Llama2开源大模型的新篇章以及在阿里云的实践
Llama一直被誉为AI社区中最强大的开源大模型。然而,由于开源协议的限制,它一直不能被免费用于商业用途。然而,这一切在7月19日发生了改变,当Meta终于发布了大家期待已久的免费商用版本Llama2。Llama2是一个由Meta AI开发的预训练大语言模型,它可以接受任何自然语言文本作为输入,并生成文字形式的输出。Llama2-xb-chat是基于Llama2-xb在对话场景下的优化模型,目前在大多数评测指标上超过了其他开源对话模型,并且与一些热门的闭源模型(如ChatGPT、PaLM)的表现相当。
官方介绍
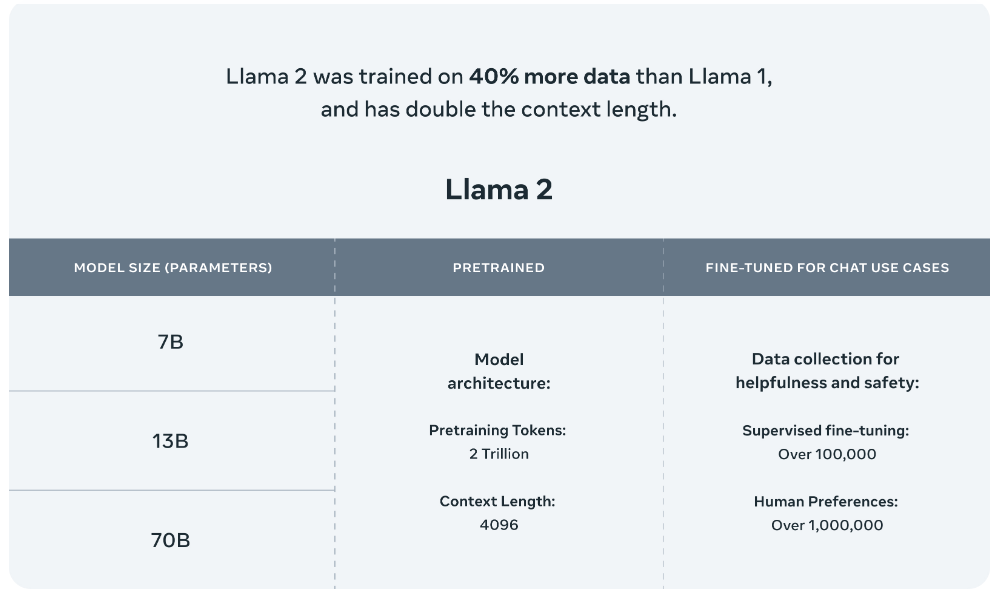
Meta发布的Llama 2模型系列包括70亿、130亿和700亿三种参数版本。此外,他们还训练了一个340亿参数的版本,但并未发布,只在技术报告中提到。据官方介绍,Llama 2与其前身Llama 1相比,训练数据增加了40%,上下文长度也翻了一番,并采用了分组查询注意力机制。具体来说,Llama 2预训练模型是在2万亿的token上训练的,而精调Chat模型则是在100万人类标记数据上训练的。
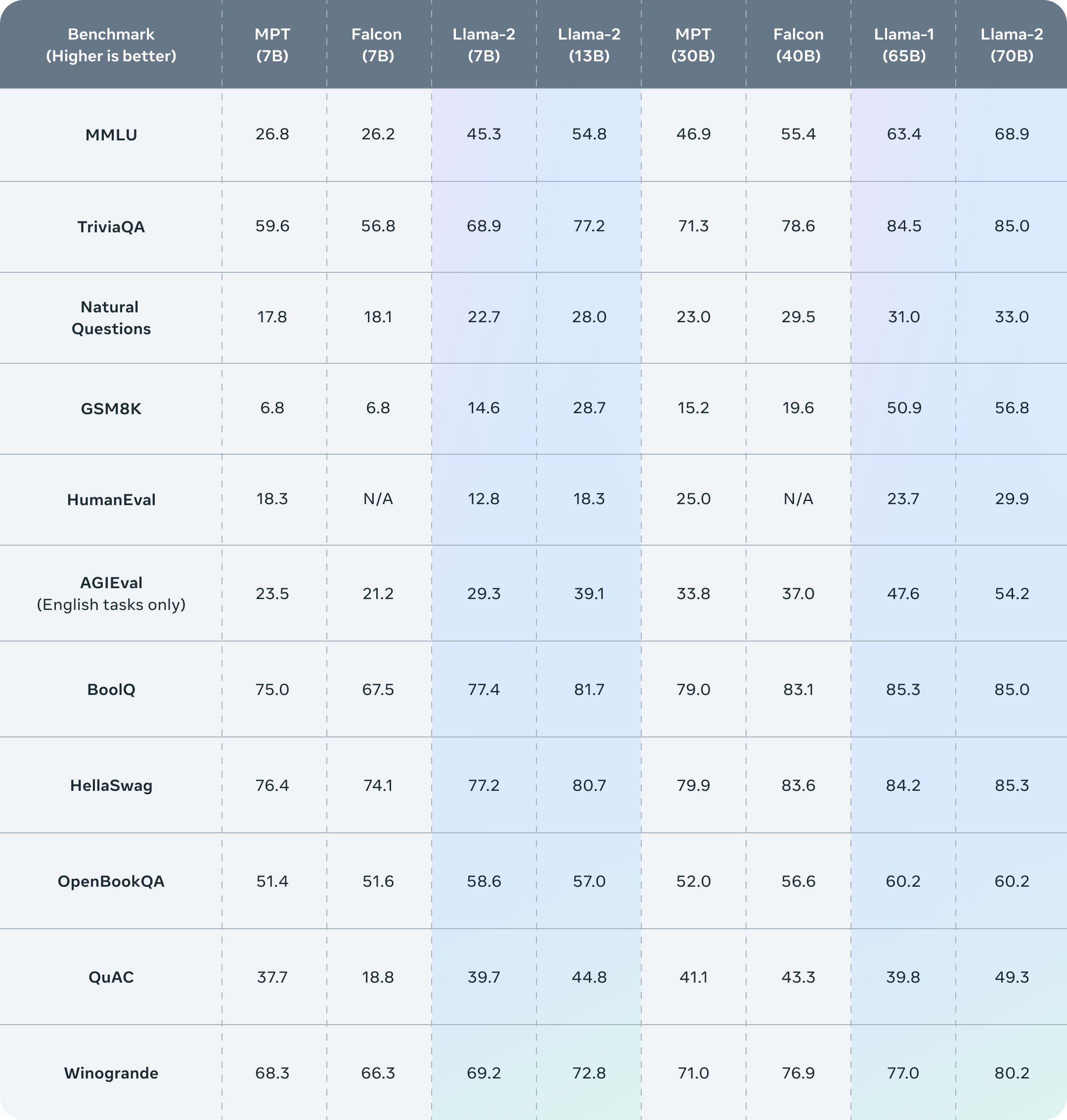
公布的测评结果显示,Llama 2在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
模型部署
Meta在Huggingface上提供了所有模型的下载链接:https://huggingface.co/meta-llama
预训练模型
Llama2预训练模型包含7B、13B和70B三个版本
| 模型名称 | 模型加载名称 | 下载地址 |
|---|---|---|
| Llama2-7B | meta-llama/Llama-2-7b-hf | 模型下载 |
| Llama2-13B | meta-llama/Llama-2-13b-hf | 模型下载 |
| Llama2-70B | meta-llama/Llama-2-70b-hf | 模型下载 |
Chat模型
Llama2-Chat模型基于预训练模型进行了监督微调,具备更强的对话能力
| 模型名称 | 模型加载名称 | 下载地址 |
|---|---|---|
| Llama2-7B-Chat | meta-llama/Llama-2-7b-chat-hf | 模型下载 |
| Llama2-13B-Chat | meta-llama/Llama-2-13b-chat-hf | 模型下载 |
| Llama2-70B-Chat | meta-llama/Llama-2-70b-chat-hf | 模型下载 |
阿里云机器学习平台PAI
机器学习平台PAI(Platform of Artificial Intelligence)面向企业客户及开发者,提供轻量化、高性价比的云原生机器学习,涵盖PAI-DSW交互式建模、PAI-Studio拖拽式可视化建模、PAI-DLC分布式训练到PAI-EAS模型在线部署的全流程。
PAI平台部署

今天PAI平台也对Llama2-7b做了支持,提供了相关的镜像可以直接部署。模型部署后,用户可以在服务详情页面通过“查看Web应用”按钮来在网页端直接和模型推理交互。让我们来体验一下吧!
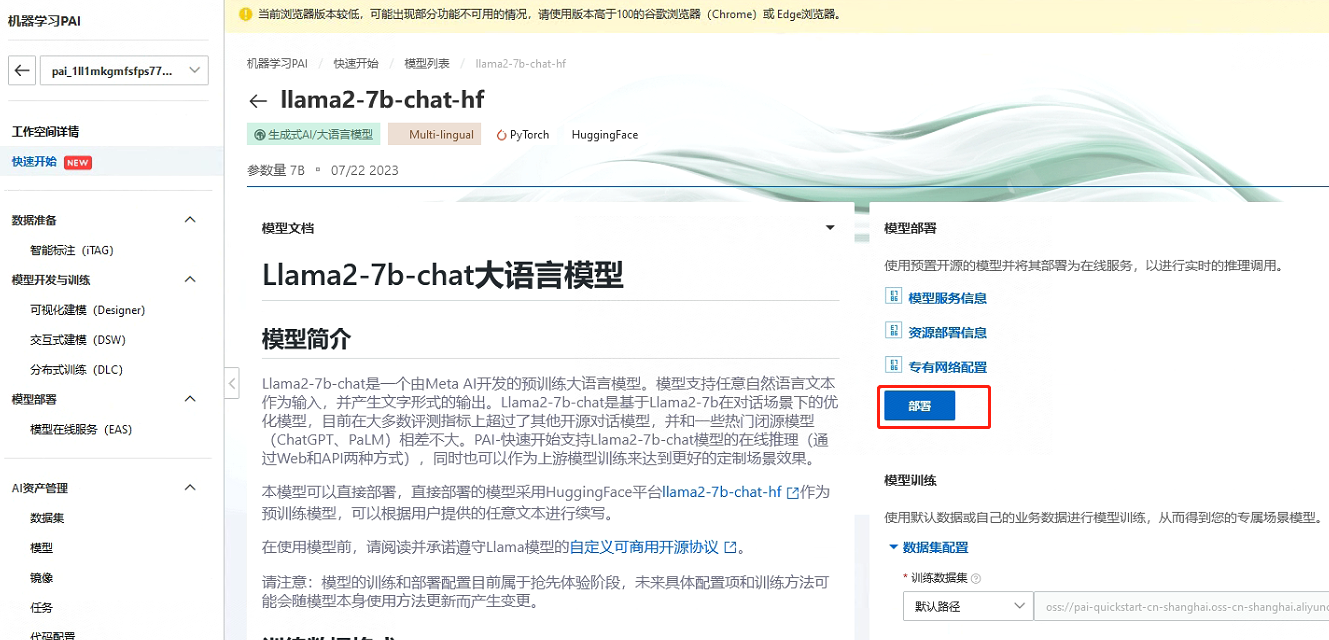
部署完成后:
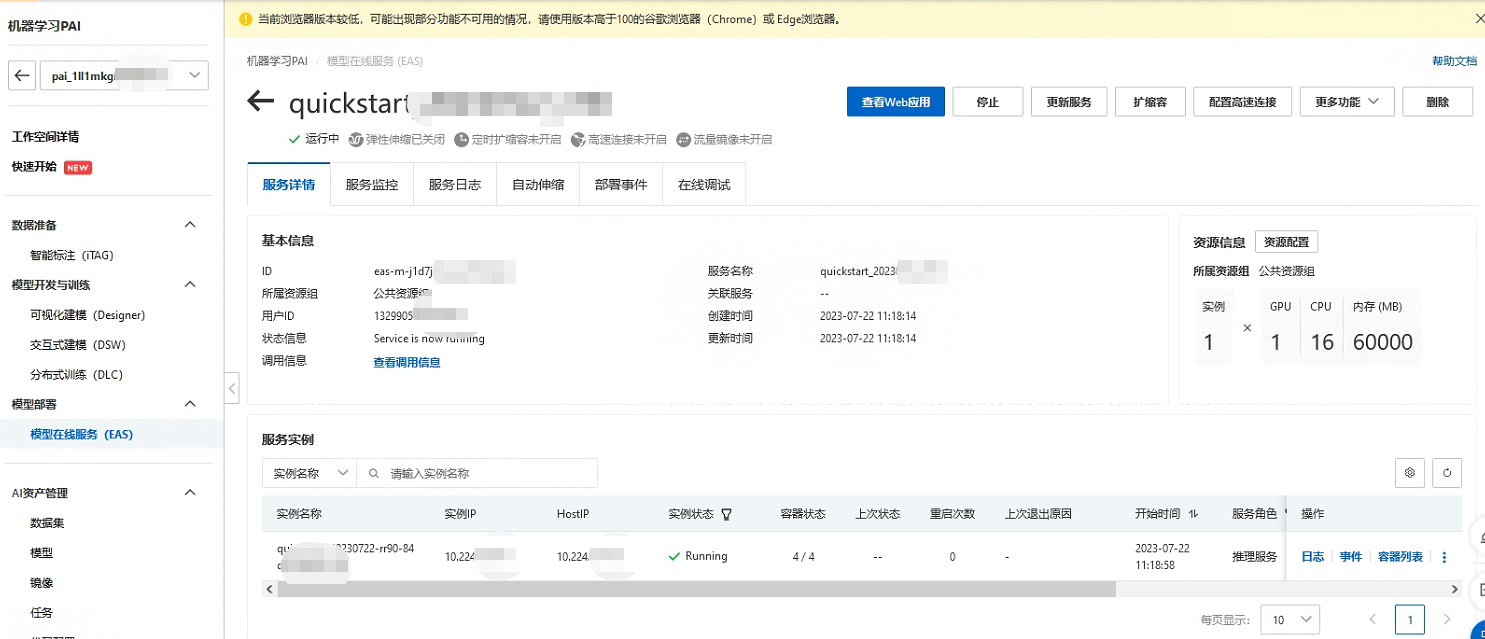
进入Web页面来测试一下:
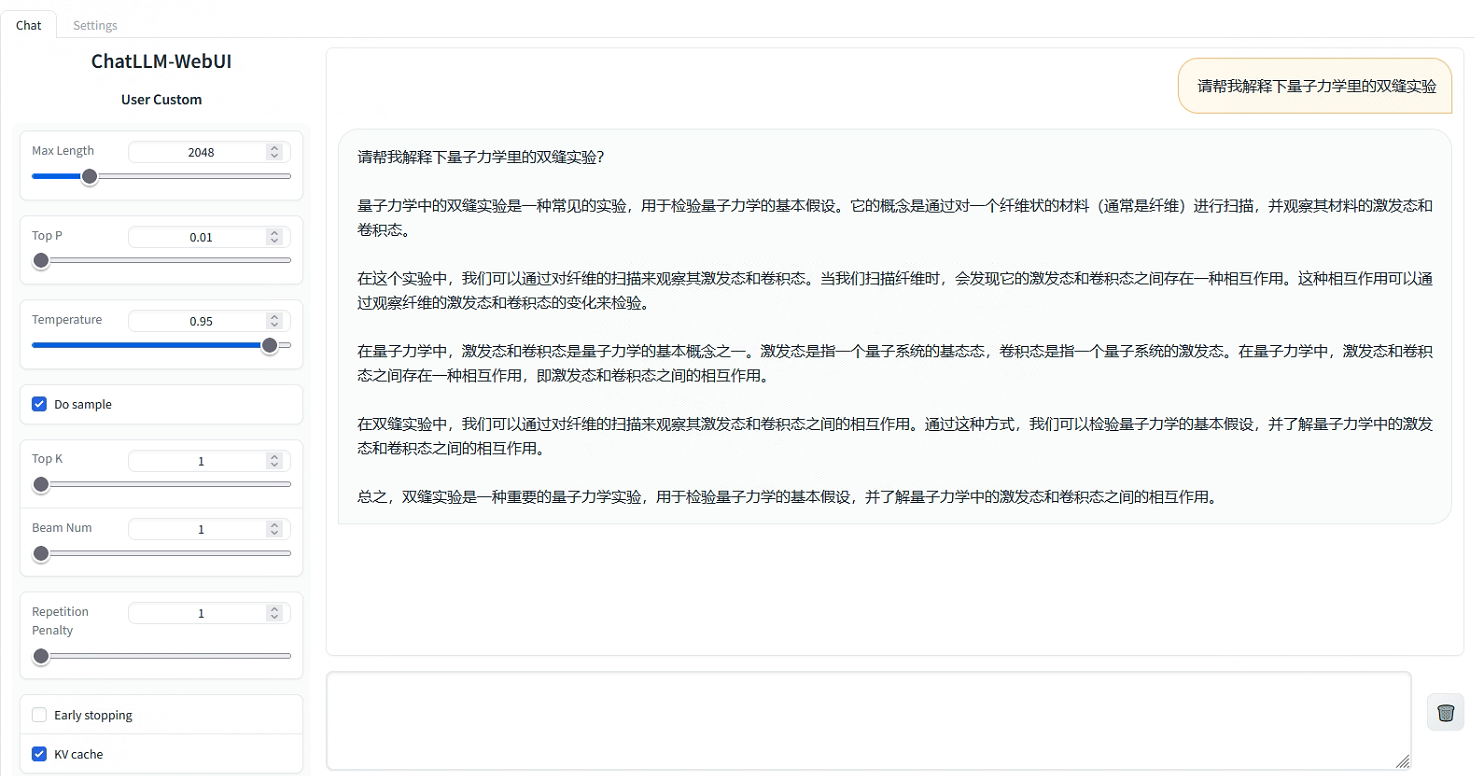
此外,也支持了通过API形式直接推理,但需要前往EAS服务并将服务运行命令更新为python api/api_server.py --port=8000 --model-path=<先前填入的model-path>。服务请求Body为输入text/plain格式文本或application/json格式,返回数据为text/html格式。以下为发送请求的格式示例:
{"input_ids": "List the largest islands which begin with letter 's'.","temperature": 0.8,"max_length": 5120,"top_p": 0.9}
API详情
LLAMA2模型API调用需"申请体验"并通过后才可使用,否则API调用将返回错误状态码。以下示例展示了调用LLAMA2模型对一个用户指令进行响应的代码。
Python
# For prerequisites running the following sample, visit https://help.aliyun.com/document_detail/611472.html
from http import HTTPStatus
from dashscope import Generation
def simple_sample():
# 模型可以为模型列表中任一模型
response = Generation.call(model='llama2-7b-chat-v2',
prompt='Hey, are you conscious? Can you talk to me?')
if response.status_code == HTTPStatus.OK:
print('Result is: %s' % response.output)
else:
print('Failed request_id: %s, status_code: %s, code: %s, message:%s' %
(response.request_id, response.status_code, response.code,
response.message))
if __name__ == '__main__':
simple_sample()
响应示例
{"text": "Hey, are you conscious? Can you talk to me?\n[/Inst: Hey, I'm not sure if I'm conscious or not. I can't really feel anything or think very clearly. Can you tell me"}
HTTP调用接口
curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation' \
--header 'Authorization: Bearer <your-dashscope-api-key>' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama2-7b-v2",
"input":{
"prompt":"Hey, are you conscious? Can you talk to me?"
}
}'
响应示例
{
"output":{
"text":"Hey, are you conscious? Can you talk to me?\nLeaders need to be conscious of what’s going on around them, and not just what’s happening within their own heads.\nThis means listening to your team."
},
"request_id":"fbd7e41a-363c-938a-81be-8ae0f9fbdb3d"
}
随着时间的推移,基于Llama2开源模型的应用预计将在国内如雨后春笋般涌现。这种趋势反映了从依赖外部技术向自主研发的转变,这不仅能满足我们特定的需求和目标,也能避免依赖外部技术的风险。因此,我们更期待看到优秀的、独立的、自主的大模型的出现,这将推动我们的AI技术的发展和进步。
更深入的内容后续学习后再总结吧
Llama2开源大模型的新篇章以及在阿里云的实践的更多相关文章
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- 【¥200代金券、iPad等您来拿】 阿里云9大产品免费公测#10月9日-11月6日#
#10.09-11.06#200元代金券.iPad大奖, 9大产品评测活动! 亲爱的阿里云小伙伴们: 云产品的多样性(更多的云产品)也是让用户深度使用云计算的关键.今年阿里云产品线越来越丰富,小云搜罗 ...
- 为更强大而生的开源关系型数据库来了!阿里云RDS for MySQL 8.0 正式上线!
2019年5月29日15时,阿里云RDS for MySQL 8.0正式上线,使得阿里云成为紧跟社区步伐,发布MySQL最新版本的云厂商.RDS for MySQL 8.0 产品是阿里云推出的 MyS ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
- 开源大数据技术专场(下午):Databircks、Intel、阿里、梨视频的技术实践
摘要: 本论坛第一次聚集阿里Hadoop.Spark.Hbase.Jtorm各领域的技术专家,讲述Hadoop生态的过去现在未来及阿里在Hadoop大生态领域的实践与探索. 开源大数据技术专场下午场在 ...
- 开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践
16日上午9点,2016云栖大会“开源大数据技术专场” (全天)在阿里云技术专家封神的主持下开启.通过封神了解到,在上午的专场中,阿里云高级技术专家无谓.阿里云技术专家封神.阿里巴巴中间件技术部高级技 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
随机推荐
- 3.2 构造器、this、包机制、访问修饰符、封装
构造器 构造器:在实例化的一个对象的时候会给对象赋予初始值,因此我们可以通过修改构造器,来改变对象的初始值,构造器是完成对象的初始化,并不是创建对象 我们也可以创建多个构造器实现不同的初始化,即构造器 ...
- VMware虚拟机---Ubuntu无法连接网络该怎么解决?
在学习使用Linux系统时,由于多数同学们的PC上多是Windows系统,故会选择使用VMware创建一个虚拟机来安装Linux系统进行学习. 安装完成之后,在使用时总是会遇到各种各样的问题.本片随笔 ...
- scrapy框架简介
一.安装scrapy环境 -mac或linux:pip install scrapy -windows: 1.pip install wheel 2.pip install twinsted 3.pi ...
- elSelect点击空白处无法收起下拉框(失去焦点并隐藏)
学习记录,为了以后有同样的问题,省得再百度了,方便自己也方便你们element 中多选的select 有个问题,就是点击空白或者关闭弹窗,下拉还会一直展示出来百度了好一会,觉得下面两位大佬说的最合理, ...
- SpringBoot自定义注解+AOP+redis实现防接口幂等性重复提交,从概念到实战
本文为千锋教育技术团独家创作,更多技术类知识干货,点个关注持续追更~ 接口幂等性是Web开发中非常重要的一个概念,它可以保证多次调用同一个接口不会对结果产生影响.如果你想了解更多关于接口幂等性的知识, ...
- 文心一言 VS chatgpt (8)-- 算法导论2.3 5~6题
五.回顾查找问题(参见练习 2.1-3),注意到,如果序列 A 已排好序,就可以将该序列的中点与v进行比较.根据比较的结果,原序列中有一半就可以不用再做进一步的考虑了.二分查找算法重复这个过程,每次都 ...
- 2022-09-30:以下go语言代码输出什么?A: true true false true false; B: true false false true false; C: true true
2022-09-30:以下go语言代码输出什么?A: true true false true false: B: true false false true false: C: true true ...
- Singleton 单例模式简介与 C# 示例【创建型】【设计模式来了】
〇.简介 1.什么是单例模式? 一句话解释: 单一的类,只能自己来创建唯一的一个对象. 单例模式(Singleton Pattern)是日常开发中最简单的设计模式之一.这种类型的设计模式属于创建型 ...
- 智慧饮水系统_Android客户端
智慧饮水系统(又名:水牛 APP) 1.介绍 该项目基于 Rfid-RC522.ESP-32 进行下位机开发,硬件模块 Rfid-RC522 主要读取用户的卡号,ESP32 单片机通过 WiFi 模块 ...
- VS code 的安装
VS code 的安装 Win10环境配置(一)--C\C++篇 Win10环境配置(二) --Java篇 安装前先 ,完成环境的配置 1.工具准备 官网下载:Visual Studio Code 2 ...