clickhouse 优化实践,万级别QPS数据毫秒写入和亿级别数据秒级返回 | 京东云技术团队
1、背景
魔笛活动平台目前在采集每个活动的用户行为数据并进行查询,解决线上问题定位慢,响应不及时的问题,提升客诉的解决效率。目前每天采集的数据量5000万+,一个月的数据总量15亿+,总数据量40亿+,随着接入的活动越来越多,采集上报的数据量也会越来越大。目前采用ClickHouse来存储数据,可以在秒级别内处理数十亿条数据,能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。这里关于ClickHouse就不再赘述,感兴趣的可以看上篇文章。这里是我在实际使用过程中,发现了一些写入和查询的相关问题,并进行了相应的优化。
2、写入优化
2.1 历史方案
为了更好的收集活动数据,自己开发了一款埋点sdk用于收集各业务的活动埋点数据,埋点数据统一异步发送MQ,然后活动平台消费MQ数据,经过一定处理后通过MybatisPlus方式批量写入clickhouse,每次批量写入5000条。
2.2 出现的问题
当消费MQ的TPS超过3000的时候,出现了以下问题:
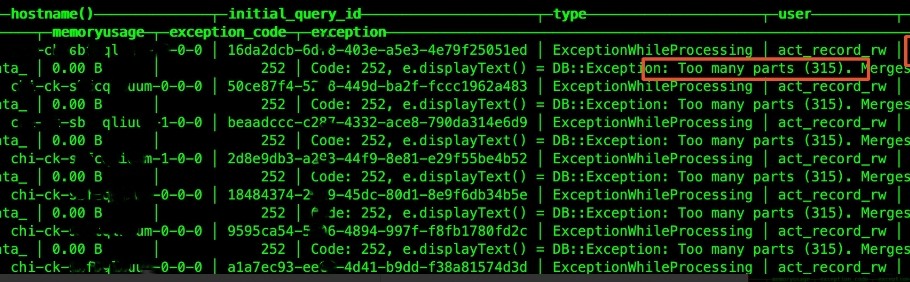
1. 出现报错:写入量大的时候会报这个错误:too many parts。
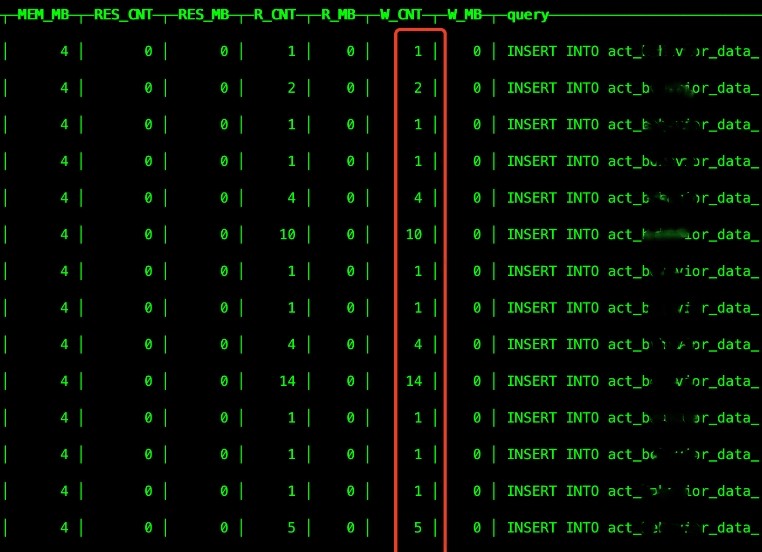
2. 单次写入条数少:我明明配置的每次批量写入5000条,但是每次基本都是一条一条写入。
3. 性能很差:单次写入最大耗时居然有250000毫秒,平均也超过50000毫秒!

2.3 出现问题的原因
(1)单次写入条数少原因:MybatisPlus的savebatch单次最大写入SQL是4M,按照单条活动的数据大小,最大单次也就写1000条数据,再多就会一次一次写入。所以虽然配置的是每次写入5000,但是实际看是每次写入一条或者几条。
(2)too many parts错误:clickhouse操作数据的最小操作单元是block,每次写入都会按照zookeeper记录的唯一自增的blockId,按照PartitionId_blockId_blockId_0生成data parts,也就是小文件,然后后台会有merge线程,不定时(分钟级别)的将多个小文件进行合并,生成PartitionId_MinBlockNum_MaxBlockBum_Level的文件,未达到data parts最小rows或者大小限制前,会持续merge,每次merge的耗时大概5分钟左右。由于merge线程池是固定的,默认32,所以如果插入过于频繁,merge压力过大,处理不了,就会出现too many parts的报错。例如并发数为 200,这样一批写入到 ClickHouse 中就会产生 200 个文件,几批下来如果 ClickHouse 内部线程没来及合并相同分区,就会抛异常。而 ClickHouse 默认一次合并超过 300 个文件就会报错。
(3)性能差的原因:因为写clickhouse底层都是使用httpclient的方式写入的,所以对于clickhouse来说单条频繁写入效率很低。

2.4 改造方案
(1)写入clickhouse的并发数调小,批处理的数据size间隔调大,比如之前200并发调整到50并发,从之前一批1条数据调整到10000条数据,clickhouse官网建议每批次写入100000+条(要视flink TM 内存大小调整,防止批量过大出现oom)。从而减少clickhouse文件的个数,避免超过parts_to_throw_insert默认值。一般最好一秒钟写入一次clickhouse。
(2)将由MybatisPlus的savebatch批量写入改为其他方式写入。采用clickhouse原生的jdbc写入或者flink摄入,flink我这边自定义了sink 用于摄入clickhouse,达到一定批次或者执行checkpoint时就写入一次。
(3)为了保证批量,我这边采用实时双buffer缓冲队列方式写入,这个队列可以是本地缓存队列,也可以是redis缓存队列。根据时间窗口期和固定写入阈值(针对波动大的可以按照二次指数平滑函数去确定阈值)进行写入与否的判断。设置一个读队列,一个写队列,并设置一个开关,一个阈值,一个定时器,当数据来时,默认放入写队列中,当队列中数据的数量大于阈值,将开关关闭,将写队列数据放到读队列中,从读队列拿出数据批量写入clickhouse,将开关打开,清空队列中数据。如果队列中数据在一定时间内,比如10秒,一直没有达到阈值,也关闭开关,写队列数据放到读队列中,从读队列拿出数据批量写入clickhouse,将开关打开,清空队列中数据。
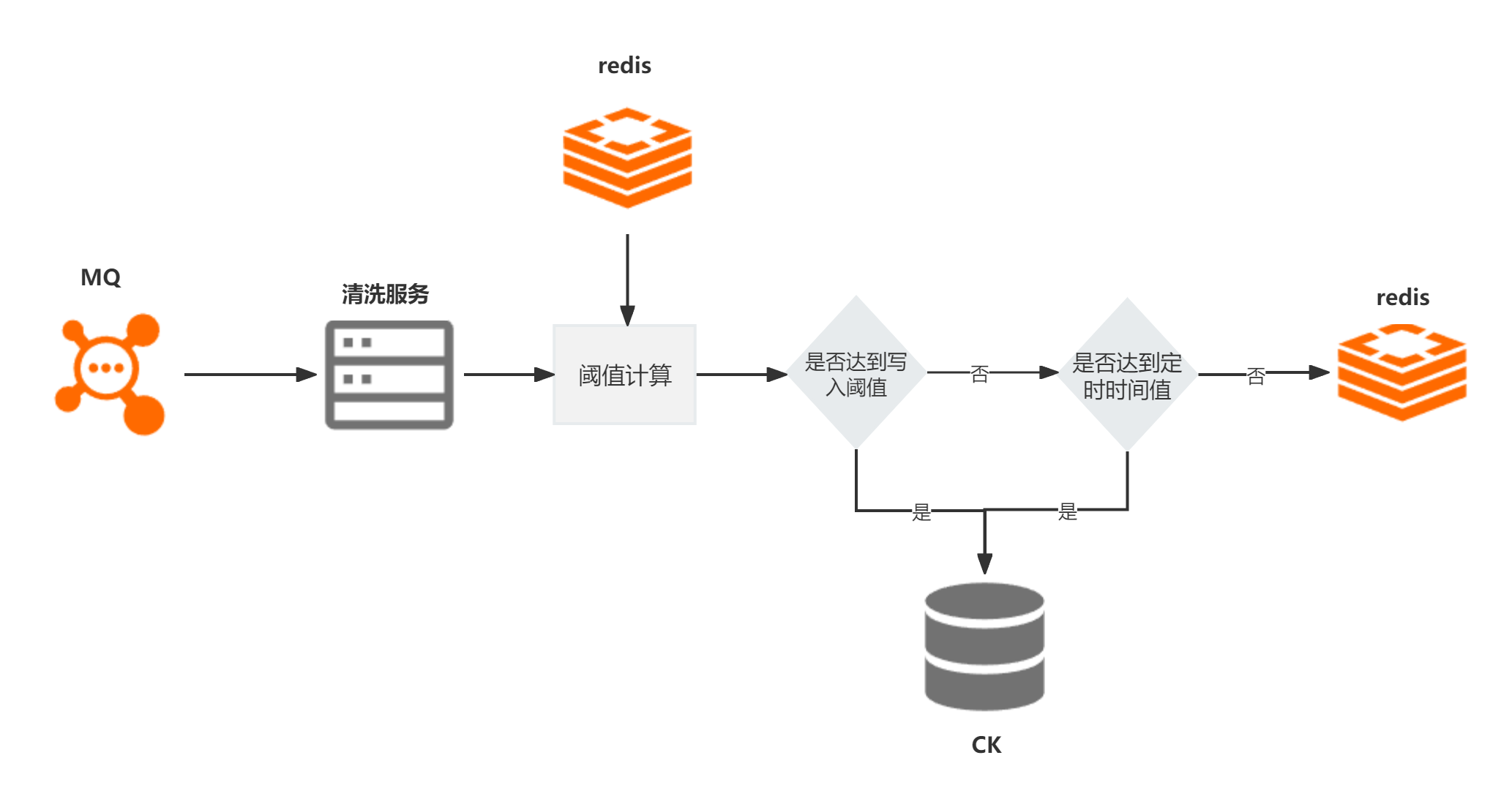
2.5 效果
MQ消费的TPS最高是2万+,也就是每秒写入的条数最高超过了俩万,在此情况下,保证了每秒只写入clickhouse一次,写入性能也稳定在50毫秒左右,写入性能相比较于之前方案提升了5000倍,吞吐量相较于之前也提升了几十倍。


3、查询优化
3.1 历史方案
索引:一级索引是时间,二级索引是id,因为大部分是根据时间来查询,id作为排序。
字段值:写入时候将字段值默认为空。
查询:查询时候查询所有列的数据,再线性查询每条数据的活动信息、奖励信息等。
3.2 出现的问题
目前生产环境有40亿+数据,耗时很长,达到了30秒,非常非常慢。
3.3 出现问题的原因
尝试通过SQL执行计划来确定一个sql 的查询瓶颈。目前查看sql 执行计划有两种方法:
方法一(20.6之前版本):clickhouse-client -u xxxx --password xxxxxx --send_logs_level=trace <<< 'your query sql' > /dev/null;
方法二(20.6与20.6之后版本):explain SQL。
方法一是指定clickhouse 执行日志级别为trace,这样可以打印出来sql 各个阶段执行的日志,通过日志型来分析SQL执行情况,能够详细的了解到SQL执行情况。方法二有点像mysql那样,但这个只能打印部分SQL执行情况,不够详细。所以我们最终使用了方法一。
通过分析发现这几方面原因:
(1)查询缓慢的都是固定维度查询的,例如:用户pin、活动id等。分析了查询sql 的执行计划,主键索引和分区都没有用到。没有用到主键索引是导致查询慢的主要原因。至于为什么,这个要从clickhouse的底层存储结构说了,这里不详细说明,想了解的可以去看看我上篇文章。
(2)因为ClickHouse对于空值,在底层存储是用了单独的文件存储。相对于没有空值的情况,存在空值会稍微影响查询性能。
(3)没有分区查询,跟hive一样,表分区后,底层也会有相关的分区目录,筛选的时候添加分区过滤,提升查询性能。
3.4 改造方案
3.5 效果
40亿+的数据量,由之前13-20秒提升为800-1200毫秒返回,约提升15-20倍。
4、思考
如果后续数据量超过百亿,达到几百亿甚至千亿级别的数据量,性能还会不会这么好呢?这时候可以考虑分表策略,将用户pin进行hash,例如分十张表存储数据,将每张表数据控制在50-100亿级别。在数据写入这块,使用分表了策略后还需要自定义分表摄入的策略。
作者:京东科技 苗元
来源:京东云开发者社区 转载请注明来源
clickhouse 优化实践,万级别QPS数据毫秒写入和亿级别数据秒级返回 | 京东云技术团队的更多相关文章
- 字节跳动基于ClickHouse优化实践之“多表关联查询”
更多技术交流.求职机会.试用福利,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻.但在字节大量 ...
- 技术干货:实时视频直播首屏耗时400ms内的优化实践
本文由“逆流的鱼yuiop”原创分享于“何俊林”公众号,感谢作者的无私分享. 1.引言 直播行业的竞争越来越激烈,进过2018年这波洗牌后,已经度过了蛮荒暴力期,剩下的都是在不断追求体验.最近正好在做 ...
- 让Elasticsearch飞起来!——性能优化实践干货
原文:让Elasticsearch飞起来!--性能优化实践干货 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog ...
- 融云技术分享:融云安卓端IM产品的网络链路保活技术实践
本文来自融云技术团队原创分享,原文发布于“ 融云全球互联网通信云”公众号,原题<IM 即时通讯之链路保活>,即时通讯网收录时有部分改动. 1.引言 众所周知,IM 即时通讯是一项对即时性要 ...
- 京东云开发者|京东云RDS数据迁移常见场景攻略
云时代已经来临,云上很多场景下都需要数据的迁移.备份和流转,各大云厂商也大都提供了自己的迁移工具.本文主要介绍京东云数据库为解决用户数据迁移的常见场景所提供的解决方案. 场景一:数据迁移上云 数据迁移 ...
- 虎牙在全球 DNS 秒级生效上的实践 集群内通过 raft 协议同步数据,毫秒级别完成同步。
https://mp.weixin.qq.com/s/9bEiE4QFBpukAfNOYhmusw 虎牙在全球 DNS 秒级生效上的实践 原创: 周健&李志鹏 阿里巴巴中间件 今天
- 【DataMagic】如何在万亿级别规模的数据量上使用Spark
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文首发在云+社区,未经许可,不得转载. 作者:张国鹏 | 腾讯 运营开发工程师 一.前言 Spark作为大数据计算引擎,凭借其快速.稳定. ...
- 从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
本文来自火山引擎公众号,原文发布于2021-09-06. 近日,字节跳动旗下的企业级技术服务平台火山引擎正式对外发布「ByteHouse」,作为 ClickHouse 企业版,解决开源技术上手难 &a ...
- Redis各种数据结构性能数据对比和性能优化实践
很对不起大家,又是一篇乱序的文章,但是满满的干货,来源于实践,相信大家会有所收获.里面穿插一些感悟和生活故事,可以忽略不看.不过听大家普遍的反馈说这是其中最喜欢看的部分,好吧,就当学习之后轻松一下. ...
- 如何在万亿级别规模的数据量上使用Spark
一.前言 Spark作为大数据计算引擎,凭借其快速.稳定.简易等特点,快速的占领了大数据计算的领域.本文主要为作者在搭建使用计算平台的过程中,对于Spark的理解,希望能给读者一些学习的思路.文章内容 ...
随机推荐
- 从相识到相惜:Redis与计算存储分离四部曲
摘要:协议兼容问题.性能问题.数据备份问题.数据容量问题--这些都是数据库在使用过程中必然会遇见的问题.就好比选择结婚对象,你需要去对比不同的方面,最后选出最好的.最合适的. 近期全国两会正在轰轰烈烈 ...
- 云小课|ModelArts Pro 视觉套件 零代码构建视觉AI应用
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:ModelArts ...
- 总结vue3 的一些知识点:MySQL 排序
MySQL 排序 我们知道从 MySQL 表中使用 SQL SELECT 语句来读取数据. 如果我们需要对读取的数据进行排序,我们就可以使用 MySQL 的 ORDER BY 子句来设定你想按哪个字段 ...
- CPU推理|使用英特尔 Sapphire Rapids 加速 PyTorch Transformers
在 最近的一篇文章 中,我们介绍了代号为 Sapphire Rapids 的第四代英特尔至强 CPU 及其新的先进矩阵扩展 (AMX) 指令集.通过使用 Amazon EC2 上的 Sapphire ...
- 【奥运会】yahoo的这个骚操作令人费解。。。
昨天在朋友圈发了一张截图,貌似很多朋友没有 get 到点,我也实在搞不懂 Yahoo 的这波操作. 默认排序是按照金牌总数,那必然是美国第一名了.不过习惯上不应该是按照金牌总数进行排名吗?毕竟金银铜牌 ...
- STM32CubeMX教程17 DAC - 输出三角波噪声波
1.准备材料 正点原子stm32f407探索者开发板V2.4 STM32CubeMX软件(Version 6.10.0) keil µVision5 IDE(MDK-Arm) ST-LINK/V2驱动 ...
- 【3rd_Party】format() 处理一些常见的格式化解决方案
fmt的痛与对format设计的思考 fmt:轻量高性能的C++格式化库 C++20 引入了新的 format() 函数,该函数以字符串形式返回参数的格式化表示.format() 使用 python ...
- HDU - 1711:Number Sequence (KMP模板)
原题链接 KMP模板:AC,858ms,13112KB内存 消耗太大了 #include<bits/stdc++.h> using namespace std; using namespa ...
- POJ2431 优先队列+贪心
题目大意: 见<挑战程序设计竞赛>P74. 我的理解: 优先队列+贪心 注意把输入的距离(加油站到终点)改为起点到加油站. 因为求得是最优解,需要尽可能少的加油站,所以我们每次希望去加油的 ...
- Codeforces Round #739 (Div. 3) 个人题解(A~F2)
比赛链接:Here 1560A. Dislike of Threes Description 找出第 $k$ 大的不可被 $3$ 整除以及非 $3$ 结尾的整数 直接枚举出前 1000 个符合条件的数 ...