.NET平台开源项目速览(7)关于NoSQL数据库LiteDB的分页查询解决过程
在文章:这些.NET开源项目你知道吗?让.NET开源来得更加猛烈些吧!(第二辑) 与 .NET平台开源项目速览(3)小巧轻量级NoSQL文件数据库LiteDB中,介绍了LiteDB的基本使用情况以及部分技术细节,我还没有在实际系统中大量使用,但文章发布后,有不少网友( loogn)反应在实际项目中使用过,效果还可以吧。同时也有人碰到了关于LiteDB关于分页的问题,还不止一个网友,很显然这个问题从我的思考上来说,作者不可能不支持,同时也翻了一下源码,发现Find方法有skip和limite参数,直觉告诉我,这就是的。但是网友进一步提问,这个方法并不是很好用,它也没有实现的分页的情况。所以就亲自操刀,看看到底是神马情况?不看不知道,这个过程还真的不是那么回事,不过还是能解决啊。
.NET开源目录:【目录】本博客其他.NET开源项目文章目录
本文原文地址:.NET平台开源项目速览(7)关于NoSQL数据库LiteDB的分页查询解决过程
1.关于数据库排序与分页
在实际的项目中,对于关系型数据库,数据查询与排序都应该好办,升序或者降序呗,但是对数据库的分页应该不是直接的函数支持,也需要自己的应用程序中进行处理,然后使用top或者limite之类的来查询一定范围内的数据,作为一页,给前台。例如下面的SQL语句:
Select top PageSize * from TableA where Primary_Key not in
(select top (n-1)*PageSize Primary_Key from TableA )
数据的分页过程中,我们也看到在根据指定条件查询后,就是记录集的筛选,所以对于NoSQL数据库来说,因为没有了SQL,这些问题不会像常规关系型数据库那么突出,毕竟你选择了NoSQL,在大数据面前,如果动不动就查几千条数据来分页,也是明显不合适的。在我的观点中,要尽量避免无谓的查询浪费,也不会有人专门去看几千甚至几万条记录,如果有,也只是从中找到一部分数据,既然这样何必不一开始就增加条件,过滤掉那些没用的数据呢。所以数据库的那些事,业务的合理性也很重要,数据库也是机器,他们能力也有限,动不动就仍那么多沉重的任务给它,也会受不了啊。
2.LiteDB的查询排序
2.1 测试前准备工作
为了便于本文的相关代码演示,我们使用如下的一个实体类,注意Id的问题我们在前面一篇文章中已经说过了,默认是自增的,不需要处理。加进来是为了方便查询和分页。实体类基本代码如下:
public class Customer
{
/// <summary>自增Id,编号</summary>
public int Id { get; set; }
/// <summary>年龄</summary>
public int Age { get; set; }
/// <summary>姓名</summary>
public string Name { get; set; }
}
然后我们使用如下的方法插入20条记录,注意该函数是数据初始化,只需要运行一次即可。会在bin目录生成Sample数据库文件。我们只拿这些数据做测试。至于以后大数据的查询以及分页效率问题,暂时不考虑,我们只单独处理分页的情况。
static void InitialDB()
{
//打开或者创建新的数据库
using (var db = new LiteDatabase("sample.db"))
{
//获取 customers 集合,如果没有会创建,相当于表
var col = db.GetCollection<Customer>("customers");
for (int i = 0; i < 20; i++)
{
//创建 customers 实例
var customer = new Customer
{ //名字循环改变
Name = i % 2 == 1 ? "Jim1_" + i.ToString() : "Jim2" + i.ToString(),
Age = i,
};
// 将新的对象插入到数据表中,Id是自增,自动生成的
col.Insert(customer);
}
}
}
上面的Name是交替改变的,Jim1和Jim2加上编号,而Age是默认逐步增加了,主要是为了测试排序的情况。
2.2 基本查询与分页问题
我们在前面介绍LiteDB的基础文章。。中,对基本查询做了介绍。方法很灵活。针对上面的例子,我们假设一个查询分页的需求:
查Customer表中,Name以"Jim1"开头的人集合,按Age降序排列,每3条记录一页,打印每一页的Age列表。
针对上面问题,我们需要先简单分析一下问题:
1.查询获取记录的总数,可以使用Find或者Count方法直接获取;
2.查询条件的是Name,可以使用Linq或者Query来进行;
3.由于LiteDB是NoSQL的,所以不支持内部直接排序了,只能使用Linq的OrderBy或者OrderByDescending了;
4.关于分页,还是选择和SQL数据库类型的方法,使用linq的skip方法来跳过一些记录。这里留个疑问,因为自己技术有限,平时也只使用基本的linq操作,所以只想到了Skip,知道的朋友接着往下看,别吐槽。解决问题的最终结果可能很简单,但是过程还是值得回味的,一步步也是学习和总结优化的过程。
3.LiteDB分页之渐入佳境
由于Linq的Take以前不知道,所有走了一些弯路,同时LiteDB的Find方法中的重载函数之一,skip参数也有一些问题,下一节讲到具体问题。
3.1 第一次小试牛刀
考虑到类似SQL的limite和top查询,我们也在LiteDB中使用这种方式。由于Linq有一个Skip方法,所以选择它来完成具体数据的选择,相当于每次都选择最后几条。看代码:
//打开或者创建新的数据库
using (var db = new LiteDatabase("sample.db"))
{
//获取 customers 集合,如果没有会创建,相当于表
var col = db.GetCollection<Customer>("customers");
//1.计算总的数量
var totalCount = col.Count(Query.StartsWith("Name", "Jim1"));
//2.计算总的分页数量
Int32 pageSize = 3 ;//每一页的数量
var pages = (int)Math.Ceiling((double)totalCount / (double)pageSize);
//3.循环获取每一页的数据
Int32 current = int.MaxValue;
for (int i = 0; i < pages; i++)
{ //查找条件,附加了Id的范围,第一次是最大,后面进行更新
var data = col.Find(n => n.Name.StartsWith("Jim1") && n.Id < current)
.OrderBy(n => n.Age) //要求是降序,由于要选择最后的,只能先升序
.Skip(totalCount - (i + 1) * pageSize)//跳过前面页的记录
.OrderByDescending(n => n.Age); //降序排列
current = data.Last().Id;//更新当前查到的最大Id //把Id按照页的顺序打印出来
String res = String.Empty;
foreach (var item in data.Select(n => n.Age)) res += (item.ToString() + " , ");
Console.WriteLine(res);
}
}
结果如下:
最后1也只有1条记录,总共10条记录也是正常的,总共20条,交替插入的。缺点有几个:
1.效率比较低,每次都选最后的
2.只能从第1页获取,不能获取单独页的,因为上一次的Id不能得到
3.2 完全使用Linq分页
后来发现了Take方法,虽然我猜测应该有,但苦于自己疏忽,导致寻找的时候错过了,后来自己打算重新写一个的时候,又去确认一遍的时候才发现。因为skip都可以实现,没道理Take不实现啊,原理都是一样的。如果实现也很简单的。那看看改进版的基于Linq的分页。没有上面那么麻烦了:
//根据页面号直接获取
static void SplitPageByPageIndex(int index)
{
using (var db = new LiteDatabase("sample.db"))
{
var col = db.GetCollection<Customer>("customers");
//1.计算总的数量
var totalCount = col.Count(Query.StartsWith("Name", "Jim1"));
//2.计算总的分页数量
Int32 pageSize = 3;//每一页的数量
var pages = (int)Math.Ceiling((double)totalCount / (double)pageSize);
//查询条件
var data = col.Find(n => n.Name.StartsWith("Jim1"))
.OrderByDescending(n => n.Age)//降序
.Skip(index * pageSize) //跳过前面页数数量的记录
.Take(pageSize); //选择前面的记录作为当前页
//把id按照顺序打印出来
String res = String.Empty;
foreach (var item in data.Select(n => n.Age)) res += (item.ToString() + " , ");
Console.WriteLine(res);
}
}
结果如下:
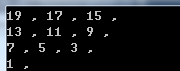
和上面是一样的,但这个显然要简洁多了。更加灵活,而且不用降序和升序直接转换,一次就够。
3.3 终极解决之扩展分页方法
根据上面方法,我们可以扩展到LiteDB中去,虽然我一直认为这一点可以做到,但是研究了很久的源码,测试一直不成功,详细内容第4节介绍。
我选择直接在源代码里面扩展,当然也可以单独写一个扩展方法,不过源码里面更好用,相当于给Find增加一个重载方法,我们在源代码的Find.cs中增加下面的方法,详细看注释:
/// <summary>分页获取记录</summary>
/// <typeparam name="TOder">排序字段类型</typeparam>
/// <param name="predicate">linq查询表达式</param>
/// <param name="orderSelector">排序表达式</param>
/// <param name="isDescending">是否降序,true降序</param>
/// <param name="pageSize">每页大小</param>
/// <param name="pageIndex">要获取的页码,从1开始</param>
/// <returns>分页后的数据</returns>
public IEnumerable<T> FindBySplitePage<TOder>(Expression<Func<T, bool>> predicate,
Func<T, TOder> orderSelector, Boolean isDescending, int pageSize, int pageIndex)
{
var allCount = Count(predicate);//计算总数
var pages = (int)Math.Ceiling((double)allCount / (double)pageSize);//计算页码
if (pageIndex > pages) throw new Exception("页面数超过预期");
if (isDescending)//降序
{
return Find(predicate)
.OrderByDescending(orderSelector)
.Skip((pageIndex - 1) * pageSize)
.Take(pageSize);
}
else //升序
{
return Find(predicate)
.OrderBy(orderSelector)
.Skip((pageIndex - 1) * pageSize)
.Take(pageSize);
}
}
下面还是使用上面的例子,直接进行调用:
var db = new LiteDatabase("sample.db");
var col = db.GetCollection<Customer>("customers");
//取第二页,降序
var data = col.FindBySplitePage<Int32>(n => n.Name.StartsWith("Jim1"), n => n.Age, true, 3, 2).ToList();
//把id按照顺序打印出来
String res = String.Empty;
foreach (var item in data.Select(n => n.Age)) res += (item.ToString() + " , ");
Console.WriteLine(res);
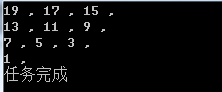
Console.WriteLine("任务完成");
结果如下,调用总体比较简单,直接使用linq,输入页面数量和页码就可以了。当然不需要排序也可以,大家可以根据实际情况优化一下。

到这里,分页的问题基本是解决了,但还得说一下研究LiteDB遇到的坑。
4.LiteDB的疑问
先看看下面一段普通的代码,查询出来的记录的Id的变化情况,没有排序:
using (var db = new LiteDatabase("sample.db"))
{
var col = db.GetCollection<Customer>("customers");
var data = col.Find(n => n.Name.StartsWith("Jim1"));//普通查询
//把Id按照页的顺序打印出来
String res = String.Empty;
foreach (var item in data.Select(n => n.Id)) res += (item.ToString() + " , ");
Console.WriteLine(res);
}
结果如下:
2 , 12 , 14 , 16 , 18 , 20 , 4 , 6 , 8 , 10 ,
是不是很奇怪?没有想象的是按照顺序输出。所以这个坑花了我好长时间,怎么试就是不行,既然这样的话,那么使用LiteDB自带的下面这个方法:
public IEnumerable<T> Find(Expression<Func<T, bool>> predicate, int skip = 0, int limit = int.MaxValue)
就有问题。这个方法skip的是按照上述顺序的。所以追根到底,还是因为直接的使用排序的方法?这里打个问号吧,说不定有,我没找到。如果有人比较熟悉的,可以告知一下,非常感谢。但是使用linq的方式也很容易的解决问题,应该差不了多少。
5.资源
本文的代码比较简单,所有代码都已经贴在上面了。所以就不放具体代码了,我打算好好把LiteDB的源码研究一下,为以后正式的抛弃Sqlite做准备。大家关注博客,如果研究比较深入,会把相关代码托管到github。这里研究还不够深入,代码比较简单,就省略了吧。
.NET平台开源项目速览(7)关于NoSQL数据库LiteDB的分页查询解决过程的更多相关文章
- .NET平台开源项目速览(17)FluentConsole让你的控制台酷起来
从该系列的第一篇文章 .NET平台开源项目速览(1)SharpConfig配置文件读写组件 开始,不知不觉已经到第17篇了.每一次我们都是介绍一个小巧甚至微不足道的.NET平台的开源软件,或者学习,或 ...
- .NET平台开源项目速览(15)文档数据库RavenDB-介绍与初体验
不知不觉,“.NET平台开源项目速览“系列文章已经15篇了,每一篇都非常受欢迎,可能技术水平不高,但足够入门了.虽然工作很忙,但还是会抽空把自己知道的,已经平时遇到的好的开源项目分享出来.今天就给大家 ...
- .NET平台开源项目速览(13)机器学习组件Accord.NET框架功能介绍
Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET Framework更注重与机器 ...
- .NET平台开源项目速览(1)SharpConfig配置文件读写组件
在.NET平台日常开发中,读取配置文件是一个很常见的需求.以前都是使用System.Configuration.ConfigurationSettings来操作,这个说实话,搞起来比较费劲.不知道大家 ...
- .NET平台开源项目速览(12)哈希算法集合类库HashLib
.NET的System.Security.Cryptography命名空间本身是提供加密服务,散列函数,对称与非对称加密算法等功能.实际上,大部分情况下已经满足了需求,而且.NET实现的都是目前国际上 ...
- .NET平台开源项目速览(11)KwCombinatorics排列组合使用案例(1)
今年上半年,我在KwCombinatorics系列文章中,重点介绍了KwCombinatorics组件的使用情况,其实这个组件我5年前就开始用了,非常方便,麻雀虽小五脏俱全.所以一直非常喜欢,才写了几 ...
- .NET平台开源项目速览(10)FluentValidation验证组件深入使用(二)
在上一篇文章:.NET平台开源项目速览(6)FluentValidation验证组件介绍与入门(一) 中,给大家初步介绍了一下FluentValidation验证组件的使用情况.文章从构建间的验证器开 ...
- .NET平台开源项目速览(9)软件序列号生成组件SoftwareProtector介绍与使用
在文章:这些.NET开源项目你知道吗?让.NET开源来得更加猛烈些吧!(第二辑)中,给大家初步介绍了一下Software Protector序列号生成组件.今天就通过一篇简单的文章来预览一下其强大的功 ...
- .NET平台开源项目速览(8)Expression Evaluator表达式计算组件使用
在文章:这些.NET开源项目你知道吗?让.NET开源来得更加猛烈些吧!(第二辑)中,给大家初步介绍了一下Expression Evaluator验证组件.那里只是概述了一下,并没有对其使用和强大功能做 ...
随机推荐
- Golang之chan/goroutine(转)
原文地址:http://tchen.me/posts/2014-01-27-golang-chatroom.html?utm_source=tuicool&utm_medium=referra ...
- Storm 中什么是-acker,acker工作流程介绍
概述 我们知道storm一个很重要的特性是它能够保证你发出的每条消息都会被完整处理, 完整处理的意思是指: 一个tuple被完全处理的意思是: 这个tuple以及由这个tuple所导致的所有的tupl ...
- 39个让你受益的HTML5教程
1. 五分钟入门HTML5 (Learn HTML5 in 5 Minutes!) By Jennifer Marsman 毫无疑问,HTML5是一个热门话题.如果你需要一个迅速了解HTML基础的速成 ...
- 9_bootstrap less 移动端
chrome,firefox提供了"Device Emulation"功能,可模拟常见的各种浏览设备 android ADT或ios Xcode附带的设备模拟器,或第三方在线测试工 ...
- Python 爬虫3——第一个爬虫脚本的创建
在进行真正的爬虫工程创建之前,我们先要明确我们所要操作的对象是什么?完成所有操作之后要获取到的数据或信息是什么? 首先是第一个问题:操作对象,爬虫全称是网络爬虫,顾名思义,它所操作的对象当然就是网页, ...
- 关于MVC的开源商城 Nop之闲聊
nopcommerce是国外的一个高质量的开源b2c网站系统,基于EntityFramework4.0和MVC3.0,使用Razor模板引擎,有很强的插件机制,包括支付配送功能都是通过插件来实现的,基 ...
- java的poi技术读取和导入Excel
项目结构: http://www.cnblogs.com/hongten/gallery/image/111987.html 用到的Excel文件: http://www.cnblogs.com/h ...
- 计数排序和桶排序(Java实现)
目录 比较和非比较的区别 计数排序 计数排序适用数据范围 过程分析 桶排序 网络流传桶排序算法勘误 桶排序适用数据范围 过程分析 比较和非比较的区别 常见的快速排序.归并排序.堆排序.冒泡排序等属于比 ...
- 使用CSS3制作三角形小图标
话不多说,直接写代码,希望能够对大家有所帮助! 1.html代码如下: <a href="#" class="usetohover"> <di ...
- Ajax是如何运行的?
1.我们需要知道什么是Ajax: AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML). AJAX 不是新的编程语言,而是一种使用现 ...