知识+AI融合创新探索,华为云论文被AI顶级学术期刊IEEE TPAMI接受
摘要:通过利用物体类别之间存在的层级关系约束,自动学习从数据中抽取识别不同类别的规则,一方面对模型的预测过程进行解释,另一方面也提供了一条引入人工先验知识的可行途径。
前言
受益于深度学习技术的突破,图像分类、物体检测等传统计算机视觉任务的精度也得到了大幅度的提升。但是由于深度学习模型的复杂性,目前关于深度学习的理论并不完善,这就导致了两大问题:第一,模型的工作机制对使用者来说并不透明,人们无法解释模型识别正确或错误的原因,因此也就无法从理论上证明模型在实际应用中是否能够达到好的效果,从而在一定程度上阻碍了模型在一些性命攸关的领域中应用(如医疗影像分析、自动驾驶等);第二,几乎完全基于数据驱动的方式学习模型参数,难以将人们长期以来总结形成的经验和知识融入模型,从而难以对模型学习过程施加有效的约束,使模型在小训练样本、零训练样本等真实条件下的精度远低于人类。
人工智能领域顶级学术期刊IEEE Transactions on Pattern Analysis and Machine Intelligence(即IEEE TPAMI,影响因子17.861)最近接收的论文“What is a Tabby? Interpretable Model Decisions by Learning Attribute-based Classification Criteria“中,华为云联合中科院计算所,针对上述两个问题提出了一种探索性的解决方案,通过利用物体类别之间存在的层级关系约束,自动学习从数据中抽取识别不同类别的规则,一方面对模型的预测过程进行解释,另一方面也提供了一条引入人工先验知识的可行途径。
首先,我们通过一组简单的例子来看一下分类学家是如何对动物进行分类的(来自维基百科):
- “虎斑猫”是一种体表有条纹、斑点、线条、螺旋图案的“家猫”。
- “家猫”是一种小型的、通常体表有皮毛的、肉食性的、被驯化的“猫科动物”;
- “猫科动物”是一种具有伸缩自如的爪子、苗条但肌肉强健的躯体、灵活的前肢的“食肉动物”。
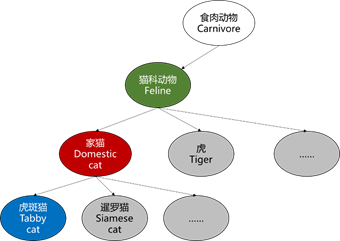
图1. 类别层级结构示意
从上边的例子可以看出来,分类学家在对动物进行分类的时候,采用了一种层级化的方式,在层级中,每个类别都被表示成“父类 + 一些特定属性”的形式,比如有条纹、有斑点、有线条、有螺旋,就是“虎斑猫”相比它的父类“家猫”多出来的属性。
实际上,如果对层级做一些压缩操作,每个类别都可以完全用一组特定属性来表示。以“虎斑猫”这个类别为例,经过一级压缩:“虎斑猫”是一种小型的、肉食性的、被驯化的、体表有带条纹、斑点、线条、螺旋图案皮毛的“猫科动物”。可以看到,经过一级压缩后,“虎斑猫”就可以通过“父类的父类 + 更多的属性”来表示了。更进一步,如果经过两级压缩:“虎斑猫”是一种小型的、肉食性的、被驯化的、具有伸缩自如的爪子、苗条但肌肉强健的躯体、灵活的前肢的、体表有带条纹、斑点、线条、螺旋图案皮毛的“食肉动物”。可以看到,经过两级压缩后,“虎斑猫”就可以通过“父类的父类的父类 + 更多的属性”来表示了。
以此类推,如果一直将这个压缩的过程进行下去,“虎斑猫”就可以通过“动物 + 虎斑猫具有的全部属性” 这种方式来表示了。对于其他动物来说,也是类似的,每种动物都可以表示为“动物 + 这种动物具有的全部属性”。由于每种动物的表示中都含有“动物”这个公共的组成部分,可以将每种动物的表示形式都简化为“这种动物具有的全部属性”。类似的,对于“植物”、“人造物”等等所有物体,都可以完全用一组属性来表示。因此,只要属性定义足够好,完全通过属性就可以准确地区分出来所有可能见到的类别,并且这种分类方式的可解释性非常好,也可以轻松地将新的人工先验知识引入进来。
但是实际中,由于类别数量巨大、海量属性难以定义,不可能通过人工的方式对每个类别的属性进行定义。那么有什么方法可以在不对数据进行额外标注的情况下实现类似的分类方式呢?
方法介绍
事实上,上面的推理过程给我们提供了两点重要的洞察:第一,当属性足够多、足够好的时候,属性可以用来准确地区分不同的类别;第二,每个类别具有的属性数量一定比它的父类多。针对第一点洞察中对于属性数量和质量的要求,近期的研究[1, 2, 3]表明,以图像分类任务训练的深度学习模型可以自发地学习到一些具有语义的属性,因此通过这种方式,可以不再需要人工定义属性,仅通过算法自动学习的方式来得到足够多、足够好的属性;针对第二点洞察中对于类别间的约束关系的要求,可以将这样的类别间关系进行形式化,指导算法学习属性的过程,使学习到的属性满足约束条件。这样一来,就既解决了属性难定义、难标注的问题,又保留了基于属性进行分类的方案在高可解释性和便于引入人工先验知识方面的优势。
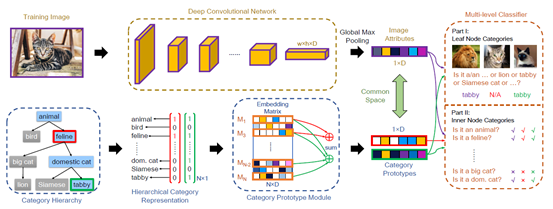
图2. 方法框架示意图
具体来说,作者在提出的方法中设计了一个包含两条分支的模型,如图2所示。上边的分支以图像作为输入,主要作用是学习属性;下边的分支以层级结构作为输入,主要作用是对学习属性的过程施加约束:
其中上边的分支使用常见的卷积神经网络backbone,上边分支的输出是一个1×D维的“属性向量”,向量中的每一维表示一个属性,每一维的值则表示图像样本是否具有这个属性(0表示样本不具有这个属性,大于0的值表示样本具有这个属性),同时当激活值大于0时,激活值的大小表示图像样本在这个属性上的强度;

训练时,损失函数的目标是要求两个分支的输出都能够正确的预测D维特征对应的最细粒度类别和对应的粗粒度类别。通过这种方式,上边的分支就可以学习到D个对于分类任务来说有用的属性,而下边的分支则可以保证这D个属性满足类别间属性数量关系的约束,从而可以对模型分类原理给出人类可以理解的解释。
取得的效果
论文中,作者在CIFAR-100和ILSVRC两个大规模的层级数据库上进行了实验,通过大量的实验验证了方案的有效性:
1、分类精度
从实验结果来看,尽管论文提出的方法针对提高模型的可解释性和提高引入人工先验知识的便捷程度做了大量的设计,但是在分类精度上仍然达到了SOTA的水平,表明该方案在实际业务中具有实用价值。
2、属性学习效果
定性展示结果方面,作者通过可视化的方式展示了模型学习到的属性,实验结果中针对每个属性,通过展示每个属性在数据集上响应值最大的9个图像块来表示属性,如图3所示。从图中看,模型学习到了大量不重复的、有意义的属性,并且既有比较简单的纹理、形状(dotted、round等)属性,也有语义性更强的车轮、山等属性。

图3. 算法学习到的属性展示。(a)CIFAR-100数据库上学习到的属性;(b)ILSVRC数据库上学习到的属性
从定量评测的结果来看,在包含1000个类别的ILSVRC数据上,模型学习到了2600多个属性,远超基线模型(标准ResNet-50分类模型)的2000个属性;在去除重复属性(可能包含了同种属性的不同情况)后,论文方法学到的属性数量接近140个,多于基线模型的120余个不重复的属性。

图4. 模型学习到的属性数量的定量评估结果
针对属性响应区域的可视化结果(图5)也显示,模型学到的属性基本上是可靠的。图中响应最强的区域(红色部分)也正是和属性对应的区域。

图5. 属性响应区域可视化
3、规则学习结果和人工先验引入
实验中,作者展示了模型下边的分支学习到的分类规则,将每个类别表示成“父类 + 特定属性组合”的形式,如图6所示。模型学习到的结果中包括:
- “钟表”是一种圆形的、放射状的“家用电子设备”;
- “猎豹”是一种有条纹、斑点的“猫科动物”;
- “足球”是一种在白色背景上有黑色斑点的“球”。
模型给出的解释规则基本符合人的认知,表明模型可以学到类似于分类学家定义的“父类 + 特定属性组合”形式的分类规则,可以对模型的分类原理给出人类可理解的解释。

(a)

(b)
图6. 模型学习到的解释规则展示。(a)CIFAR-100数据库上学习到的解释规则;(b)ILSVRC数据库上学习到的解释规则
相比之下,现有方法[4]如果想要给出同样形式的解释结果,需要人工标注每个类别的属性表示,而这在大规模场景下显然是不现实的,作者在实验中也展示了相应的对比结果(表1),从对比结果来看,论文中提出方法的适用范围显然更广泛。
表1. 与现有方法[4]对比

有了上边这种人类可以理解的解释规则,就可以对模型进行定制化的调优,去除模型不应该利用的规则,补充模型没有学习到的规则:
在ILSVRC数据的“救护车”和“猎豹”两个类别上尝试了去除模型学到的错误规则的方案,该方案在基本不影响其他类别识别效果的前提下,可以提升模型在“救护车”和“猎豹”两个类别上的识别精度;
在同一个数据库的全部类别上,作者尝试了补充额外属性的方案,并得到了约2个百分点精度提升。
上边两个实验表明,作者提出的方法虽然只是在深度模型引入人工先验方面做了一些初步的探索,但是已经验证了深度模型和人工先验知识结合的有效性,并且给出了一条基本可行的技术路线。
结论
可解释的深度学习模型,以及深度学习模型与人工先验的结合是当前学术界重点研究的前沿方向,对于提升深度学习模型的可靠性和泛化能力具有重要的意义。这次介绍的论文同时在这两个方向上迈出了坚实的一步:在可解释深度学习模型方面,相比于现有方法,不仅能够给出图像中的关键区域,还能给出规则化的解释,对使用者更友好,更符合人对于解释结果的期望;在引入人工先验知识方面,走通了一条基本可行的技术路线,希望能够对未来的研究者有所启发。上华为云AI Gallery,开发者可以了解更多华为云算法能力,用华为云ModelArts平台进行训练和推理。
参考文献
[1] C. Huang, C. C. Loy, and X. Tang, “Unsupervised learning of discriminative attributes and visual representations,” in Computer Vision and Pattern Recognition (CVPR), 2016, pp. 5175–5184.
[2] V. Escorcia, J. C. Niebles, and B. Ghanem, “On the relationship between visual attributes and convolutional networks,” in Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1256–1264.
[3] S. Vittayakorn, T. Umeda, K. Murasaki, K. Sudo, T. Okatani, and K. Yamaguchi, “Automatic attribute discovery with neural activations,” in European Conference on Computer Vision (ECCV), 2016, pp. 252–268.
[4] S. J. Hwang and L. Sigal, “A unified semantic embedding: Relating taxonomies and attributes,” in Advances in Neural Information Processing Systems (NIPS), 2014, pp. 271–279.
https://marketplace.huaweicloud.com/markets/aihub/modelhub/list/?utm_source=bbs-ex&utm_medium=pr-huaweiyun&utm_campaign=ei&utm_content=content-20210304-1-bbs-ex
本文分享自华为云社区《华为云IEEE TPAMI论文解读:规则化可解释模型助力知识+AI融合》,原文作者:HWCloudAI 。
知识+AI融合创新探索,华为云论文被AI顶级学术期刊IEEE TPAMI接受的更多相关文章
- 顶会两篇论文连发,华为云医疗AI低调中崭露头角
摘要:2020年国际医学图像计算和计算机辅助干预会议(MICCAI 2020),论文接收结果已经公布.华为云医疗AI团队和华中科技大学合作的2篇研究成果入选. 同时两篇研究成果被行业顶会收录,华为云医 ...
- 沈抚示范区·“华为云杯”2021全国AI大赛圆满落
摘要:以赛促学,赛教结合!驱动AI产业繁荣发展 本文分享自华为云社区<云聚沈抚 · 智赢未来!沈抚示范区·"华为云杯"2021全国AI大赛圆满落幕>,作者:灰灰哒. 近 ...
- 华为云ModelArts 2.0全面升级,革新传统AI开发模式
[中国,上海,9月20日] 在HUAWEI CONNECT 2019期间,华为云EI服务产品部总经理贾永利宣布--华为云AI重装升级,并重磅发布一站式AI开发管理平台ModelArts 2.0. 现场 ...
- AI本质就是“暴力计算”?看华为云如何应对算力挑战
随着AI人工智能技术的飞速发展,相关的AI应用场景已经拓宽至各行各业.你可能想象不到的是,现在大家手上的智能手机的运算能力,甚至比美国航空航天局1969年登月计划中最先进计算机还高出几百上千万倍乃至更 ...
- 华为全栈AI技术干货深度解析,解锁企业AI开发“秘籍”
摘要:针对企业AI开发应用中面临的痛点和难点,为大家带来从实践出发帮助企业构建成熟高效的AI开发流程解决方案. 在数字化转型浪潮席卷全球的今天,AI技术已经成为行业公认的升级重点,正在越来越多的领域为 ...
- 华为云ModelArts2.0来袭
[摘要] modelarts自发布以来,不断地更新增加新的功能来为AI工程师们带来新的服务,在这次的全联接大会上EI服务产品部总经理贾永利宣布--华为云AI重装升级,并重磅发布一站式AI开发管理平台M ...
- 升级的华为云“GaussDB”还能战否?
摘要:芯片.操作系统.数据库是现代信息技术领域的三大核心基础,做数据库,不仅需要技术和投入,对华为这种做通讯起家的企业,更需要的是一种并非玩票性质的态度. GaussDB,不仅蕴含着华为对数学和科学的 ...
- 分析师机构发布中国低代码平台现状分析报告,华为云AppCube为数字化转型加码
摘要:Forrester指出,中国企业数字化转型过程中,有58%的决策者正在采用低代码工具进行软件构建,另有16%的决策者计划采用低代码. 华为消息,知名研究与分析机构Forrester Resear ...
- 揭秘华为云GaussDB(for Influx)最佳实践:hint查询
摘要:GaussDB(for Influx)通过提供hint功能,在单时间线的查询场景下,性能有大幅度的提升,能有效满足客户某些特定场景的查询需求. 本文分享自华为云社区<华为云GaussDB( ...
- 揭秘华为云GaussDB(for Influx):数据直方图
摘要:本文带您了解直方图在不同产品中的实现,以及GaussDB(for Influx)中直方图的使用方法. 本文分享自华为云社区<华为云GaussDB(for Influx)揭秘第九期:最佳实践 ...
随机推荐
- 使用 DDPO 在 TRL 中微调 Stable Diffusion 模型
引言 扩散模型 (如 DALL-E 2.Stable Diffusion) 是一类文生图模型,在生成图像 (尤其是有照片级真实感的图像) 方面取得了广泛成功.然而,这些模型生成的图像可能并不总是符合人 ...
- Docker磁盘&内存&CPU资源实战
Docker 资源实战:cpu/内存配置: #查看帮助 docker run --help docker update --help #配置容器使用cpu /内存大小--privileged 给与容器 ...
- 未能添加SSL证书,错误1312
1.win+r打开运行,输入mmc 2.在控制台1[控制台根节点]->文件->添加/删除....->选择证书->添加-选择计算机账户->完成->确认 3.找到证书文 ...
- pta乙级1033(C语言)散列表解法
#include"stdio.h" #include"string.h" int main() { int flag=1; char w[100010],ch[ ...
- 阿里Java一面,难度适中!(下篇)
上一次因为文章篇幅和个人精力有限的原因,只分享了淘天的前 6 道题及其答案(点击访问上一篇).接下来,咱们把其他几道题面试题及答案也分享给大家. 1.公司简介 淘天集团就是"淘宝" ...
- baby_web
点开页面获得提示 根据提示,访问index.php,但是会自己跳转到1.php 这时候抓包修改才ok才能定位到index.php
- 【PySide6】QChart笔记(三)—— QPieSeries的使用
一.QPieSeries简介 1. 官方描述 https://doc.qt.io/qtforpython-6/PySide6/QtCharts/QPieSeries.html 一个饼图序列(QPieS ...
- EF Core预编译模型Compiled Model
前言 最近还在和 npgsql 与 EF Core 斗争,由于 EF Core 暂时还不支持 AOT,因此在 AOT 应用程序中使用 EF Core 时,会提示问题: 听这个意思,似乎使用 Compi ...
- python计算代码运行时间
记录一下自己用python编写计算运行时间的代码 时间类 import time import numpy as np # 编写时间类来方便操作 class Timer: def __init__(s ...
- 请查收,本周刷屏的两大热点「GitHub 热点速览」
如果你逛 HackerNews 或者是推特,你一定会被 multipleWindow3dScene 这个跨窗口渲染项目的成果刷屏,毕竟国内的技术平台上也出现了不少的模仿项目.另外一个热点,便是你在白板 ...