LeetCode 3093. 最长公共后缀查询 (二分法)
LeetCode 3093. 最长公共后缀查询
1 题目描述
给你两个字符串数组 wordsContainer 和 wordsQuery 。
对于每个 wordsQuery[i] ,你需要从 wordsContainer 中找到一个与 wordsQuery[i] 有 最长公共后缀 的字符串。如果 wordsContainer 中有两个或者更多字符串有最长公共后缀,那么答案为长度 最短 的。如果有超过两个字符串有 相同 最短长度,那么答案为它们在 wordsContainer 中出现 更早 的一个。
请你返回一个整数数组 ans ,其中 ans[i]是 wordsContainer中与 wordsQuery[i] 有 最长公共后缀 字符串的下标。
示例 1:
输入:wordsContainer = ["abcd","bcd","xbcd"], wordsQuery = ["cd","bcd","xyz"]
输出:[1,1,1]
解释:
我们分别来看每一个 wordsQuery[i] :
- 对于
wordsQuery[0] = "cd",wordsContainer中有最长公共后缀"cd"的字符串下标分别为 0 ,1 和 2 。这些字符串中,答案是下标为 1 的字符串,因为它的长度为 3 ,是最短的字符串。 - 对于
wordsQuery[1] = "bcd",wordsContainer中有最长公共后缀"bcd"的字符串下标分别为 0 ,1 和 2 。这些字符串中,答案是下标为 1 的字符串,因为它的长度为 3 ,是最短的字符串。 - 对于
wordsQuery[2] = "xyz",wordsContainer中没有字符串跟它有公共后缀,所以最长公共后缀为"",下标为 0 ,1 和 2 的字符串都得到这一公共后缀。这些字符串中, 答案是下标为 1 的字符串,因为它的长度为 3 ,是最短的字符串。
示例 2:
输入:wordsContainer = ["abcdefgh","poiuygh","ghghgh"], wordsQuery = ["gh","acbfgh","acbfegh"]
输出:[2,0,2]
解释:
我们分别来看每一个 wordsQuery[i] :
- 对于
wordsQuery[0] = "gh",wordsContainer中有最长公共后缀"gh"的字符串下标分别为 0 ,1 和 2 。这些字符串中,答案是下标为 2 的字符串,因为它的长度为 6 ,是最短的字符串。 - 对于
wordsQuery[1] = "acbfgh",只有下标为 0 的字符串有最长公共后缀"fgh"。所以尽管下标为 2 的字符串是最短的字符串,但答案是 0 。 - 对于
wordsQuery[2] = "acbfegh",wordsContainer中有最长公共后缀"gh"的字符串下标分别为 0 ,1 和 2 。这些字符串中,答案是下标为 2 的字符串,因为它的长度为 6 ,是最短的字符串。
提示:
1 <= wordsContainer.length, wordsQuery.length <= 1041 <= wordsContainer[i].length <= 5 * 1031 <= wordsQuery[i].length <= 5 * 103wordsContainer[i]只包含小写英文字母。wordsQuery[i]只包含小写英文字母。wordsContainer[i].length的和至多为5 * 105。wordsQuery[i].length的和至多为5 * 105。
2 解题思路
这题最容易想到的方法应该就是字典树了,当然如果只是这样的话我也没有必要写这篇题解。
这里要介绍的方法是通过二分搜索,在使用几乎最少的额外空间下完成这道题。
2.1 翻转字符串
首先,我们需要将这个问题从后缀匹配转换为前缀匹配问题,也就是先把所有的字符串都进行一次翻转,在此过程中用map记录他们的下标。
后面要用到二分搜索,因此还需要进行一次排序,转换为有序数组。
unordered_map<string, int> index{};
int num = 0;
for (auto &words : wordsContainer)
{
// 翻转字符串
reverse(words.begin(), words.end());
// 相同的字符串仅记录最早的下标
if (!index.count(words))
{
index[words] = num;
}
num++;
}
sort(wordsContainer.begin(), wordsContainer.end());
2.2 二分搜索迭代
接下来我们就需要思考,该如何利用二分搜索来找到答案。
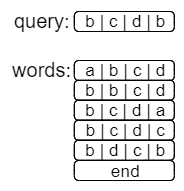
举个栗子,我们需要在words中寻找query对应的最大前缀。
如果我们直接以query为目标,在words中进行二分搜索,其结果肯定是不正确的。
换个角度思考,我们要找到是最长的前缀,那我们大可以不以query为目标,而是先用二分搜索,把所有b开头的字符串给找到。
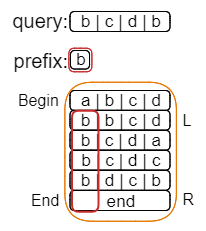
操作过程就如上图所示,其中橙色方框为查找的范围,红色方框则是搜索的结果,二者都是左闭右开区间。
其中搜索上界可以使用lower_bound,下界则是使用upper_bound。
可以看出,我们已经找到了开头为b的字符串,其范围是[1, 5),所以我们就可以将查找的范围更新为[1, 5)。
而接下来的事情,想必你也能猜到了,那就是在此基础上继续查找第二个字符为c的字符串。
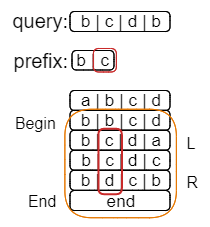
搜索范围从[1, 5)缩小到了[2, 4),接着继续查找第三个字符为d的字符串。
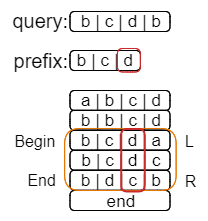
这次的结果还是[2, 4),最后再查找第四个字符为b的字符串。
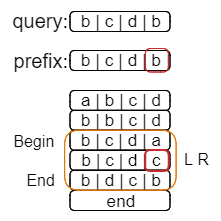
有意思的事情发生了,搜索的结果[4, 4)是一个空区间,这说明已经没有能够继续匹配的字符串。这就意味着上一个搜索的结果(也就是[2, 4))就已经是能够找到的最长公共前缀字符串的区间了。
具体的代码如下:
auto begin = wordsContainer.begin();
auto end = wordsContainer.end();
for (string prefix{}; query.size(); query.pop_back())
{
prefix.push_back(query.back());
compare cmp(prefix.size() - 1);
auto nBegin = lower_bound(begin, end, prefix, cmp);
auto nEnd = upper_bound(begin, end, prefix, cmp);
// nBegin == nEnd表示已经达到最大前缀匹配
// 直接退出循环,在目前的[begin, end)范围中寻找最合适的结果
if (nBegin == nEnd)
{
break;
}
begin = nBegin;
end = nEnd;
}
2.3 遍历区间
最后,我们就可以根据题目的要求,在最终的区间内找出长度最短且出现最早的字符串的下标,作为本次查询的结果。
int minSize = INT32_MAX;
int minIndex = INT32_MAX;
while (begin != end)
{
string &s = *begin++;
if (s.size() < minSize ||
s.size() == minSize && index[s] < minIndex)
{
minSize = s.size();
minIndex = index[s];
}
}
ans.push_back(minIndex);
2.4 比较函数
其实在二分搜索的那一节还有些问题没有解决,比如我们要如何实现搜索呢?
我们使用lower_bound和upper_bound函数定位的上下界时,比较的并不是传入的字符串,而是比较其中特定位置的字符,并且这个位置会随需求变化。这里就可以通过定义仿函数,来将每次比较所需要的下标信息传入其中。
class compare
{
public:
compare(int index) : index(index) {}
int index;
bool operator()(const string &s1, const string &s2)
{
return /*返回比较的结果*/;
}
};
先别急着在函数中返回s1[index] < s2[index]的结果,让我们接着分析一下具体情况。
首先,我们需要明确的是,比较函数中传入的两个参数,一个是待匹配的字符串words,另一个是当前前缀prefix。
从之前的搜索过程可以看出index = prefix.size() - 1,所以prefix绝对不会出现访问越界的情况,但words就不一定了。

当index小于s1.size()和s2.size()时,我们可以直接返回s1[index] < s2[index]

但是当words.size() <= index时,我们就需要分两种情况来判断。
- s1 = words:
s1[index]没有字符,视为最小值,因此s1[index] < s2[index] == true - s2 = words:
s2[index]没有字符,视为最小值,因此s1[index] < s2[index] == false
我们将上述三种情况整理一下,用以下代码表示:
bool operator()(const string &s1, const string &s2)
{
// if(s1.size() <= index) return true;
// if(s2.size() <= index) return false;
// return s1[index] < s2[index];
return s1.size() <= index ||
s2.size() > index && s1[index] < s2[index];
}
3 答案代码
最终代码如下:
class compare
{
public:
compare(int index) : index(index) {}
int index;
bool operator()(const string &s1, const string &s2)
{
// if(s1.size() <= index) return true;
// if(s2.size() <= index) return false;
// return s1[index] < s2[index];
return s1.size() <= index ||
s2.size() > index && s1[index] < s2[index];
}
};
vector<int> stringIndices(vector<string> &wordsContainer,
vector<string> &wordsQuery)
{
vector<int> ans{};
unordered_map<string, int> index{};
int num = 0;
for (auto &words : wordsContainer)
{
reverse(words.begin(), words.end());
// 相同的字符串仅记录最早的下标
if (!index.count(words))
{
index[words] = num;
}
num++;
}
sort(wordsContainer.begin(), wordsContainer.end());
for (auto &query : wordsQuery)
{
auto begin = wordsContainer.begin();
auto end = wordsContainer.end();
for (string prefix{}; query.size(); query.pop_back())
{
prefix.push_back(query.back());
compare cmp(prefix.size() - 1);
auto nBegin = lower_bound(begin, end, prefix, cmp);
auto nEnd = upper_bound(begin, end, prefix, cmp);
// nBegin == nEnd表示已经达到最大前缀匹配
// 直接退出循环,在目前的[begin, end)范围中寻找最合适的结果
if (nBegin == nEnd)
{
break;
}
begin = nBegin;
end = nEnd;
}
int minSize = INT32_MAX;
int minIndex = INT32_MAX;
while (begin != end)
{
string &s = *begin++;
if (s.size() < minSize ||
s.size() == minSize && index[s] < minIndex)
{
minSize = s.size();
minIndex = index[s];
}
}
ans.push_back(minIndex);
}
return ans;
}
本文发布于2024年3月27日
最后编辑于2024年3月27日
LeetCode 3093. 最长公共后缀查询 (二分法)的更多相关文章
- LeetCode:最长公共前缀【14】
LeetCode:最长公共前缀[14] 题目描述 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flo ...
- python(leetcode)-14最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- 【LeetCode】最长公共前缀【二分】
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- LeetCode 14. 最长公共前缀(Longest Common Prefix)
14. 最长公共前缀 14. Longest Common Prefix 题目描述 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". Lee ...
- Java实现 LeetCode 14 最长公共前缀
14. 最长公共前缀 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower",&quo ...
- [LeetCode]14.最长公共前缀(Java)
原题地址: longest-common-prefix 题目描述: 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入:st ...
- LeetCode 7最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- leetcode 14 最长公共前缀
描述: 给个字符串vector,求最长公共前缀. 解决: 直接取第一个字符串作为最长公共前缀,将其每个字符遍历过一次.设最长字符实际为k,共n个元素,则复杂度O(nk) string longestC ...
- 领扣(LeetCode)最长公共前缀 个人题解
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- LeetCode 14. 最长公共前缀(Longest Common Prefix)
题目描述 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow ...
随机推荐
- Java 中拼接 String 的 N 种方式
文章持续更新,可以关注公众号程序猿阿朗或访问未读代码博客. 本文 Github.com/niumoo/JavaNotes 已经收录,欢迎Star. 1. 前言 Java 提供了拼接 String 字符 ...
- zip压缩模块,tarfile压缩模块,包和模块,format格式化的复习--day17
1.zipfile模块 import zipfile #导入模块 1.压缩文件 (1)创建压缩包 参数1压缩包名字,参数2以w模式创建,参数3压缩固定写法 zf = zipfile.ZipFile(& ...
- 并发与并行的区别---python
并发与并行的区别 Erlang 之父 Joe Armstrong 用一张5岁小孩都能看懂的图解释了并发与并行的区别 并发是两个队列交替使用一台咖啡机,并行是两个队列同时使用两台咖啡机 如果是串行,一个 ...
- 【Azure 应用服务】应用服务连接 Azure MySQL 一直失败,报错 Create connection error
问题描述 App Service上部署的Java应用,连接 Azure Database for MySQL 失败.错误信息:Create connection error, url: jdbc:my ...
- 【Azure Developer】使用MSAL4J 与 ADAL4J 的SDK时候,遇见了类型冲突问题 "java.util.Collections$SingletonList cannot be cast to java.lang.String"
问题描述 在博文 "[Azure Developer]使用 Powershell az account get-access-token 命令获取Access Token (使用用户名+密码 ...
- Nebula Graph 源码解读系列 | Vol.04 基于 RBO 的 Optimizer 实现
上篇我们讲述了一个执行计划是如何生成的,这次我们来看下这个生成的执行计划是被 Optimizer 优化的. 概述 Optimizer,优化器,顾名思义就是一个用来优化执行计划的组件.数据库的优化器通常 ...
- STL-string模拟实现
1 #pragma once 2 3 #include<iostream> 4 #include<string.h> 5 #include<assert.h> 6 ...
- Codeforces Round 770 (Div. 2)(数学异或奇偶性)
B. Fortune Telling 拿到题目看数据范围之后就知道暴力显然是来不及的. 那么只能找性质. \(考虑x和x+3的不同 \quad 奇偶性不同\) \(然后考虑两种操作对于一个数的奇偶性的 ...
- CPNtools协议建模安全分析---实例库所标记(四)
1.我们经常使用弧上单个变量表达式来过滤数据类型,如果是多个类型的变量可以嵌套写 像上面的的 库所标记的数值 1·(2,5,"a")++ 那么弧表达式会根据要求来过滤 ...
- java服务OOM和CPU飙升排查
一.JVM参数 -D 可以是系统默认有的参数,也可以是自己定义的参数 -Dfile.encoding=UTF-8 -Dmaven.test.skip=true -Dspring.profiles.ac ...