如何使用 Megatron-LM 训练语言模型
在 PyTorch 中训练大语言模型不仅仅是写一个训练循环这么简单。我们通常需要将模型分布在多个设备上,并使用许多优化技术以实现稳定高效的训练。Hugging Face Accelerate 的创建是为了支持跨 GPU 和 TPU 的分布式训练,并使其能够非常容易的集成到训练代码中。 Transformers 还支持使用 Trainer API 来训练,其在 PyTorch 中提供功能完整的训练接口,甚至不需要自己编写训练的代码。
Megatron-LM 是研究人员用于预训练大型 Transformer 模型的另一个流行工具,它是 NVIDIA 应用深度学习研究团队开发的一个强大框架。与 accelerate 和 Trainer 不同,Megatron-LM 使用起来并不简单,对于初学者来说可能难以上手。但它针对 GPU 上的训练进行了高度优化。在这篇文章中,你将学习如何使用 Megatron-LM 框架在 NVIDIA GPU 上训练语言模型,并将其与 transformers 结合。
我们将分解在此框架中训练 GPT2 模型的不同步骤,包括:
- 环境设置
- 数据预处理
- 训练
- 将模型转化为 Transformers
为什么选择 Megatron-LM?
在进入训练细节的讲解之前,让我们首先了解是什么让这个框架比其他框架更高效。本节的灵感来自这篇关于使用 Megatron-DeepSpeed 进行 BLOOM 训练的精彩 博客,请参阅该博客以获取更多详细信息,因为该博客旨在对 Megatron-LM 进行详细的介绍。
数据加载
Megatron-LM 带有一个高效的 DataLoader,其中数据在训练前被 tokenize 和 shuffle。它还将数据拆分为带有索引的编号序列,并将索引存储,因此 tokenize 只需要计算一次。为了构建索引,首先根据训练参数计算每个 epoch 的数量,并创建一个排序,然后对数据进行 shuffle 操作。这与大多数情况不同,我们通常迭代整个数据集直到其用尽,然后重复第二个 epoch 。这平滑了学习曲线并节省了训练时间。
融合 CUDA 内核
当一个计算在 GPU 上运行时,必要的数据会从内存中取出并加载到 GPU 上,然后计算结果被保存回内存。简单来说,融合内核的思想是: 将通常由 PyTorch 单独执行的类似操作组合成一个单独的硬件操作。因此可以将多个离散计算合并为一个,从而减少在多个离散计算中的内存移动次数。下图说明了内核融合的思想。它的灵感来自这篇 论文,该论文详细讨论了这个概念。
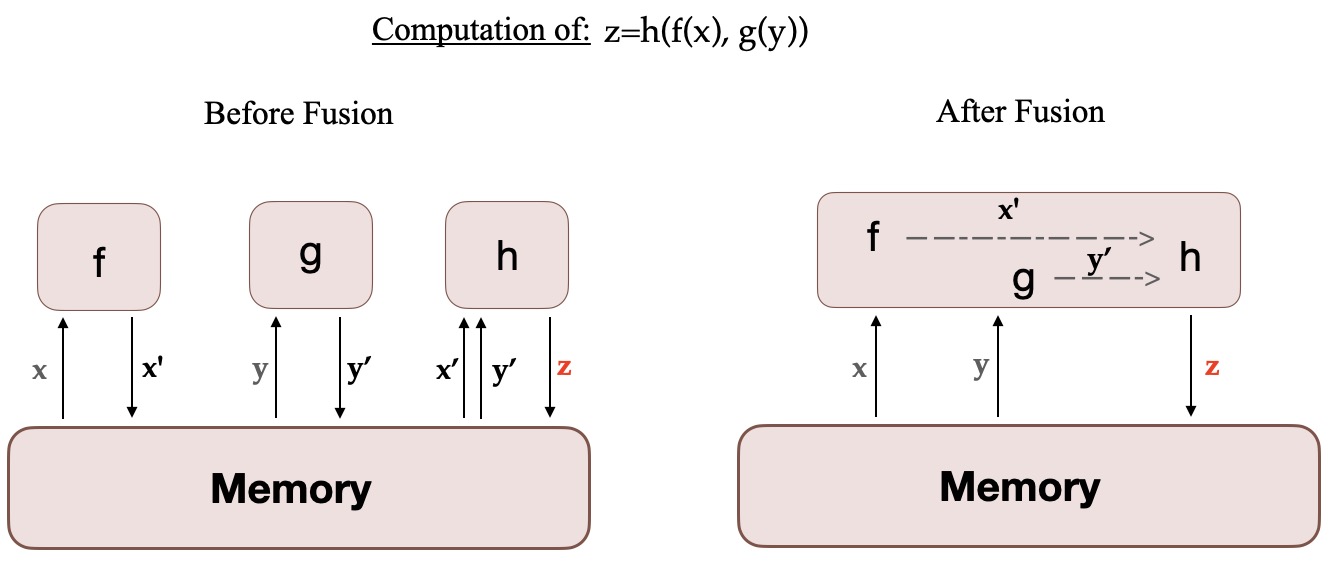
当 f、g 和 h 融合在一个内核中时,f 和 g 的中间结果 x' 和 y' 存储在 GPU 寄存器中并立即被 h 使用。但是如果不融合,x' 和 y' 就需要复制到内存中,然后由 h 加载。因此,融合 CUDA 内核显着加快了计算速度。此外,Megatron-LM 还使用 Apex 的 AdamW 融合实现,它比 PyTorch 实现更快。
虽然我们可以在 transformers 中自定义 Megatron-LM 中的 DataLoader 和 Apex 的融合优化器,但自定义融合 CUDA 内核对新手来说太不友好了。
现在你已经熟悉了该框架及其优势,让我们进入训练细节吧!
如何使用 Megatron-LM 框架训练?
环境设置
设置环境的最简单方法是从 NGC 拉取附带所有所需环境的 NVIDIA PyTorch 容器。有关详细信息,请参阅 文档。如果你不想使用此容器,则需要安装最新的 pytorch、cuda、nccl 和 NVIDIA APEX 版本和 nltk 库。
在安装完 Docker 之后,你可以使用以下命令运行容器 (xx.xx 表示你的 Docker 版本),然后在其中克隆 Megatron-LM 库:
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:xx.xx-py3
git clone https://github.com/NVIDIA/Megatron-LM
你还需要在容器的 Megatron-LM 文件夹中添加分词器的词汇文件 vocab.json 和合并表 merges.txt。这些文件可以在带有权重的模型仓库中找到,请参阅 GPT2 库。你还可以使用 transformers 训练自己的分词器。你可以查看 CodeParrot 项目 以获取实际示例。现在,如果你想从容器外部复制这些数据,你可以使用以下命令:
sudo docker cp vocab.json CONTAINER_ID:/workspace/Megatron-LM
sudo docker cp merges.txt CONTAINER_ID:/workspace/Megatron-LM
数据预处理
在本教程的其余部分,我们将使用 CodeParrot 模型和数据作为示例。
我们需要对预训练数据进行预处理。首先,你需要将其转换为 json 格式,一个 json 的一行包含一个文本样本。如果你正在使用 Datasets,这里有一个关于如何做到这一点的例子 (请在 Megatron-LM 文件夹中进行这些操作):
from datasets import load_dataset
train_data = load_dataset('codeparrot/codeparrot-clean-train', split='train')
train_data.to_json("codeparrot_data.json", lines=True)
然后使用以下命令将数据 tokenize、shuffle 并处理成二进制格式以进行训练:
#if nltk isn't installed
pip install nltk
python tools/preprocess_data.py \
--input codeparrot_data.json \
--output-prefix codeparrot \
--vocab vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file merges.txt \
--json-keys content \
--workers 32 \
--chunk-size 25 \
--append-eod
workers 和 chunk_size 选项指的是预处理中使用的线程数量和分配给每个线程的数据块大小。dataset-impl 指的是索引数据集的实现方式,包括 ['lazy', 'cached', 'mmap']。这将输出 codeparrot_content_document.idx 和 codeparrot_content_document.bin 两个文件用于训练。
训练
你可以使用如下所示配置模型架构和训练参数,或将其放入你将运行的 bash 脚本中。该命令在 8 个 GPU 上参数为 110M 的 CodeParrot 模型进行预训练。请注意,数据默认按 969:30:1 的比例划分为训练/验证/测试集。
GPUS_PER_NODE=8
MASTER_ADDR=localhost
MASTER_PORT=6001
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
CHECKPOINT_PATH=/workspace/Megatron-LM/experiments/codeparrot-small
VOCAB_FILE=vocab.json
MERGE_FILE=merges.txt
DATA_PATH=codeparrot_content_document
GPT_ARGS="--num-layers 12
--hidden-size 768
--num-attention-heads 12
--seq-length 1024
--max-position-embeddings 1024
--micro-batch-size 12
--global-batch-size 192
--lr 0.0005
--train-iters 150000
--lr-decay-iters 150000
--lr-decay-style cosine
--lr-warmup-iters 2000
--weight-decay .1
--adam-beta2 .999
--fp16
--log-interval 10
--save-interval 2000
--eval-interval 200
--eval-iters 10
"
TENSORBOARD_ARGS="--tensorboard-dir experiments/tensorboard"
python3 -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
$GPT_ARGS \
--vocab-file $VOCAB_FILE \
--merge-file $MERGE_FILE \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
$TENSORBOARD_ARGS
使用以上设置,训练大约需要 12 个小时。
该设置使用数据并行,但也可以对无法放在单个 GPU 的超大模型使用模型并行。第一种选择是设置张量并行,它将模型中的张量拆分到多个 GPU 上并行运算,你需要将 tensor-model-parallel-size 参数更改为所需的 GPU 数量。第二种选择是流水线并行,它将模型按层分成大小相等的几块。参数 pipeline-model-parallel-size 表示将模型分成的块数。有关详细信息,请参阅此 博客
将模型转换为 Transformers
训练结束后,我们希望使用 transformers 库对该模型进行评估或将其部署到生产环境中。你可以按照 教程 将其转换为 transformers 模型。例如,在训练完成后,你可以复制第 150k 次迭代的权重,并使用以下命令将文件 model_optim_rng.pt 转换为 transformers 支持的 pytorch_model.bin 文件:
# to execute outside the container:
mkdir -p nvidia/megatron-codeparrot-small
# copy the weights from the container
sudo docker cp CONTAINER_ID:/workspace/Megatron-LM/experiments/codeparrot-small/iter_0150000/mp_rank_00/model_optim_rng.pt nvidia/megatron-codeparrot-small
git clone https://github.com/huggingface/transformers.git
git clone https://github.com/NVIDIA/Megatron-LM.git
export PYTHONPATH=Megatron-LM
python transformers/src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py nvidia/megatron-codeparrot-small/model_optim_rng.pt
请注意,如果你打算使用原始的分词器,你将需要在转换后将生成的词汇文件和合并表替换为我们之前介绍的原始文件。
不要忘记将你的模型推送到 hub 并与社区分享,只需三行代码 :
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("nvidia/megatron-codeparrot-small")
# this creates a repository under your username with the model name codeparrot-small
model.push_to_hub("codeparrot-small")
你还可以轻松地使用它来生成文本:
from transformers import pipeline
pipe = pipeline("text-generation", model="your_username/codeparrot-small")
outputs = pipe("def hello_world():")
print(outputs[0]["generated_text"])
def hello_world():
print("Hello World!")
Transformers 还可以有效地处理大模型推理。如果你训练了一个非常大的模型 (例如训练时使用了模型并行),你可以通过以下命令轻松地进行推理:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("your_username/codeparrot-large", device_map="auto")
这将在内部调用 accelerate 库 自动在你可用的设备 (GPU、CPU RAM) 之间分配模型权重。
免责声明: 我们已经证明任何人都可以使用 Megatron-LM 来训练语言模型。问题是我们需要考虑什么时候使用它。由于额外的预处理和转换步骤,这个框架显然增加了一些时间开销。因此,重要的是你要考虑哪个框架更适合你的需求和模型大小。我们建议将其用于预训练模型或微调,但可能不适用于中型模型的微调。 APITrainer 和 accelerate 库对于模型训练同样也非常方便,并且它们与设备无关,为用户提供了极大的灵活性。
恭喜 现在你学会了如何在 Megatron-LM 框架中训练 GPT2 模型并使其支持 transformers!
原文链接: https://hf.co/blog/megatron-training
作者: Loubna Ben Allal
译者: gxy-gxy
审校/排版: zhongdongy (阿东)
如何使用 Megatron-LM 训练语言模型的更多相关文章
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- NLP中的预训练语言模型(五)—— ELECTRA
这是一篇还在双盲审的论文,不过看了之后感觉作者真的是很有创新能力,ELECTRA可以看作是开辟了一条新的预训练的道路,模型不但提高了计算效率,加快模型的收敛速度,而且在参数很小也表现的非常好. 论文: ...
- NLP中的预训练语言模型(三)—— XL-Net和Transformer-XL
本篇带来XL-Net和它的基础结构Transformer-XL.在讲解XL-Net之前需要先了解Transformer-XL,Transformer-XL不属于预训练模型范畴,而是Transforme ...
- 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
NLP论文解读 |杨健 论文标题: ERNIE:Enhanced Language Representation with Informative Entities 收录会议:ACL 论文链接: ht ...
- 知识增强的预训练语言模型系列之KEPLER:如何针对上下文和知识图谱联合训练
原创作者 | 杨健 论文标题: KEPLER: A unified model for knowledge embedding and pre-trained language representat ...
- 知识增广的预训练语言模型K-BERT:将知识图谱作为训练语料
原创作者 | 杨健 论文标题: K-BERT: Enabling Language Representation with Knowledge Graph 收录会议: AAAI 论文链接: https ...
- NLP中的预训练语言模型(四)—— 小型化bert(DistillBert, ALBERT, TINYBERT)
bert之类的预训练模型在NLP各项任务上取得的效果是显著的,但是因为bert的模型参数多,推断速度慢等原因,导致bert在工业界上的应用很难普及,针对预训练模型做模型压缩是促进其在工业界应用的关键, ...
- NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa
本篇带来Facebook的提出的两个预训练模型——SpanBERT和RoBERTa. 一,SpanBERT 论文:SpanBERT: Improving Pre-training by Represe ...
随机推荐
- call、apply 及 bind 函数
首先从以下几点来考虑如何实现这几个函数 不传入第一个参数,那么上下文默认为 window: 改变了 this 指向,让新的对象可以执行该函数,并能接受参数. 实现call 首先 context 为可选 ...
- P/Invoke之C#调用动态链接库DLL
本编所涉及到的工具以及框架: 1.Visual Studio 2022 2..net 6.0 P/Invok是什么? P/Invoke全称为Platform Invoke(平台调用),其实际上就是一种 ...
- 几个对js帮助挺多的大佬写的博客
深入理解javascript原型和闭包(完结) JavaScript系列文章 同步异步回调DEMO知乎大佬的this与new解释 宏任务与微任务解析 js闭包 Vue项目中技巧ts学习 ES6基础入门 ...
- react中登录注册 使用验证码验证
后端接口 var express = require('express'); var router = express.Router(); var User = require('./../sql/c ...
- python进程之进程池、线程池与异步回调机制
进程线程不可以无限制的创建,因为有硬件的限制.为了避免资源被程序消耗过度,可以使用进程池或线程池的技术. 池 降低程序的执行效率,但是保证了计算机硬件的安全 进程池 提前创建好固定数量 ...
- ServiceAccounts 及 Secrets 重大变化
关于 ServiceAccounts 及其 Secrets 的重大变化 kubernetes v1.24.0 更新之后进行创建 ServiceAccount 不会自动生成 Secret 需要对其手动创 ...
- MySQL数据库与Nacos搭建监控服务
目录 Nacos部署 项目环境 快速开始 nacos2.2.0版本配置说明 MySQL部署 安装方式 Linux平台(CentOS-Stream-9)部署MySQL 调试防火墙管理工具 MySQL用户 ...
- java练习题:用递归反转单链表
问题:用递归反转单链表. 单链表结构: class ListNode{ int val; ListNode next; ListNode(int value){ this.val=value; }} ...
- .NET敏捷开发框架-RDIFramework.NET V5.1发布(跨平台)
RDIFramework.NET,基于全新.NET Framework与.NET Core的快速信息化系统敏捷开发.整合框架,给用户和开发者最佳的.Net框架部署方案.为企业快速构建跨平台.企业级的应 ...
- PyG 图神经网络依赖环境安装(Anaconda)
1.默认用户在Anaconda的虚拟环境中已安装Pytorch 2.打开anaconda prompt命令窗, activate "你的虚拟环境名称" 3.在激活后的虚拟环境下输入 ...