7.编写mapreduce案例
在写一个mapreduce类之前先添加依赖包
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.it19gong</groupId>
<artifactId>testmaven</artifactId>
<version>0.0.-SNAPSHOT</version>
<packaging>jar</packaging> <name>testmaven</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.mrunit</groupId>
<artifactId>mrunit</artifactId>
<version>1.1.</version>
<classifier>hadoop2</classifier>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-minicluster</artifactId>
<version>2.6.</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.</version>
<scope>provided</scope>
</dependency> </dependencies>
</project>
新建一个WordCountMapper类


package com.it19gong.testmaven; import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for(String word:words)
{
context.write(new Text(word), new IntWritable());
}
}
}
定义WordCountReducer类
package com.it19gong.testmaven; import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = ;
//遍历这一组kv的所有v,累加到count中
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
定义WordCountRunner类
package com.it19gong.testmaven; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountRunner {
//把业务逻辑相关的信息(哪个是mapper,哪个是reducer,要处理的数据在哪里,输出的结果放哪里……)描述成一个job对象
//把这个描述好的job提交给集群去运行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
//指定我这个job所在的jar包
// wcjob.setJar("/home/hadoop/wordcount.jar");
wcjob.setJarByClass(WordCountRunner.class); wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
//设置我们的业务逻辑Mapper类的输出key和value的数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//设置我们的业务逻辑Reducer类的输出key和value的数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class); //指定要处理的数据所在的位置
// FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt");
FileInputFormat.setInputPaths(wcjob, new Path(args[]));
//指定处理完成之后的结果所保存的位置
// FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/"));
FileOutputFormat.setOutputPath(wcjob, new Path(args[])); //向yarn集群提交这个job
boolean res = wcjob.waitForCompletion(true);
System.exit(res?:);
}
}
打成架包
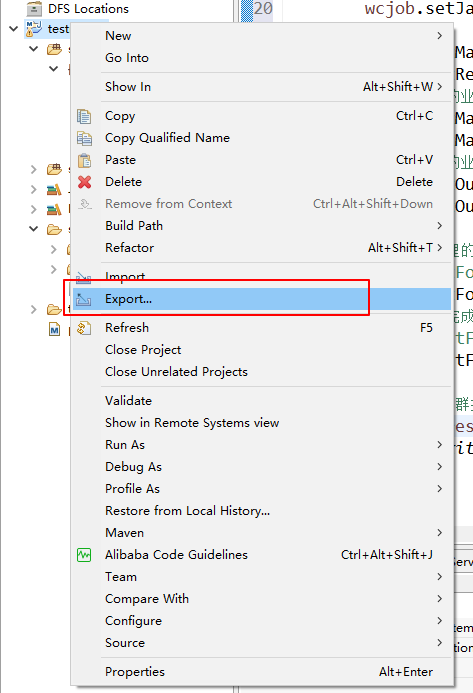
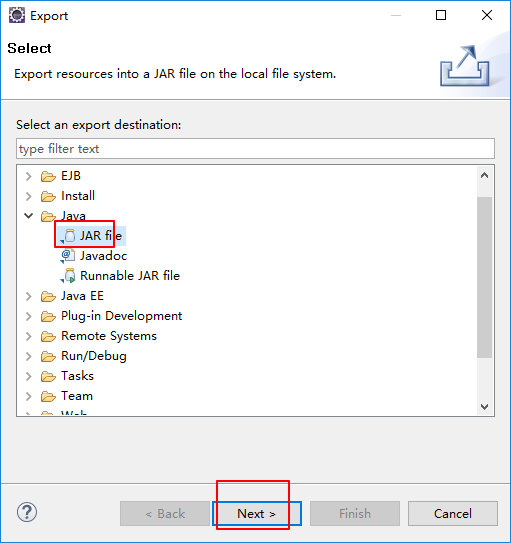
把打包好的架包上传到集群

然后在集群上运行一个wordcount小案例
hadoop jar mr.jar com.it19gong.testmaven.WordCountRunner /wc_input /wc_output



7.编写mapreduce案例的更多相关文章
- hive--构建于hadoop之上、让你像写SQL一样编写MapReduce程序
hive介绍 什么是hive? hive:由Facebook开源用于解决海量结构化日志的数据统计 hive是基于hadoop的一个数据仓库工具,可以将结构化的数据映射为数据库的一张表,并提供类SQL查 ...
- [Hadoop in Action] 第4章 编写MapReduce基础程序
基于hadoop的专利数据处理示例 MapReduce程序框架 用于计数统计的MapReduce基础程序 支持用脚本语言编写MapReduce程序的hadoop流式API 用于提升性能的Combine ...
- Hadoop:使用Mrjob框架编写MapReduce
Mrjob简介 Mrjob是一个编写MapReduce任务的开源Python框架,它实际上对Hadoop Streaming的命令行进行了封装,因此接粗不到Hadoop的数据流命令行,使我们可以更轻松 ...
- mapreduce案例:获取PI的值
mapreduce案例:获取PI的值 * content:核心思想是向以(0,0),(0,1),(1,0),(1,1)为顶点的正方形中投掷随机点. * 统计(0.5,0.5)为圆心的单位圆中落点占总落 ...
- 【Hadoop离线基础总结】MapReduce案例之自定义groupingComparator
MapReduce案例之自定义groupingComparator 求取Top 1的数据 需求 求出每一个订单中成交金额最大的一笔交易 订单id 商品id 成交金额 Order_0000005 Pdt ...
- MapReduce案例:统计共同好友+订单表多表合并+求每个订单中最贵的商品
案例三: 统计共同好友 任务需求: 如下的文本, A:B,C,D,F,E,OB:A,C,E,KC:F,A,D,ID:A,E,F,LE:B,C,D,M,LF:A,B,C,D,E,O,MG:A,C,D,E ...
- Hadoop Mapreduce 案例 wordcount+统计手机流量使用情况
mapreduce设计思想 概念:它是一个分布式并行计算的应用框架它提供相应简单的api模型,我们只需按照这些模型规则编写程序,即可实现"分布式并行计算"的功能. 案例一:word ...
- Hadoop:使用原生python编写MapReduce
功能实现 功能:统计文本文件中所有单词出现的频率功能. 下面是要统计的文本文件 [/root/hadooptest/input.txt] foo foo quux labs foo bar quux ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
随机推荐
- AfxMessageBox与MessageBox用法与区别
https://blog.csdn.net/holybin/article/details/28403109 MessageBox()是标准的Win32 API函数,可以直接使用: AfxMessag ...
- 阿里云Ubuntu安装LNMP环境之Mysql
在QQ群很多朋友问阿里云服务器怎么安装LNMP环境,怎么把项目放到服务器上面去,在这里,我就从头开始教大家怎么在阿里云服务器安装LNMP环境. 在这之前,我们先要知道什么是LNMP. L: 表示的是L ...
- WM_PAINT(父子窗口间)
WM_PAINT(父子窗口间) 窗口句柄(HWND)都是由操作系统内核管理的,系统内部有一个z-order序列,记录着当前从屏幕底部(假象的从屏幕到眼睛的方向),到屏幕最高层的一个窗口句柄的排序,这个 ...
- OpsManage安装过程中遇到的问题和解决方案
系统地址:https://github.com/welliamcao/OpsManage 系统:ubuntu ubuntu使用apt-get进行自动化安装 自带python2.7,不需要再次安装 1. ...
- 面试题_Spring基础篇
Spring基础题 1. 什 么 是 Spring? Spring 是 个 java 企 业 级 应 用 的 开 源 开 发 框 架 .Spring 主 要 用 来 开 发 Java 应 用 , 但 ...
- nc浏览器的十宗罪
1.收藏夹.nc浏览器收藏夹无法导出或者导出困难,十分恶心.其他的小众软件都有这个简单的功能,某天我突然想到为什么手机nc浏览器连个导出收藏夹的功能都没有,并不是不注重用户体验,或则导功能很难实现不会 ...
- 1.3 JAVA规范以及基础语法(if条件和循环)
一.规范以及运算符 1.命名规则 类名大驼峰规则方法名.变量名小驼峰原则常量大写.下划线分开见名释义.不与关键字冲突 关键字链接:https://www.runoob.com/java/java-ba ...
- Visual Studio Code(VS code)介绍
一.日常安利 VS code VS vode特点: 开源,免费: 自定义配置 集成git 智能提示强大 支持各种文件格式(html/jade/css/less/sass/xml) 调试功能强大 各种方 ...
- pwn学习日记Day5 基础知识积累
知识杂项 int mprotect(const void *start, size_t len, int prot); mprotect()函数把自start开始的.长度为len的内存区的保护属性修改 ...
- requests和BeautifulSoup模块的使用
用python写爬虫时,有两个很好用第三方模块requests库和beautifulsoup库,简单学习了下模块用法: 1,requests模块 Python标准库中提供了:urllib.urllib ...