(续) MindSpore 如何实现一个线性回归 —— Demo示例
前文:
https://www.cnblogs.com/devilmaycry812839668/p/14975860.html
前文中我们使用自己编写的损失函数和单步梯度求导来实现算法,这里是作为扩展,我们这里使用系统提供的损失函数和优化器,代码如下:
import mindspore
import numpy as np #引入numpy科学计算库
import matplotlib.pyplot as plt #引入绘图库
np.random.seed(123) #随机数生成种子 import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor
from mindspore import ParameterTuple, Parameter
from mindspore import dtype as mstype
from mindspore import Model
import mindspore.dataset as ds
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig
from mindspore.train.callback import LossMonitor # 数据集
class DatasetGenerator:
def __init__(self):
self.input_data = 2*np.random.rand(500, 1).astype(np.float32)
self.output_data = 5+3*self.input_data+np.random.randn(500, 1).astype(np.float32) def __getitem__(self, index):
return self.input_data[index], self.output_data[index] def __len__(self):
return len(self.input_data) def create_dataset(batch_size=500):
dataset_generator = DatasetGenerator()
dataset = ds.GeneratorDataset(dataset_generator, ["input", "output"], shuffle=False) #buffer_size = 10000
#dataset = dataset.shuffle(buffer_size=buffer_size)
dataset = dataset.batch(batch_size, drop_remainder=True)
#dataset = dataset.repeat(1)
return dataset class Net(nn.Cell):
def __init__(self, input_dims, output_dims):
super(Net, self).__init__()
self.matmul = ops.MatMul() self.weight_1 = Parameter(Tensor(np.random.randn(input_dims, 128), dtype=mstype.float32), name='weight_1')
self.bias_1 = Parameter(Tensor(np.zeros(128), dtype=mstype.float32), name='bias_1')
self.weight_2 = Parameter(Tensor(np.random.randn(128, 64), dtype=mstype.float32), name='weight_2')
self.bias_2 = Parameter(Tensor(np.zeros(64), dtype=mstype.float32), name='bias_2')
self.weight_3 = Parameter(Tensor(np.random.randn(64, output_dims), dtype=mstype.float32), name='weight_3')
self.bias_3 = Parameter(Tensor(np.zeros(output_dims), dtype=mstype.float32), name='bias_3') def construct(self, x):
x1 = self.matmul(x, self.weight_1)+self.bias_1
x2 = self.matmul(x1, self.weight_2)+self.bias_2
x3 = self.matmul(x2, self.weight_3)+self.bias_3
return x3 def main():
epochs = 10000
dataset = create_dataset()
net = Net(1, 1)
# loss function
loss = nn.MSELoss()
# optimizer
optim = nn.SGD(params=net.trainable_params(), learning_rate=0.000001)
model = Model(net, loss, optim, metrics={'loss': nn.Loss()}) config_ck = CheckpointConfig(save_checkpoint_steps=10000, keep_checkpoint_max=10)
ck_point = ModelCheckpoint(prefix="checkpoint_mlp", config=config_ck)
model.train(epochs, dataset, callbacks=[ck_point, LossMonitor(1000)], dataset_sink_mode=False) np.random.seed(123) # 随机数生成种子
dataset = create_dataset()
data = next(dataset.create_dict_iterator())
x = data['input']
y = data['output']
y_hat = model.predict(x) eval_loss = model.eval(dataset, dataset_sink_mode=False)
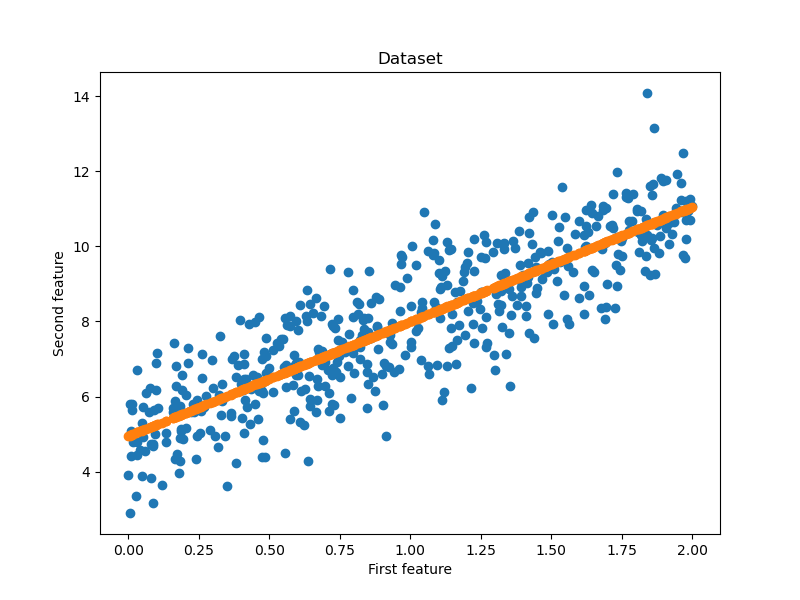
print("{}".format(eval_loss)) fig=plt.figure(figsize=(8,6))#确定画布大小
plt.title("Dataset")#标题名
plt.xlabel("First feature")#x轴的标题
plt.ylabel("Second feature")#y轴的标题
plt.scatter(x.asnumpy(), y.asnumpy())#设置为散点图
plt.scatter(x.asnumpy(), y_hat.asnumpy())#设置为散点图
plt.show()#绘制出来 if __name__ == '__main__':
""" 设置运行的背景context """
from mindspore import context
# 为mindspore设置运行背景context
# context.set_context(mode=context.PYNATIVE_MODE, device_target='GPU')
context.set_context(mode=context.GRAPH_MODE, device_target='GPU') import time
a = time.time()
main()
b = time.time()
print(b-a)
输入结果:

epoch: 1000 step: 1, loss is 1.0764071
epoch: 2000 step: 1, loss is 1.0253074
epoch: 3000 step: 1, loss is 1.0251387
epoch: 4000 step: 1, loss is 1.0251383
epoch: 5000 step: 1, loss is 1.0251379
epoch: 6000 step: 1, loss is 1.0251367
epoch: 7000 step: 1, loss is 1.0251377
epoch: 8000 step: 1, loss is 1.0251374
epoch: 9000 step: 1, loss is 1.0251373
epoch: 10000 step: 1, loss is 1.025136
{'loss': 1.0251359939575195}
62.462594985961914
可以看到使用系统提供的损失函数和优化器同样可以实现算法,但是很神奇的地方是算法的整体运算时间没有降低反而增加了,由前文中的41秒左右提高到了62秒左右,具体原因这里就不知道了,毕竟mindspore框架内部有很多其他的实现,如自动并行之类的,因此它的表现我们这里难以分析,这里只是作为功能尝试而已。
(续) MindSpore 如何实现一个线性回归 —— Demo示例的更多相关文章
- LeadTools Android 入门教学——运行第一个Android Demo
LeadTools 有很多Windows平台下的Demo,非常全面,但是目前开发手机应用的趋势也越来越明显,LeadTools也给大家提供了10个Android的Demo,这篇文章将会教你如何运行第一 ...
- 一个数据源demo
前言 我们重复造轮子,不是为了证明我们比那些造轮子的人牛逼,而是明白那些造轮子的人有多牛逼. JDBC介绍 在JDBC中,我们可以通过DriverManager.getConnection()创建(而 ...
- 快速搭建一个直播Demo
缘由 最近帮朋友看一个直播网站的源码,发现这份直播源码借助 阿里云 .腾讯云这些大公司提供的SDK 可以非常方便的搭建一个直播网站.下面我们来给大家讲解下如何借助 腾讯云 我们搭建一个简易的 直播示例 ...
- Visual Studio 2017 - Windows应用程序打包成exe文件(2)- Advanced Installer 关于Newtonsoft.Json,LINQ to JSON的一个小demo mysql循环插入数据、生成随机数及CONCAT函数 .NET记录-获取外网IP以及判断该IP是属于网通还是电信 Guid的生成和数据修整(去除空格和小写字符)
Visual Studio 2017 - Windows应用程序打包成exe文件(2)- Advanced Installer Advanced Installer :Free for 30 da ...
- 【分享】Vue 资源典藏(UI组件、开发框架、服务端、辅助工具、应用实例、Demo示例)
Vue 资源典藏,包括:UI组件 开发框架 服务端 辅助工具 应用实例 Demo示例 element ★11612 - 饿了么出品的Vue2的web UI工具套件 Vux ★7503 - 基于Vue和 ...
- kafka_2.11-0.8.2.1+java 生产消费程序demo示例
Kafka学习8_kafka java 生产消费程序demo示例 kafka是吞吐量巨大的一个消息系统,它是用scala写的,和普通的消息的生产消费还有所不同,写了个demo程序供大家参考.kaf ...
- SpringBoot整合Swagger2(Demo示例)
写在前面 由于公司项目采用前后端分离,维护接口文档基本上是必不可少的工作.一个理想的状态是设计好后,接口文档发给前端和后端,大伙按照既定的规则各自开发,开发好了对接上了就可以上线了.当然这是一种非常理 ...
- Vue UI组件 开发框架 服务端 辅助工具 应用实例 Demo示例
Vue UI组件 开发框架 服务端 辅助工具 应用实例 Demo示例 element ★11612 - 饿了么出品的Vue2的web UI工具套件 Vux ★7503 - 基于Vue和WeUI的组件库 ...
- Go学习【02】:理解Gin,搭一个web demo
Go Gin 框架 说Gin是一个框架,不如说Gin是一个类库或者工具库,其包含了可以组成框架的组件.这样会更好理解一点. 举个 下面的示例代码在这:github 利用Gin组成最基本的框架.说到框架 ...
- ArcGIS API for JavaScript开发环境搭建及第一个实例demo
原文:ArcGIS API for JavaScript开发环境搭建及第一个实例demo ESRI公司截止到目前已经发布了最新的ArcGIS Server for JavaScript API v3. ...
随机推荐
- Selenium模块的使用(二)
selenium处理iframe - 如果定位的标签存在于iframe标签之中,则必须使用switch_to.frame(id) - 动作链(拖动):from selenium.webdriver i ...
- Spring扩展———自定义bean组件注解
引言 Java 注解(Annotation)又称 Java 标注,是 JDK5.0 引入的一种注释机制. Java 语言中的类.方法.变量.参数和包等都可以被标注.和 Javadoc 不同,Java ...
- elasticsearch6.8 ik分词器需安装
elasticsearch6.8 ik分词器需安装order_info_es/_analyze POST{ "analyzer": "ik_max_word" ...
- 从 Docker Hub 拉取镜像受阻?这些解决方案帮你轻松应对
最近一段时间 Docker 镜像一直是 Pull 不下来的状态,感觉除了挂,想直连 Docker Hub 是几乎不可能的.更糟糕的是,很多原本可靠的国内镜像站,例如一些大厂和高校运营的,也陆续关停了, ...
- 11-CSS定位
01 CSS定位概念理解 01 标准流布局概念的理解 02 position属性 02 相对定位 依然在标准流中 应用场景: 在不影响其它元素的情况下,对当前元素进行微调 <!DOCTYPE h ...
- Apache Kylin(二)在EMR上搭建Kylin
EMR上搭建kylin 1. 启动EMR集群 根据官网说明: http://kylin.apache.org/docs21/install/kylin_aws_emr.html 启动EMR时,若是 h ...
- 在Linux驱动中使用regmap
背景 在学习SPI的时候,看到了某个rtc驱动中用到了regmap,在学习了对应的原理以后,也记录一下如何使用. 介绍 在Linu 3.1开始,Linux引入了regmap来统一管理内核的I2C, S ...
- Linux驱动中的异步函数(aio_read和aio_write)
Linux驱动中的异步函数(aio_read和aio_write) 我们可以在signal_handler使用了read和write函数处理设备文件的读写操作.然而这两个函数可以分别用aio_read ...
- arm linux 移植 SQLite 3
背景 SQLite 是 一个 常用于 嵌入式平台的 轻量级数据库. host平台 :Ubuntu 16.04 arm平台 : S5P6818 SQLite :3.31.1 arm-gcc :4.8.1 ...
- 记一次aspnetcore发布部署流程初次使用k8s
主题: aspnetcorewebapi项目,提交到gitlab,通过jenkins(gitlab的ci/cd)编译.发布.推送到k8s. 关于gitlab.jenkins.k8s安装,都是使用doc ...