[oeasy]python0048_注释_comment_设置默认编码格式
- 使用了版本控制 git
- 制作备份
- 进行回滚
- 尝试了 嵌套的控制结构
- 层层 控制
- 不过
- 除非 到不得以
- 尽量不要 太多层次的嵌套
- 这样
- 从顶到底
- 含义 明确
- 而且 还扁平
- 扁平 也能
- 含义明确
- 还可以 做点什么?
- 让程序含义 更加明确呢?
- 其实我们见过注释
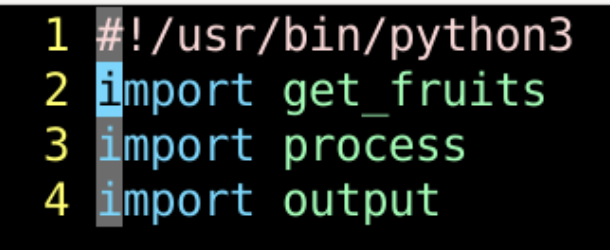
- #号开头的 注释
- 颜色 和其他语句 不一样
- 不会 被python3解释执行
- 凡是 #开头的行
- 都是
- 注释语句
- 不会 被执行
- 除了
- 行首 注释之外
- 行中 是否可以有注释呢?
- 试试
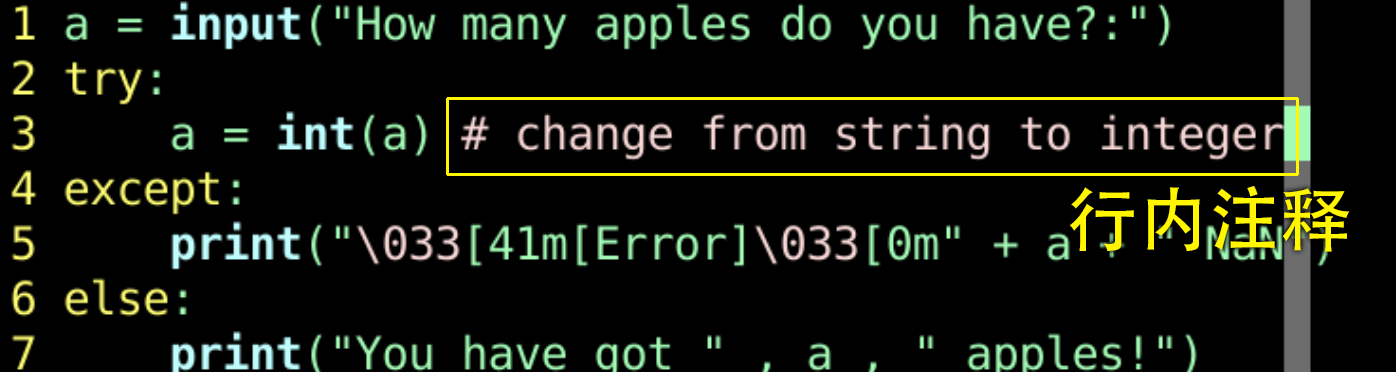
- #号 后面的变颜色的部分
- 就是注释了
- 如果注释在字符串里面呢?
- 在字符串中的 #(Pound,井号)
- 可以试试
- 结论是
- #号 是字符串中的字符
- 不会被当做注释
- 为什么 井号 代表注释呢?
- 历史悠久
- 从纯数字键盘时代
- 就开始使用井号键了

- 这个井号是从什么时候有的呢?
- 来自罗马的质量计量单位
- libra pondo
- 缩写形式 为了区别于 1p
- 写作 ℔
- 读作 pound weight
- 后来演化成了 // 和 = 的组合
- #`

- # 在文本中被标记为 数字符号
- 比如说 1#302中
- #是数字标记
- # 被 1893年的 Blickensderfer 5 留存下来
- 并且明确作为数字标记使用

- 后来#号 顺利进入ascii字符集
- #的 各个含义
- 也有了独立的字符

- 各个独立字符
- 2114 ℔ l b bar symbol
- 2116 № numero sign
- 2317 ⌗ viewdata square
- 266F ♯ music sharp sign
- 29E3 ⧣ equals sign and slanted parallel
- 不过程序员对于#有独立的叫法
- 英国 管# 叫做 'hash'
- 来自于 hatch
- 来自于 cross-hatching
- 交叉排线
- 程序员
- 沿用了这个读法
- #!
- "hash, bang"
- "shebang"
- 网络时代
- #又有了新的含义
- 可以挂接的主题词
- hashtag

- 注释还有什么用处呢?
- 编写的py文件 都是二进制的文件
- 如果 不进行编码格式说明的话
- 怎么知道 应该用什么 编码格式打开 呢?
- test.py 应该
- 用gb2312打开
- 还是utf-8的方式打开?
- 这是一个很现实的问题!
- 这个问题在 pep263 中的有描述
- 这三种都是可以接受的解码方式定义
- # encoding= utf-8
- 直接给的等号赋值
- # -*- coding: utf-8 -*-
- emcas也能识别的
- #vim:set fileencoding = utf-8
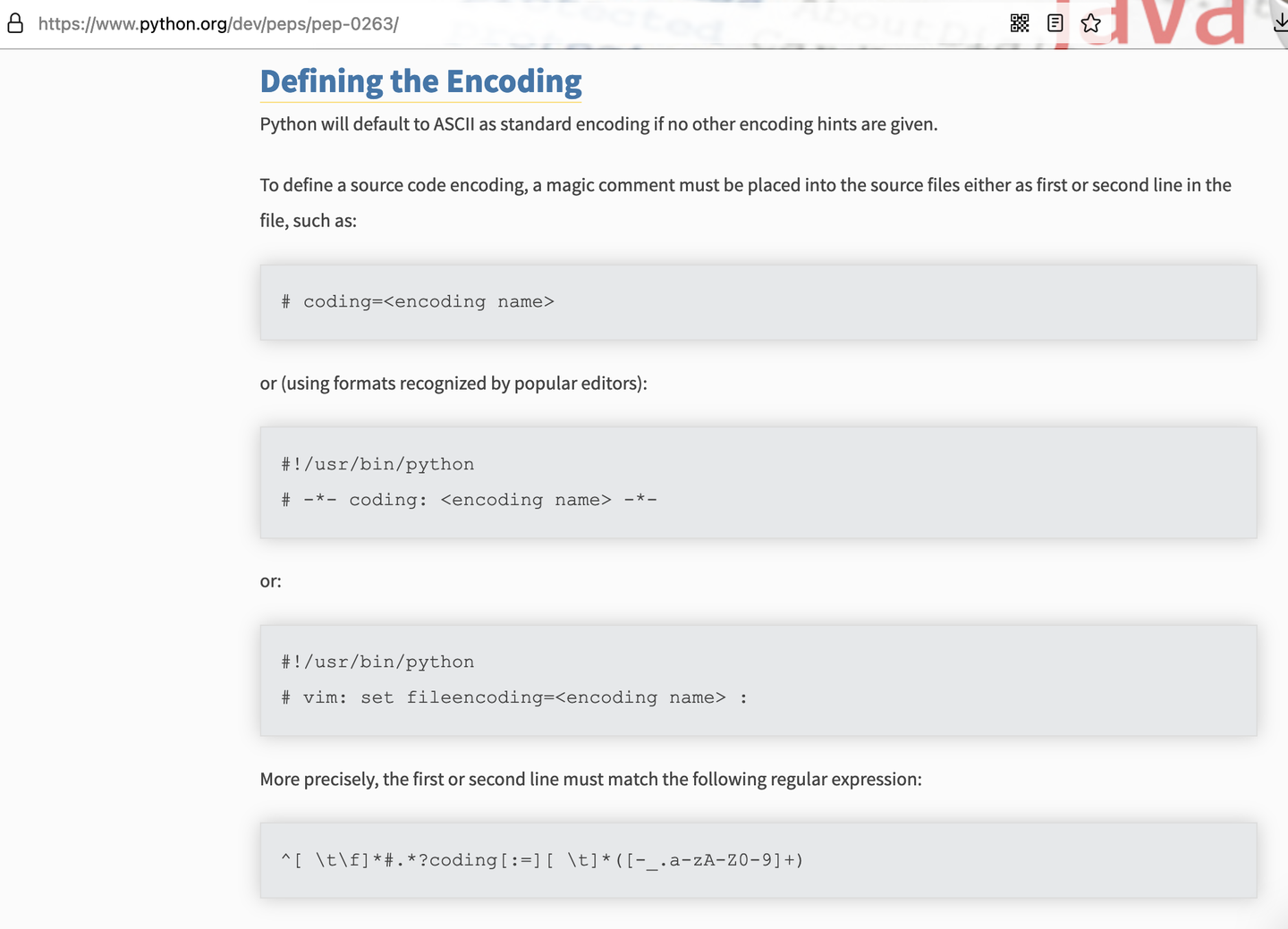
- 第四种是关于解码方式的正则表达式
- ^[ \t\f]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)
- https://regexper.com/?#%5E%5B%20%5Ct%5Cf%5D%23.coding%5B%3A%3D%5D%5B%20%5Ct%5D*%28%5B-_.a-zA-Z0-9%5D%2B%29
- 上面三种写法都可以匹配这个正则表达式
- 这正则表达式应该如何理解?
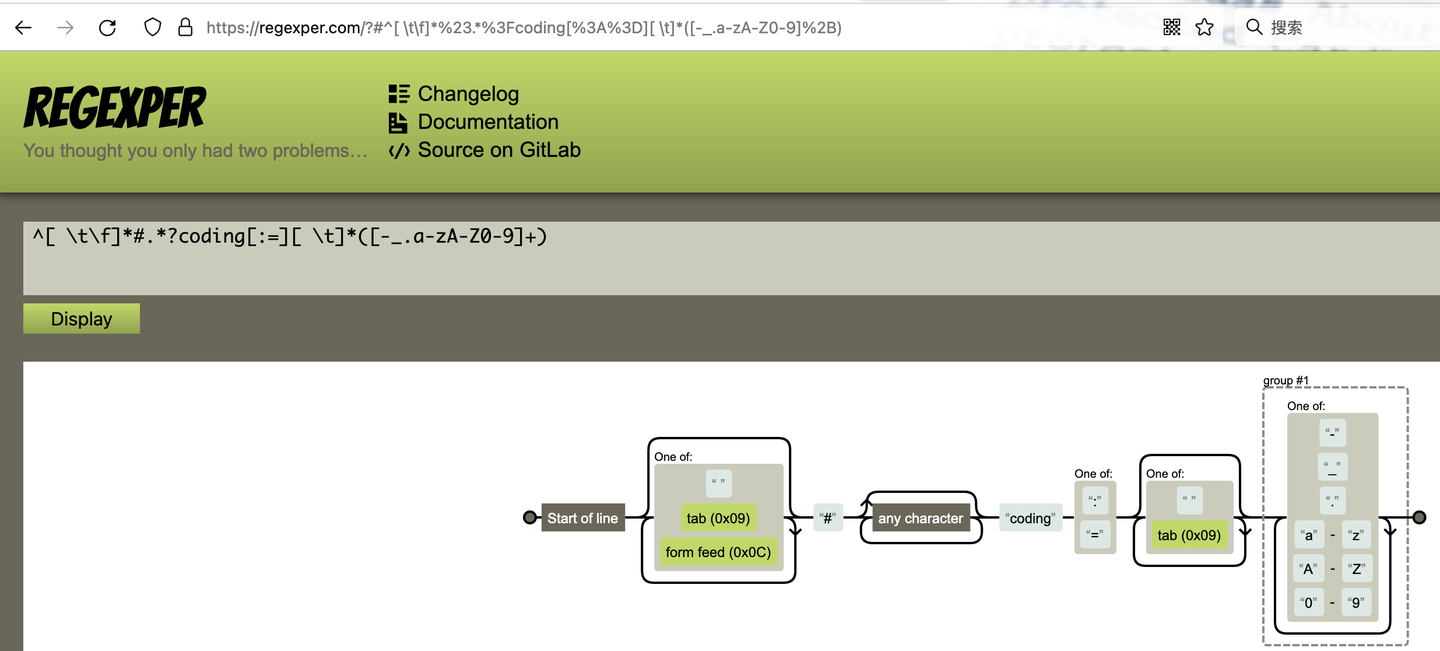
- 注意下图中的第二行
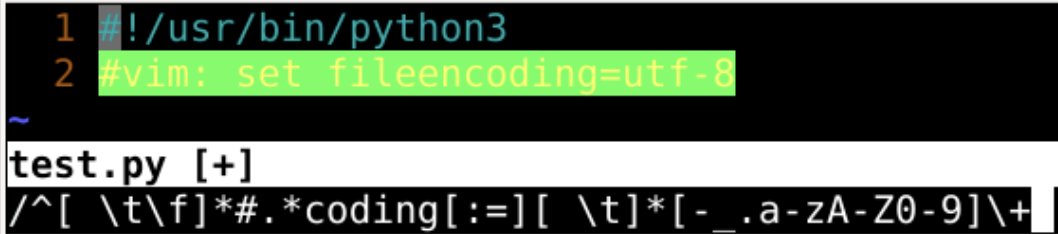
- ^[ \t\f]*#.*coding[:=][ \t]*[-_.a-zA-Z0-9]\+
- 可以匹配到第二行
- ^ 行开头
- [ \t\f]* 前面可以有空格、tab或者换页符若干个
- # 有个# 在python语言中可以理解为本行为注释行
- .*? 后面接着任意长度的任意字符
- coding[:=] 存在code: 或者 code=
- [ \t]* 有0到任意多个空格或tab
- [-_.a-zA-Z0-9]\+ 由中划线、下划线、点、大写小写数字若干组成的标识符
- ^[\t\v]_#._?coding[:=][\t]\*([-_.a-zA-Z0-9]+)
- ([-_.a-zA-Z0-9]+)
- 小括号中 匹配到的
- 就是编码格式的名称
- 比如utf-8
- 而且这种写法同时
- 也设置了vim的打开方式
- encoding 经典定义
- 第一句
- 是告诉 shell 的
- 用哪个二进制文件 打开这个当前文件
- 第二句
- 不但 规定了 python3 解释 运行源文件的编码格式 是utf-8
- 而且 还设置了 vim 的对于此文件
- 打开与保存的编码格式是utf-8
- 如果我定义一个
- python解释器都不认识的编码格式
- 会如何?
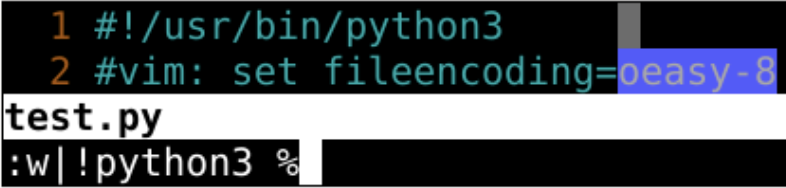
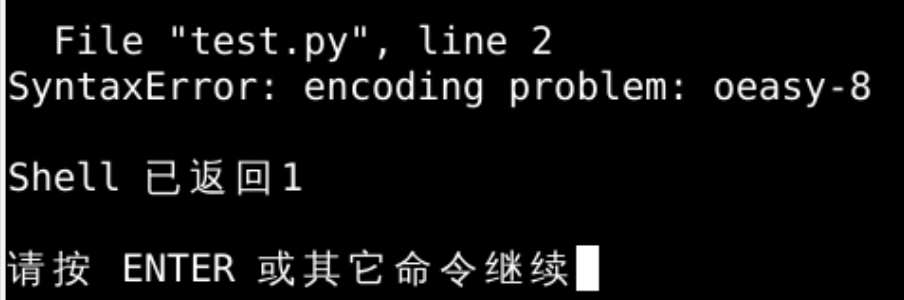
- 解释器感到很困惑
- 哈哈哈
- 虽然注释不用被执行
- 但是作用很大啊!
- 除此之外注释还可以怎样用么呢?
- 原来 用#时
- 都是单行注释
- 现在 有
- 多行注释
- 用三个引号
- 就可以 做多行注释
- 单双引号都可以
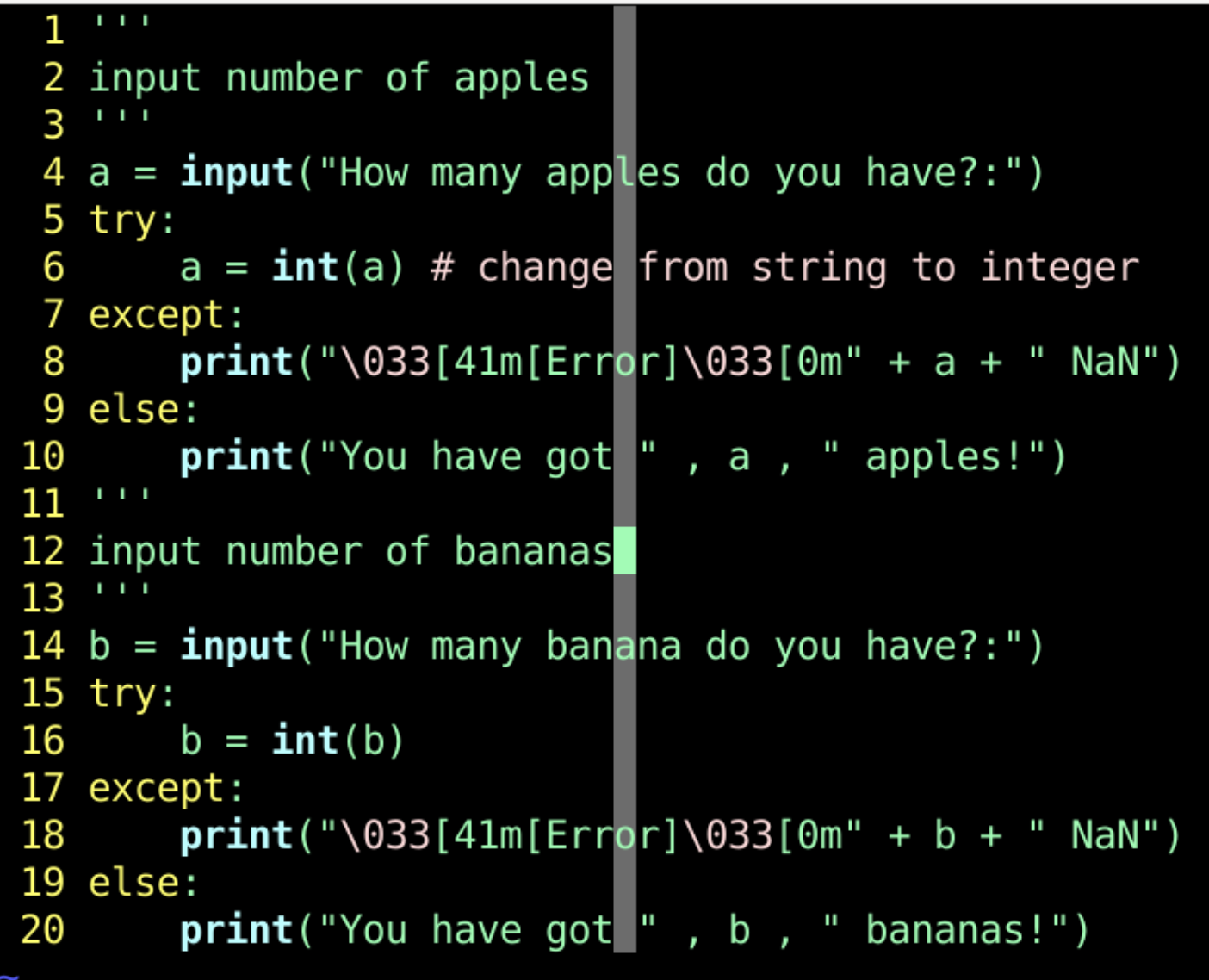
- 三引号里面的东西
- 就是注释
- 注释中 说明了
- 上面输入的 是苹果数量
- 下面 是香蕉数量
- 虽然注释 内容很长
- 但是 不会影响程序的 运行速度
- 只是增加 可读性而已
- 这次了解了注释
- 写注释 是为了让程序更可读
- 注释 不会 影响程序运行速度
- 注释分为两种
- 单行的
- 以#开头
- 不能是 字符串当中的#
- 多行的
- 三个"
- 三个'
- 多行注释
- 还有什么 特殊功能 么?
- 下次再说!
[oeasy]python0048_注释_comment_设置默认编码格式的更多相关文章
- eclipse设置默认编码格式为UTF-8
需要设置的几处地方为: Window->Preferences->General ->Content Type->Text->JSP 最下面设置为UTF-8 Window ...
- (转)eclipse设置默认编码格式为UTF-8
设置 需要设置的几处地方为: Window->Preferences->General ->Content Type->Text->JSP 最下面设置为UTF-8,可以设 ...
- 【eclipse】设置默认编码格式为UTF-8
需要设置的几处地方为: Window->Preferences->General ->Content Type->Text->JSP 最下面设置为UTF-8 Window ...
- tomcat 设置默认编码格式
在tomcat目录下 conf文件夹下的server.xml中: <Connector port="80" protocol="HTTP/1.1" ...
- eclipse和myeclipse设置默认编码格式为UTF-8
1:jsp页面设置默认为utf-8 以eclipse为例 2:java界面设置: Window->Preferences->General->Workspace 面板Text fil ...
- Eclipse之文件【默认编码格式设置】,防止乱码等问题
文件默认编码格式设置步骤如下: 这里显示的是workspace的视图 其他格式文件的视图如下:
- MyEclipse开发平台下如何将新建的JSP页面的默认编码格式设置为UTF-8--JSP
新建的JSP页面原始的编码格式是ISO-8859-1(测试的MyEclipse版本为2014),它是不支持中文,在预览JSP页面时会出现乱码的现象.当然自己手动改一下编码格式就好了,但是那太过麻烦,每 ...
- 如何在Eclipse中设置默认的JSP文件头部编码
如何在Eclipse中设置默认的JSP文件头部编码 一般,我们为了以后在导入和导出程序的时候(特别是项目较大,文件多)一般都默认文件编码格式为UTF-8 如果你通常都是通过Eclipse来编写程序,那 ...
- [saiku] 简化/汉化/设置默认页
上一篇分析了schema文件 [ http://www.cnblogs.com/avivaye/p/4877832.html] 在安装完毕Saiku后,由于是社区版本,所以界面上存在很多升级为商业版的 ...
- 百度ueditor上传图片时如何设置默认宽高度
百度ueditor上传图片时如何设置默认宽高度 一.总结 一句话总结:直接css或者js里面限制一下就好,可以用html全局限制一下图片的最大高度 直接css或者js里面限制一下就好,可以用html全 ...
随机推荐
- 关于MySQL数据库大字符串存取 类型选择
摘自:https://blog.csdn.net/weixin_40485506/article/details/83588169 关于MySQL数据库存储大字符串类型长度 根据所要存取字符长度及My ...
- wblockCloneObjects 写块克隆的使用
写块克隆可以把当前数据库的实体写入到另一个dwg文件中去.用法根deepclone类似,不过deepclone只能复制到同一数据库中,而写块克隆是在不同数据库中进行复制的.写块克隆也算是深度克隆,能把 ...
- jQuery模态框原理
<!-- 引入jQuery.js --> <script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquer ...
- 通过USB口扩展wan口上网(4G上网卡)
通过USB口扩展wan口上网(4G上网卡) 一.前言 现爱快可支持通过USB口扩展wan口上网,不再居于地点的限制,随时随地流畅上网. 二.具体配置 现在有两种设备可以实现通过USB口转化为wan口上 ...
- kvm链接克隆虚拟机迁移到openstack机器的实验
总结 如果是完整克隆的那种虚拟机,是可以直接在openstack使用的,如果镜像格式没问题的话. 因为kvm虚拟机大部分都是链接克隆出来的镜像,不可用直接复制使用,所以需要创建新的镜像文件 创建空盘: ...
- C#.NET HTTP Request 跳过自签名证书校验。
public static bool CheckValidationResult(object sender, X509Certificate certificate, X509Chain chain ...
- 《Android开发卷——自定义日期选择器(一)》
(小米手机) (中兴手机) 在实际开发中,Google官方提供的时间选择器API已经不能满足于我们的需要了,所以很多公司都是采用自定义的形式来实现日期选择器. 这个例子很简单,定义三个NumberPi ...
- Sass报错: Using / for division is deprecated
原因是:当sass版本>= 1.33.0时,会不支持 / 这种语法: 解决方式一: 降低sass版本,将sass版本换成:"sass": "^ ...
- 每天打卡一小时 第三十一天 PTA520钻石 争霸赛
第一题 源代码 #include<iostream> using namespace std; int main() { int n; cin>>n; cout<< ...
- 使用nc进行tcp测速
# server nc -l IP PORT > /dev/null eg: nc -l 192.168.144.1 8080 > /dev/null # client bs单位块大小 c ...