deep_learning_Function_bath_normalization()
关于归一化的讲解的博客——【深度学习】Batch Normalization(批归一化)
tensorflow实现代码在这个博客——【超分辨率】TensorFlow中批归一化的实现——tf.layers.batch_normalization()函数
tf.nn.batch_normalization()函数用于执行批归一化。
# 用于最中执行batch normalization的函数
tf.nn.batch_normalization(
x,
mean,
variance,
offset,
scale,
variance_epsilon,
name=None
)
1
2
3
4
5
6
7
8
9
10
参数:
x是input输入样本
mean是样本均值
variance是样本方差
offset是样本偏移(相加一个转化值)
scale是缩放(默认为1)
variance_epsilon是为了避免分母为0,添加的一个极小值
输出的计算公式为:
y=scale∗(x−mean)/var+offset y = scale * (x - mean) / var + offset
y=scale∗(x−mean)/var+offset
这里安利一个简单讲述batch normalization的文章,还有相应的代码,通俗易懂。
tensorflow-BatchNormalization(tf.nn.moments及tf.nn.batch_normalization)
————————————————
原文链接:https://blog.csdn.net/TeFuirnever/article/details/88911995
批标准化
批标准化(batch normalization,BN)一般用在激活函数之前,使结果x=Wx+bx=Wx+b 各个维度均值为0,方差为1。通过规范化让激活函数分布在线性区间,让每一层的输入有一个稳定的分布会有利于网络的训练。
优点:
加大探索步长,加快收敛速度。
更容易跳出局部极小。
破坏原来的数据分布,一定程度上防止过拟合。
解决收敛速度慢和梯度爆炸。
tensorflow相应API
mean, variance = tf.nn.moments(x, axes, name=None, keep_dims=False)
计算统计矩,mean 是一阶矩即均值,variance 则是二阶中心矩即方差,axes=[0]表示按列计算;
tf.nn.batch_normalization(x, mean, variance, offset, scale, variance_epsilon, name=None)
tf.nn.batch_norm_with_global_normalization(x, mean, variance, beta, gamma, variance_epsilon, scale_after_normalization, name=None);
tf.nn.moments 计算返回的 mean 和 variance 作为 tf.nn.batch_normalization 参数调用;
tensorflow及python实现
import tensorflow as tf
W = tf.constant([[-2.,12.,6.],[3.,2.,8.]], )
mean,var = tf.nn.moments(W, axes = [0])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
resultMean = sess.run(mean)
print(resultMean)
resultVar = sess.run(var)
print(resultVar)
[ 0.5 7. 7. ]
[ 6.25 25. 1. ]
计算每个列的均值及方差。
size = 3
scale = tf.Variable(tf.ones([size]))
shift = tf.Variable(tf.zeros([size]))
epsilon = 0.001
W = tf.nn.batch_normalization(W, mean, var, shift, scale, epsilon)
#参考下图BN的公式,相当于进行如下计算
#W = (W - mean) / tf.sqrt(var + 0.001)
#W = W * scale + shift

with tf.Session() as sess:
#必须要加这句不然执行多次sess会报错
sess.run(tf.global_variables_initializer())
resultW = sess.run(W)
print(resultW)
#观察初始W第二列 12>2 返回BN的W值第二列第二行是负的,其余两列相反
[[-0.99992001 0.99997997 -0.99950027]
[ 0.99991995 -0.99997997 0.99950027]]
Bug
Attempting to use uninitialized value Variable_8:
#运行sess.run之前必须要加这句不然执行多次sess会报错
sess.run(tf.global_variables_initializer())
参考
深度学习Deep Learning(05):Batch Normalization(BN)批标准化
谈谈Tensorflow的Batch Normalization
tensorflow 的 Batch Normalization 实现(tf.nn.moments、tf.nn.batch_normalization)
————————————————
原文链接:https://blog.csdn.net/eclipsesy/article/details/77597965
tensorflow 在实现 Batch Normalization(各个网络层输出的归一化)时,主要用到以下两个 api:
tf.nn.moments(x, axes, name=None, keep_dims=False) ⇒ mean, variance:
统计矩,mean 是一阶矩,variance 则是二阶中心矩
tf.nn.batch_normalization(x, mean, variance, offset, scale, variance_epsilon, name=None)
https://www.tensorflow.org/api_docs/python/tf/nn/batch_normalization
γ⋅x−μσ+β \gamma\cdot\frac{x-\mu}{\sigma}+\beta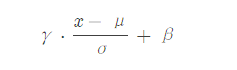
γ 表示 scale 缩放因子,β \betaβ 表示偏移量;
tf.nn.batch_norm_with_global_normalization(t, m, v, beta, gamma, variance_epsilon, scale_after_normalization, name=None)
由函数接口可知,tf.nn.moments 计算返回的 mean 和 variance 作为 tf.nn.batch_normalization 参数进一步调用;
1. tf.nn.moments,矩
tf.nn.moments 返回的 mean 表示一阶矩,variance 则是二阶中心矩;
如我们需计算的 tensor 的 shape 为一个四元组 [batch_size, height, width, kernels],一个示例程序如下:
import tensorflow as tf
shape = [128, 32, 32, 64]
a = tf.Variable(tf.random_normal(shape)) # a:activations
axis = list(range(len(shape)-1)) # len(x.get_shape())
a_mean, a_var = tf.nn.moments(a, axis)
这里我们仅给出 a_mean, a_var 的维度信息,
sess = tf.Session()
sess.run(tf.global_variables_initalizer()) sess.run(a_mean).shape # (64, )
sess.run(a_var).shape # (64, ) ⇒ 也即是以 kernels 为单位,batch 中的全部样本的均值与方差
2. demo
def batch_norm(x):
epsilon = 1e-3
batch_mean, batch_var = tf.nn.moments(x, [0])
return tf.nn.batch_normalization(x, batch_mean, batch_var,
offset=None, scale=None,
variance_epsilon=epsilon)
references
<a href=“http://www.jianshu.com/p/0312e04e4e83”, target="_blank">谈谈Tensorflow的Batch Normalization
————————————————
原文链接:https://blog.csdn.net/lanchunhui/article/details/70792458
deep_learning_Function_bath_normalization()的更多相关文章
随机推荐
- np.where()
numpy.where (condition[, x, y]) numpy.where()两种用法 1. np.where(condition, x, y) 满足条件(condition),输出x,不 ...
- Proxmox
vmware: vmware 12 pro proxmox 下载地址 往下会比较麻烦一点,这里就不做展示了(仅供参考)
- Linux 服务器基本优化
一:修改ulimit数 vi /etc/security/limits.conf 添加如下行: * soft noproc 65535 * hard noproc 65535 * soft nofil ...
- [Python]机器学习:Tensorflow实现线性回归
源码 #> tutorial:https://www.cnblogs.com/xianhan/p/9090426.html # 步骤一:构建模型 # 1.TensorFlow 中的线性模型 ## ...
- 异常之【You have an error in your SQL syntax】
异常如下: ### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException ...
- Anaconda环境配置常用命令
1. 新建一个环境: conda create -n ForPytorch python=3.6 该行命令新建了一个叫做ForPytorch的环境,该环境使用的python是3.6版本.新建一个环境的 ...
- javascrit-function中this的指向问题
javascrit中this的指向 全局作用域或者普通函数中 this 指向全局对象 window. //直接打印 console.log(this) //window //function声明函数 ...
- 6.maven的安装
JAVA配置 JAVA_HOME=安装目录 PATH=%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin CLASSPATH=%JAVA_HOME%\lib\dt.jar;%JAV ...
- 关于前端JS判断字符串是否包含另外一个字符串的方法总结
RegExp 对象方法 test() var str = "abcd"; var reg = RegExp(/d/); console.log(reg.test(str)); // ...
- 2-SAT问题介绍求解 + 模板题P4782
(点击此处查看原题) 什么是2-SAT问题 sat 即 Satisfiability,意思为可满足,那么2-SAT表示一些布尔变量只能取true或者false,而某两个变量之间的值存在一定的关系(如: ...