[转帖]Elasticsearch 的 30 个调优最佳实践!
Elasticsearch 的 30 个调优最佳实践!
https://zhuanlan.zhihu.com/p/406264041
ES 发布时带有的默认值,可为 es 的开箱即用带来很好的体验。全文搜索、高亮、聚合、索引文档 等功能无需用户修改即可使用,当你更清楚的知道你想如何使用 es 后,你可以作很多的优化以提高你的用例的性能,下面的内容告诉你 你应该/不应该 修改哪些配置。
第一部分:调优索引速度
❝https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html
❞
「使用批量请求批量请求将产生比单文档索引请求好得多的性能。」
为了知道批量请求的最佳大小,您应该在具有单个分片的单个节点上运行基准测试。首先尝试索引 100 个文件,然后是 200,然后是 400,等等。当索引速度开始稳定时,您知道您达到了数据批量请求的最佳大小。在配合的情况下,最好在太少而不是太多文件的方向上犯错。请注意,如果群集请求太大,可能会使群集受到内存压力,因此建议避免超出每个请求几十兆字节,即使较大的请求看起来效果更好。
「发送端使用多 worker/多线程向 es 发送数据 发送批量请求的单个线程不太可能将 Elasticsearch 群集的索引容量最大化。为了使用集群的所有资源,您应该从多个线程或进程发送数据。除了更好地利用集群的资源,这应该有助于降低每个 fsync 的成本。」
请确保注意 TOOMANYREQUESTS(429)响应代码(Java客户端的EsRejectedExecutionException),这是 Elasticsearch 告诉您无法跟上当前索引速率的方式。发生这种情况时,应该再次尝试暂停索引,理想情况下使用随机指数回退。
与批量调整大小请求类似,只有测试才能确定最佳的 worker 数量。这可以通过逐渐增加工作者数量来测试,直到集群上的 I/O 或 CPU 饱和。
「1.调大 refresh interval」
默认的 index.refresh_interval 是 1s,这迫使 Elasticsearch 每秒创建一个新的分段。增加这个价值(比如说 30s)将允许更大的部分 flush 并减少未来的合并压力。
「2.加载大量数据时禁用 refresh 和 replicas」
如果您需要一次加载大量数据,则应该将 index.refreshinterval 设置为 -1 并将 index.numberofreplicas 设置为 0 来禁用刷新。这会暂时使您的索引处于危险之中,因为任何分片的丢失都将导致数据 丢失,但是同时索引将会更快,因为文档只被索引一次。初始加载完成后,您可以将 index.refreshinterval 和 index.numberofreplicas 设置回其原始值。
「3.设置参数,禁止 OS 将 es 进程 swap 出去」
您应该确保操作系统不会 swapping out the java 进程,通过禁止 swap (https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration-memory.html)
「4.为 filesystem cache 分配一半的物理内存」
文件系统缓存将用于缓冲 I/O 操作。您应该确保将运行 Elasticsearch 的计算机的内存至少减少到文件系统缓存的一半。
「5.使用自动生成的id(auto-generated ids)」
索引具有显式 id 的文档时,Elasticsearch 需要检查具有相同 id 的文档是否已经存在于相同的分片中,这是昂贵的操作,并且随着索引增长而变得更加昂贵。通过使用自动生成的 ID,Elasticsearch 可以跳过这个检查,这使索引更快。
「6.买更好的硬件」
搜索一般是 I/O 密集的,此时,你需要
- 为 filesystem cache 分配更多的内存
- 使用 SSD 硬盘
- 使用 local storage(不要使用 NFS、SMB 等 remote filesystem)
- 亚马逊的 弹性块存储(Elastic Block Storage)也是极好的,当然,和 local storage 比起来,它还是要慢点
如果你的搜索是 CPU 密集的,买好的 CPU 吧
「7.加大 indexing buffer size」
如果你的节点只做大量的索引,确保 index.memory.indexbuffersize 足够大,每个分区最多可以提供 512 MB 的索引缓冲区,而且索引的性能通常不会提高。Elasticsearch 采用该设置(java 堆的一个百分比或绝对字节大小),并将其用作所有活动分片的共享缓冲区。非常活跃的碎片自然会使用这个缓冲区,而不是执行轻量级索引的碎片。
「默认值是 10%,通常很多:例如,如果你给 JVM 10GB 的内存,它会给索引缓冲区 1GB,这足以承载两个索引很重的分片。」
「8.禁用 fieldnames 字段」
fieldnames 字段引入了一些索引时间开销,所以如果您不需要运行存在查询,您可能需要禁用它。(fieldnames:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-field-names-field.html)
「9.剩下的,再去看看 “调优 磁盘使用”吧」
(https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-disk-usage.html)中有许多磁盘使用策略也提高了索引速度。
第二部分-调优搜索速度
「1.filesystem cache越大越好」
为了使得搜索速度更快,es 严重依赖 filesystem cache
一般来说,需要至少一半的可用内存 作为 filesystem cache,这样es可以在物理内存中 保有 索引的热点区域(hot regions of the index)
「2.用更好的硬件」
搜索一般是 I/O bound 的,此时,你需要
- 为 filesystem cache 分配更多的内存
- 使用 SSD 硬盘
- 使用 local storage(不要使用NFS、SMB 等remote filesystem)
- 亚马逊的 弹性块存储(Elastic Block Storage)也是极好的,当然,和 local storage 比起来,它还是要慢点
如果你的搜索是 CPU-bound,买好的 CPU 吧
「3.文档模型(document modeling)」
文档需要使用合适的类型,从而使得 search-time operations 消耗更少的资源。咋作呢?答:避免 join 操作。具体是指
- nested 会使得查询慢 好几倍
- parent-child关系 更是使得查询慢几百倍
如果 无需 join 能解决问题,则查询速度会快很多
「4.预索引 数据」
根据“搜索数据最常用的方式”来最优化索引数据的方式
❝举个例子:所有文档都有price字段,大部分query 在 fixed ranges 上运行 range aggregation。你可以把给定范围的数据 预先索引下。然后,使用 terms aggregation
❞
「5.Mappings(能用 keyword 最好了)」
数字类型的数据,并不意味着一定非得使用numeric类型的字段。
一般来说,存储标识符的 字段(书号 ISBN、或来自数据库的 标识一条记录的 数字),使用 keyword 更好(integer,long 不好哦,亲)
「6.避免运行脚本」
一般来说,脚本应该避免。如果他们是绝对需要的,你应该使用 painless 和 expressions 引擎。
「7.搜索 rounded 日期」
日期字段上使用 now,一般来说不会被缓存。但,rounded date 则可以利用上query cache
rounded 到分钟等
「8.强制 merge只读的index」
只读的 index 可以从“merge 成一个单独的大 segment”中收益
「9.预热 全局序数(global ordinals)」
全局序数用于在 keyword 字段上 运行 terms aggregations。
es 不知道 哪些fields 将用于/不用于 term aggregation,因此 全局序数在需要时才加载进内存。
但,可以在 mapping type 上,定义 eagerglobalordinals==true,这样, refresh 时就会加载 全局序数
「10.预热 filesystem cache」
机器重启时,filesystem cache 就被清空。OS 将 index 的热点区域(hot regions of the index)加载进 filesystem cache 是需要花费一段时间的。
设置 index.store.preload 可以告知 OS 这些文件需要提早加载进入内存
「11.使用索引排序来加速连接」
索引排序对于以较慢的索引为代价来加快连接速度非常有用。在索引分类文档中阅读更多关于它的信息。
「12.使用 preference 来优化高速缓存利用率」
有多个缓存可以帮助提高搜索性能,例如文件系统缓存,请求缓存或查询缓存。然而,所有这些缓存都维护在节点级别,这意味着如果连续运行两次相同的请求,则有一个或多个副本,并使用循环(默认路由算法),那么这两个请求将转到不同的分片副本,阻止节点级别的缓存帮助。
由于搜索应用程序的用户一个接一个地运行类似的请求是常见的,例如为了分析索引的较窄的子集,使用标识当前用户或会话的优选值可以帮助优化高速缓存的使用。
「13.副本可能有助于吞吐量,但不会一直存在」
除了提高弹性外,副本可以帮助提高吞吐量。例如,如果您有单个分片索引和三个节点,则需要将副本数设置为 2,以便共有 3 个分片副本,以便使用所有节点。
现在假设你有一个 2-shards 索引和两个节点。在一种情况下,副本的数量是0,这意味着每个节点拥有一个分片。在第二种情况下,副本的数量是1,这意味着每个节点都有两个碎片。哪个设置在搜索性能方面表现最好?通常情况下,每个节点的碎片数少的设置将会更好。
原因在于它将可用文件系统缓存的份额提高到了每个碎片,而文件系统缓存可能是 Elasticsearch 的 1 号性能因子。同时,要注意,没有副本的设置在发生单个节点故障的情况下会出现故障,因此在吞吐量和可用性之间进行权衡。
那么复制品的数量是多少?如果您有一个具有 numnodes 节点的群集,那么numprimaries 总共是主分片,如果您希望能够一次处理 maxfailures 节点故障,那么正确的副本数是 max(maxfailures,ceil(numnodes / numprimaries) - 1)。
「14.打开自适应副本选择」
当存在多个数据副本时,elasticsearch 可以使用一组称为自适应副本选择的标准,根据包含分片的每个副本的节点的响应时间,服务时间和队列大小来选择数据的最佳副本。这可以提高查询吞吐量并减少搜索量大的应用程序的延迟。
第三部分:通用的一些建议
「1、不要 返回大的结果集」
es 设计来作为搜索引擎,它非常擅长返回匹配 query 的 top n 文档。但,如“返回满足某个 query 的 所有文档”等数据库领域的工作,并不是 es 最擅长的领域。如果你确实需要返回所有文档,你可以使用 Scroll API
「2、避免 大的doc。即,单个doc 小了 会更好」
given that(考虑到) http.maxcontextlength 默认 ==100MB,es 拒绝索引操作 100MB 的文档。当然你可以提高这个限制,但,Lucene 本身也有限制的,其为2GB 即使不考虑上面的限制,大的 doc 会给 network/memory/disk 带来更大的压力;
- 任何搜索请求,都需要获取 _id 字段,由于 filesystem cache 工作方式。即使它不请求 _source字段,获取大 doc _id 字段消耗更大
- 索引大 doc 时消耗内存会是 doc 本身大小的好几倍
- 大 doc 的 proximity search, highlighting 也更加昂贵。它们的消耗直接取决于 doc 本身的大小
「3、避免 稀疏」
- 不相关数据 不要 放入同一个索引
- 一般化文档结构(Normalize document structures)
- 避免类型
- 在 稀疏 字段上,禁用 norms & doc_values 属性
「稀疏为什么不好?」
Lucene 背后的数据结构更擅长处理紧凑的数据
text 类型的字段,norms 默认开启;numerics, date, ip, keyword,docvalues 默认开启 Lucene 内部使用 integer 的 docid 来标识文档和内部API 交互。
❝举个例子:使用 match 查询时生成 docid 的迭代器,这些 docid 被用于获取它们的norm,以便计算 score。当前的实现是每个 doc 中保留一个 byte 用于存储 norm 值。获取 norm 值其实就是读取 doc_id 位置处的一个字节
❞
这非常高效,Lucene 通过此值可以快速访问任何一个 doc 的 norm 值;但,给定一个 doc,即使某个 field 没有值,仍需要为此 doc 的此 field 保留一个字节
docvalues 也有同样的问题。2.0 之前的 fielddata 被现在的 docvalues 所替代了。
稀疏性 最明显的影响是 对存储的需求(任何 doc 的每个 field,都需要一个byte);但是呢,稀疏性 对 索引速度和查询速度 也是有影响的,因为:即使 doc并没有某些字段值,但,索引时,依然需要写这些字段,查询时,需要 skip 这些字段的值
某个索引中拥有少量稀疏字段,这完全没有问题。但,这不应该成为常态
稀疏性影响最大的是 norms&docvalues ,但,倒排索引(用于索引 text以及keyword字段),二维点(用于索引geopoint字段)也会受到较小的影响。
「如何避免稀疏呢?」
1、不相关数据 不要 放入同一个索引 给个tip:索引小(即:doc的个数较少),则,primary shard也要少
2、一般化文档结构(Normalize document structures)
3、避免类型(Avoid mapping type) 同一个index,最好就一个mapping type。在同一个index下面,使用不同的mapping type来存储数据,听起来不错,但,其实不好。given that(考虑到)每一个mapping type会把数据存入 同一个index,因此,多个不同mapping type,各个的field又互不相同,这同样带来了稀疏性 问题
4、在 稀疏 字段上,禁用 norms & doc_values 属性
- norms用于计算score,无需score,则可以禁用它(所有filtering字段,都可以禁用norms)
- docvlaues用于sort&aggregations,无需这两个,则可以禁用它 但是,不要轻率的做出决定,因为 norms&docvalues无法修改。只能reindex
「秘诀1:混合 精确查询和提取词干(mixing exact search with stemming)」
对于搜索应用,提取词干(stemming)都是必须的。例如:查询 skiing时,ski和skis都是期望的结果
但,如果用户就是要查询skiing呢?
解决方法是:使用multi-field。同一份内容,以两种不同的方式来索引存储 query.simplequerystring.quotefieldsuffix,竟然是 查询完全匹配的
「秘诀2:获取一致性的打分」
score不能重现 同一个请求,连续运行2次,但,两次返回的文档顺序不一致。这是相当坏的用户体验
如果存在 replica,则就可能发生这种事,这是因为:search时,replication group中的shard是按round-robin方式来选择的,因此两次运行同样的请求,请求如果打到 replication group中的不同shard,则两次得分就可能不一致
那问题来了,“你不是整天说 primary和replica是in-sync的,是完全一致的”嘛,为啥打到“in-sync的,完全一致的shard”却算出不同的得分?
原因就是标注为“已删除”的文档。如你所知,doc更新或删除时,旧doc并不删除,而是标注为“已删除”,只有等到 旧doc所在的segment被merge时,“已删除”的doc才会从磁盘删除掉
索引统计(index statistic)是打分时非常重要的一部分,但,由于 deleted doc 的存在,在同一个shard的不同copy(即:各个replica)上 计算出的 索引统计 并不一致
个人理解:
- 所谓 索引统计 应该就是df,即 doc_freq
- 索引统计 是基于shard来计算的
搜索时,“已删除”的doc 当然是 永远不会 出现在 结果集中的 索引统计时,for practical reasons,“已删除”doc 依然是统计在内的
假设,shard A0 刚刚完成了一次较大的segment merge,然后移除了很多“已删除”doc,shard A1 尚未执行 segment merge,因此 A1 依然存在那些“已删除”doc
于是:两次请求打到 A0 和 A1 时,两者的 索引统计 是显著不同的
「如何规避 score 不能重现 的问题?使用 preference 查询参数」
发出搜索请求时候,用标识字符串来标识用户,将标识字符串作为查询请求的 preference参数。这确保多次执行同一个请求时候,给定用户的请求总是达到同一个 shard,因此得分会更为一致(当然,即使同一个 shard,两次请求 跨了 segment merge,则依然会得分不一致)
这个方式还有另外一个优点,当两个 doc 得分一致时,则默认按着 doc 的内部 Lucene doc id 来排序(注意:这并不是es中的 _id 或 _uid)。但是呢,shard 的不同 copy 间,同一个 doc 的内部 Lucene doc id 可能并不相同。因此,如果总是达到同一个 shard,则,具有相同得分的两个 doc,其顺序是一致的
「score错了」
score 错了(Relevancy looks wrong)
如果你发现
- 具有相同内容的文档,其得分不同
- 完全匹配 的查询 并没有排在第一位 这可能都是由 sharding 引起的
- 默认情况下,搜索文档时,每个shard自己计算出自己的得分。
- 索引统计 又是打分时一个非常重要的因素。
如果每个 shard 的 索引统计相似,则 搜索工作的很好
文档是平分到每个 primary shard 的,因此 索引统计 会非常相似,打分也会按着预期工作。但,万事都有个但是:
- 索引时使用了 routing(文档不能平分到每个primary shard 啦)
- 查询多个索引
- 索引中文档的个数 非常少
这会导致:参与查询的各个 shard,各自的 索引统计 并不相似(而,索引统计对 最终的得分 又影响巨大),于是 打分出错了(relevancy looks wrong)
「那,如何绕过 score错了(Relevancy looks wrong)?」
如果数据集较小,则,只使用一个 primary shard(es 默认是5个),这样两次查询 索引统计 不会变化,因而得分也就一致啦
另一种方式是,将 searchtype 设置为:dfsquerythenfetech(默认是querythenfetch)
dfsquerythen_fetch 的作用是
- 向 所有相关 shard 发出请求,要求 所有相关shard 返回针对当前查询的 索引统计
- 然后,coordinating node 将 merge这些 索引统计,从而得到 merged statistics
- coordinating node 要求 所有相关shard 执行 query phase,于是 发出请求,这时,也带上 merged statistics。这样,执行query的shard 将使用 全局的索引统计
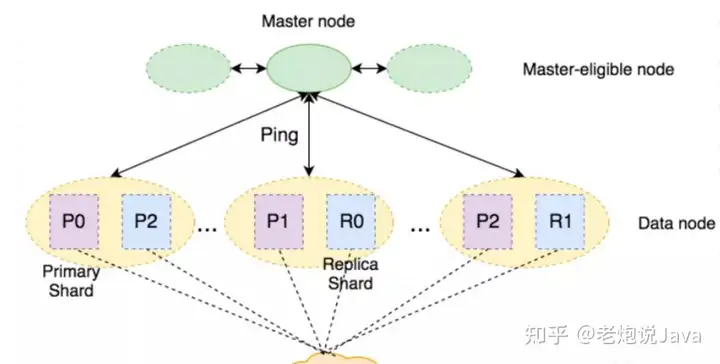
大部分情况下,要求 所有相关 shard 返回针对当前查询的 索引统计,这是非常cheap的。但,如果查询中 包含 非常大量的 字段/term查询,或者有 fuzzy 查询,此时,获取 索引统计 可能并不 cheap,因为 为了得到 索引统计 可能 term dictionary 中 所有的 term 都需要被查询一遍。
英文原文:
https://www.elastic.co/guide/en/elasticsearch/reference/current/how-to.html
[转帖]Elasticsearch 的 30 个调优最佳实践!的更多相关文章
- MySQL参数调优最佳实践
前言很多时候,RDS用户经常会问如何调优RDS MySQL的参数,为了回答这个问题,写一篇blog来进行解释: 哪一些参数不能修改,那一些参数可以修改:这些提供修改的参数是不是已经是最佳设置,如何才能 ...
- SAP专家培训之Netweaver ABAP内存管理和内存调优最佳实践
培训者:SAP成都研究院开发人员Jerry Wang 1. Understanding Memory Objects in ABAP Note1: DATA itab WITH HEADER LINE ...
- 硬菜点播台 | MySQL阿里实践经典案例之参数调优最佳实践
http://mp.weixin.qq.com/s?__biz=MzA4NjI4MzM4MQ%3D%3D&mid=512708319&idx=1&sn=6af5f424d7cd ...
- ElasticSearch 2 (11) - 节点调优(ElasticSearch性能)
ElasticSearch 2 (11) - 节点调优(ElasticSearch性能) 摘要 一个ElasticSearch集群需要多少个节点很难用一种明确的方式回答,但是,我们可以将问题细化成一下 ...
- [数据库]漫谈ElasticSearch关于ES性能调优几件必须知道的事(转)
ElasticSearch是现在技术前沿的大数据引擎,常见的组合有ES+Logstash+Kibana作为一套成熟的日志系统,其中Logstash是ETL工具,Kibana是数据分析展示平台.ES让人 ...
- 漫谈ElasticSearch关于ES性能调优几件必须知道的事
lasticSearch是现在技术前沿的大数据引擎,常见的组合有ES+Logstash+Kibana作为一套成熟的日志系统,其中Logstash是ETL工具,Kibana是数据分析展示平台.ES让人惊 ...
- [svc]centos6系统安装(分区)及其18处调优调优最佳实战
系统下载 在阿里云下载 可以使用最小化的,也可以使用dvd版(CentOS-6.7-x86_64-bin-DVD1.iso),其中dvd版方便安装过程中选包. 一. 系统安装 1,时区选择 2,磁盘分 ...
- Jboss调优——最佳线程数
在设置jboss的参数中,maxThreads(最大线程数)和acceptCount(最大等待线程数)是两个非常重要的指标,直接影响到程序的QPS.本文讲解jboss连接的运行原理,以及如何设置这两 ...
- 翻译 | 30个 Python3 的最佳实践,技巧和窍门
1.使用 Python3 如果你关注 Python 的话,应该会知道 Python 2 已经于今年(2020 年)1 月 1 日正式弃用了.这份教程的很多例子都是只支持 Python 3 的,如果你还 ...
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
随机推荐
- DTT年度收官圆桌π,华为云8位技术专家的年末盘点
摘要:收下这份DTT年度收官圆桌π总结,在新的一年心想事成,技术上更上一层楼. 本文分享自华为云社区<DTT年度收官圆桌π,华为云8位技术专家的年末盘点>,作者:华为云社区精选 . 在20 ...
- 云小课|三大灵魂拷问GaussDB(DWS)数据落盘安全问题
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:GaussDB(D ...
- Solon 1.6.29 发布,轻量级应用开发框架
关于官网 千呼万唤始出来: https://solon.noear.org .整了一个月多了...还得不断接着整! 关于 Solon Solon 是一个轻量级应用开发框架.支持 Web.Data.Jo ...
- JAVA PDF 截取N页,生成新文件,转图片,多个PDF 合并
JAVA PDF 截取N页,生成新文件,转图片,多个PDF 合并 <dependency> <groupId>com.itextpdf</groupId> < ...
- Python openpyxl 将 Excel中的汉字 转换成拼音首字母
将Excel中的汉字列,转换成拼音首字母,并保存 需要安装导入 pypinyin.openpyxl 库 # pip install pypinyin from pypinyin import laz ...
- 断点续传(上传)Java版
PostMan 客户端调用部分见,断点续传(上传)C#版 1. 客户每次上传前先获取一下当前文件已经被服务器接受了多少 2. 上传时设定偏移量,跳过服务器已收到的长度 @SpringBootTest ...
- JMeter 源码解读 - HashTree
背景: 在 JMeter 中,HashTree 是一种用于组织和管理测试计划元素的数据结构.它是一个基于 LinkedHashMap 的特殊实现,提供了一种层次结构的方式来存储和表示测试计划的各个组件 ...
- sqlalchemy union 联合查询
在最近的工作中遇到一个问题,要将两个字段相似的表里的数据统一起来展示在一个统计页面中.如果是单纯的展示数据那很简单,两个表查出来之后组合一下就完事了,但是有坑的地方就是分页和按照时间搜索,这两个功能决 ...
- GOS会计凭证上传附件
1.GOS介绍 GOS是一个连接文档和SAP内各种对象的工具,在SAP的一些凭证中,可以通过GOS进行附件的上传.查看和删除等功能,例如采购订单.会计凭证等. 如果没有这个按钮,可以将当前登录用户的类 ...
- IDEA 2021.2 新建JavaWeb项目及Tomcat部署
前文:JSP 简单入门与 IDEA 开发环境配置 参考链接: https://zhuanlan.zhihu.com/p/68133583 https://www.cnblogs.com/javabg/ ...