论文解读(ECACL)《ECACL: A Holistic Framework for Semi-Supervised Domain Adaptation》
Note:[ wechat:Y466551 | 付费咨询,非诚勿扰 ]
论文信息
论文标题:ECACL: A Holistic Framework for Semi-Supervised Domain Adaptation
论文作者:Kai Li, Chang Liu, Handong Zhao, Yulun Zhang, Y. Fu
论文来源:2021 ICCV
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
出发点:半监督领域自适应(SSDA)是一个实用但尚未被研究的研究课题;
2 方法
2.1 模型框架
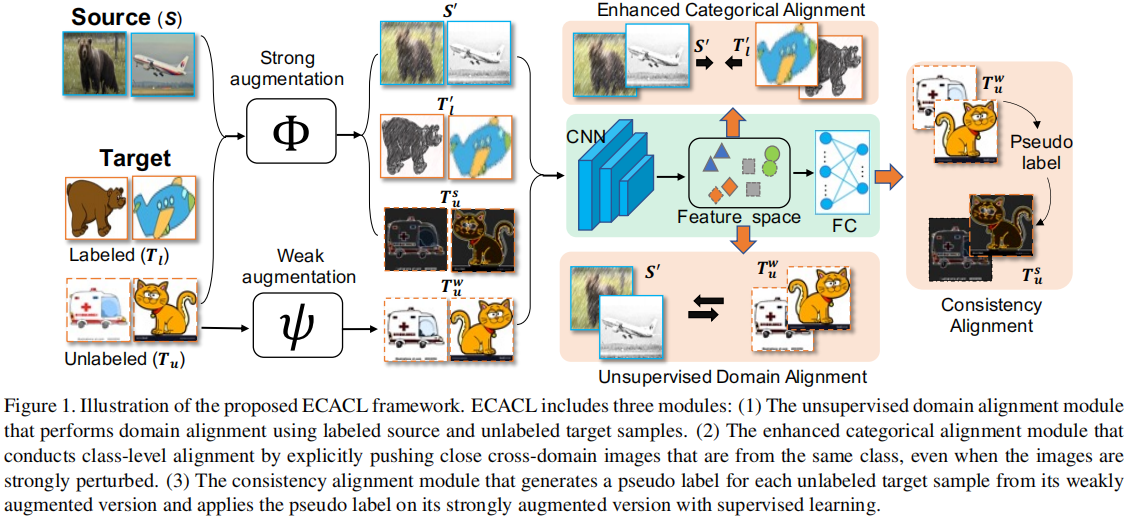
2.2 类对齐
基于原型损失的方法
使用目标域带标记数据计算原型:
$\mathbf{c}_{k}=\frac{1}{\left|\mathcal{T}_{k}\right|} \sum_{\left(\mathbf{t}_{i}, y_{i}\right) \in \mathcal{T}_{k}} f\left(\mathbf{t}_{i}\right) \quad\quad(1)$
使用上述得到的目标原型,计算源域样本原型分布:
$p\left(y_{i}^{s}=y \mid \mathbf{s}_{i}\right)=\frac{\exp \left(-\left\|f\left(\mathbf{s}_{i}\right)-\mathbf{c}_{y}\right\|_{2}\right)}{\sum_{k=1}^{C} \exp \left(-\left\|f\left(\mathbf{s}_{i}\right)-\mathbf{c}_{k}\right\|_{2}\right)}\quad\quad(2)$
然后,可计算出所有源样本的原型损失:
$L_{p a}=\frac{1}{C N_{s}} \sum_{\left(\mathbf{s}_{i}, y_{i}^{s}\right) \sim \mathcal{S}} \sum_{y \sim \mathcal{Y}} y_{i}^{s} \log \left[-p\left(y_{i}^{s}=y \mid \mathbf{s}_{i}\right)\right] \quad\quad(3)$
基于三重损失的方法
目的:使同一类的跨域样本应该比来自不同类[16]的样本具有更高的相似性。
具体来说,对于目标域带标记样本 $\left(\mathbf{t}_{i}, y_{i}^{t}\right) \in \mathcal{T}_{l}$,从 $\mathcal{S}$ 中发现属于 $y_t$ 类,但最不相似的源样本 $\left(\mathbf{s}_{p}, y_{p}\right)$。同时,也从 $\mathcal{S}$ 中找到不属于 $y_t$ 类,但最相似的样本 $\left(\mathbf{s}_{n}, y_{n}\right)$。三联体 $\left(\mathbf{t}_{i}, \mathbf{s}_{n}, \mathbf{s}_{p}\right)$,将以下三联体损失优化为:
$\begin{aligned}L_{t a}= & \frac{1}{N_{t}} \sum_{\left(\mathbf{t}_{i}, y_{t}\right) \sim \mathcal{T}_{l}}\left[\left\|f\left(\mathbf{t}_{i}\right)-f\left(\mathbf{s}_{p}\right)\right\|_{2}^{2}-\right.\left.\left\|f\left(\mathbf{t}_{i}\right)-f\left(\mathbf{s}_{n}\right)\right\|_{2}^{2}+m\right]_{+} \end{aligned}\quad\quad(4)$
2.3 域对齐与数据增强
增强的类对齐
最近的研究表明,创建高度扰动图像的强增强为监督学习[6,7]带来了显著的性能提高。因此,$\text{Eq.1-4}$ 均基于随机强数据增强样本计算得出。
一致性对齐
对于每个未标记的目标样本 $\mathbf{u}_{i} \in \mathcal{T}_{u}$,应用弱增强 $\psi$ 和强增强 $\Phi$:
$\begin{aligned}\mathbf{u}_{i}^{w} & =\psi\left(\mathbf{u}_{i}\right)\\\mathbf{u}_{i}^{s} & =\Phi\left(\mathbf{u}_{i}\right)\end{aligned}\quad\quad(5)$
优化以下目标函数:
$L_{\text {cona }}=\sum_{\mathbf{u}_{i} \sim \mathcal{U}}\left[\mathbb{1}\left(\max \left(\mathbf{p}_{w}\right) \geq \sigma\right) H\left(\tilde{\mathbf{p}}_{w}, \mathbf{p}_{s}\right)\right]\quad\quad(6)$
其中,$\tilde{\mathbf{p}}_{w}= \arg \max \left(\mathbf{p}_{w}\right) $,$H(., . )$ 代表着交叉熵;
2.4 训练目标
总体学习目标是 UDA损失、增强的类对齐损失和一致性对齐损失的加权组合:
$L=L_{\text {uda }}+\lambda_{1} L_{\text {cata }}+\lambda_{2} L_{\text {cona }}, \quad L_{\text {cata }}=\left\{L_{p a}^{\prime}, L_{\text {ta }}^{\prime}\right\}$
其中,$L_{c a t a}=L_{p a}^{\prime}$ 或者 $L_{\text {cata }}=L_{t a}^{\prime} $;
算法:

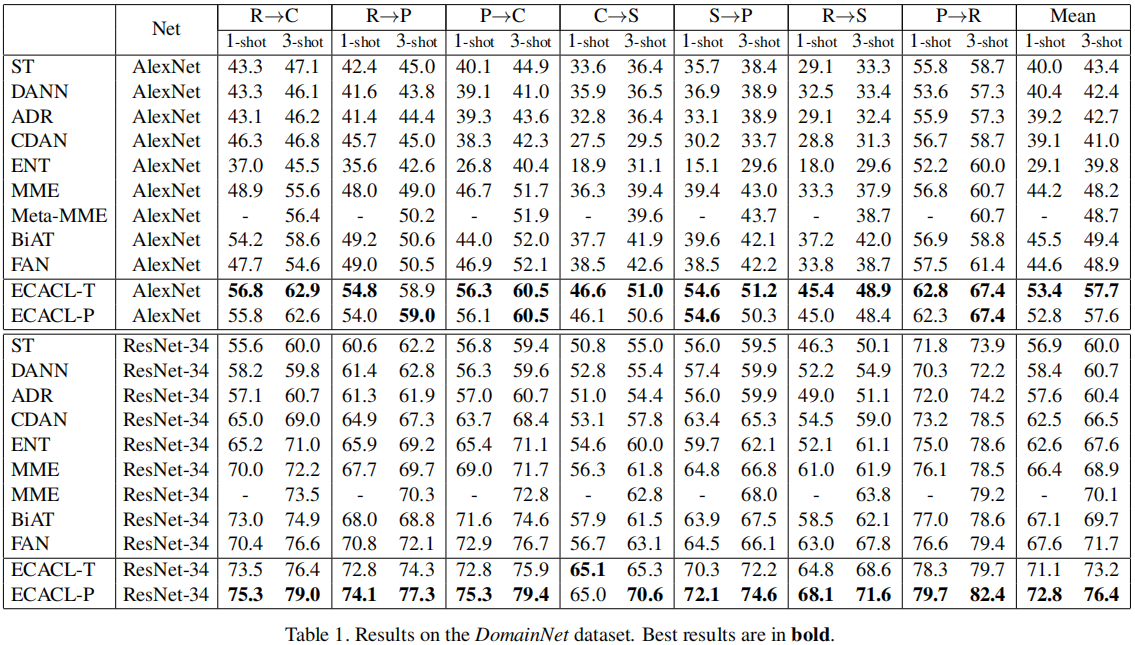
3 实验
分类
论文解读(ECACL)《ECACL: A Holistic Framework for Semi-Supervised Domain Adaptation》的更多相关文章
- 论文解读(PCL)《Probabilistic Contrastive Learning for Domain Adaptation》
论文信息 论文标题:Probabilistic Contrastive Learning for Domain Adaptation论文作者:Junjie Li, Yixin Zhang, Zilei ...
- 论文解读(SimGRACE)《SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation》
论文信息 论文标题:SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation论文作者: ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- 论文解读(SDNE)《Structural Deep Network Embedding》
论文题目:<Structural Deep Network Embedding>发表时间: KDD 2016 论文作者: Aditya Grover;Aditya Grover; Ju ...
- 论文解读(IDEC)《Improved Deep Embedded Clustering with Local Structure Preservation》
Paper Information Title:<Improved Deep Embedded Clustering with Local Structure Preservation>A ...
- 论文解读(KP-GNN)《How Powerful are K-hop Message Passing Graph Neural Networks》
论文信息 论文标题:How Powerful are K-hop Message Passing Graph Neural Networks论文作者:Jiarui Feng, Yixin Chen, ...
- 论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
论文信息 论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data论文作者:Qi Zhu, ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
随机推荐
- PLSQL一些常用的知识点
1.背景 此处简单的记录一下在 oracle中如何使用plsql语法,记录一些简单的例子,防止以后忘记. 2.变量的声明 declare -- 声明变量 v_name varchar2(20); -- ...
- distribute by在spark中的一些应用
一.在二次排序当中的应用 1.1 说到排序当然第一想到的就是sort by和order by这两者的区别,也分情况. 在算子当中,两者没有区别,orderby()调用的也是sort.order by就 ...
- Could not resolve com.android.tools.lint:lint-kotlin:26.2.0.
好久没有使用weexplus publish android 打包apk, 今一运行失败了,提示Could not resolve com.android.tools.lint:lint-kotlin ...
- python学习框架
Python简介与安装 Python的历史与特点 Python的安装与配置 Python基础语法 变量与数据类型 运算符与表达式 控制结构(条件判断与循环) 函数与模块 错误处理与异常 Python数 ...
- shell编程-发送消息
需求:利用 Linux 自带的 mesg 和 write 工具,编写一个向用户快速发送消息的脚本,输入用户名作为第一个参数,消息内容为第二个参数.脚本需要检测用户是否登录,是否打开消息功能,以及当前发 ...
- x.ai还是OpenAI?埃隆·马斯克的AI帝国【2】
上期内容咱们提到了埃隆马斯克的特斯拉是自动驾驶领域的领导者,大家可能近些年也都有从各类渠道听到过Tesla自动驾驶有关的新闻.不同于像包括Google子公司Waymo在内的大多数使用激光雷达来实现自动 ...
- 深入剖析创建Java虚拟机的实现方法
经过前文<深入剖析java.c文件中JavaMain方法中InitializeJVM的实现>的分析,找到了创建Java虚拟机具体实现的方法Threads::create_vm((JavaV ...
- CF1817E Half-sum
题意 有一个大小为 \(N\) 的非负整数集合 \(A\),每次你可以从集合中取任意两个数,并将它们的平均数放回序列.不停操作,知道集合最后剩下两个数.请求出这两个数的差的绝对值的最大值对 \(10^ ...
- 全志G2D实现屏幕旋转,开机logo实现手动旋转。
产品设计出来之后啊,大家使用的时候觉得反过来使用更加便捷.但是屏幕显示是反的.那怎么办那????? 修改硬件费时费工,那能否软件实现那????? 如果纯软件使用那就太费系统资源了.于是就想到了使用全志 ...
- 自然语言处理 Paddle NLP - 基于预训练模型完成实体关系抽取
自然语言处理 Paddle NLP - 信息抽取技术及应用 重点:SOP 图.BCEWithLogitsLoss 基于预训练模型完成实体关系抽取 信息抽取旨在从非结构化自然语言文本中提取结构化知识,如 ...