: 2台老kafka不要了,数据要迁移到新的2台kafka上面.要求数据不丢失 通 ...
- Kafka数据迁移MaxCompute最佳实践
摘要: 本文向您详细介绍如何使用DataWorks数据同步功能,将Kafka集群上的数据迁移到阿里云MaxCompute大数据计算服务. 前提条件 搭建Kafka集群 进行数据迁移前,您需要保证自己的 ...
- kafka partiton迁移方法与原理
在kafka中增加新的节点后,数据是不会自动迁移到新的节点上的,需要我们手动将数据迁移(或者成为打散)到新的节点上 1 迁移方法 kafka为我们提供了用于数据迁移的脚本.我们可以用这些脚本完成数据的 ...
- Apache 顶级项目 Apache Pulsar 成长回顾
关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ...
- 分布式消息流平台:不要只想着Kafka,还有Pulsar
摘要:Pulsar作为一个云原生的分布式消息流平台,越来越频繁地出现在人们的视野中,大有替代Kafka江湖地位的趋势. 本文分享自华为云社区<MRS Pulsar:下一代分布式消息流平台全新发布 ...
- Kafka Topic动态迁移 (源代码解析)
总结下自己在尝试Kafka分区迁移过程中对这部分知识的理解,请路过高手指正. 关于Kafka数据迁移的具体步骤指导,请参考如下链接:http://www.cnblogs.com/dycg/p/3922 ...
- Apache 软件基金会顶级项目 Pulsar 达成新里程碑:全球贡献者超 300 位!
各位 Pulsar 社区小伙伴们: 今天我们高兴地宣布Pulsar 达成新里程碑,全球贡献者超 300 位! 距离 Pulsar 实现 200 位贡献者里程碑,仅仅间隔 8 个月! 作为 Apache ...
随机推荐
- 记录--Vue的缓存组件 | 详解KeepAlive
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 一. keep-alive 的作用 二. keep-alive 的原理 三. keep-alive 的应用 四. keep-aliv ...
- ArcMap的mxd文件没有数据、显示感叹号怎么办?
本文介绍在ArcMap软件中,导入.mxd地图文档文件后图层出现感叹号.地图显示空白等情况的解决办法. 在ArcMap软件使用过程中,我们经常会需要将包含有多个图层的.mxd地图文档文件导入软 ...
- Python 汇总列数据到行
Python汇总Excel列数据到行(方法一) import pandas as pd # 读取Excel文件 df = pd.read_excel('C:\\Users\\liuchunlin2\\ ...
- nginx location块
location块在server块中使用,它的作用是根据客户端请求URL去定位不同的应用. 匹配格式 作用 location = /uri = 表示精确匹配,只有完全匹配上才能生效 location ...
- KingbaseES V8R6 空闲事务会话超时自动终止机制
背景 如果会话在事务中停留的时间过长,则允许自动终止空闲会话.可以由配置参数idle_in_transaction_session_timeout 事务处于空闲状态的时长,它有助于防止被遗忘的交易事务 ...
- Log4Net使用示例
<?xml version="1.0" encoding="utf-8" ?> <configuration> <configSe ...
- #线段树,矩阵乘法#洛谷 7453 [THUSCH2017] 大魔法师
题目 分析 首先考虑如果修改操作都是单点修改怎么做, 以第一种修改为例那么就是 \[\left[\begin{matrix}A\\B\\C\\1\end{matrix}\right] \times \ ...
- 深入了解图片Base64编码
title: 深入了解图片Base64编码 date: 2024/4/8 10:03:22 updated: 2024/4/8 10:03:22 tags: Base64编码 图片转换 HTTP请求 ...
- k8s之configmap应用
一.创建configmap 1.基于命令创建configmap root@k8s-master01:~# kubectl create configmap demoapp-cfg --from-lit ...
- js es6 delete
前言 首先delete 不同于nodejs delete,看下有什么不同. 正文 var test=5; delete test; console.log(test); 结果是test没有受到任何影响 ...