7.编写mapreduce案例
在写一个mapreduce类之前先添加依赖包
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.it19gong</groupId>
<artifactId>testmaven</artifactId>
<version>0.0.-SNAPSHOT</version>
<packaging>jar</packaging> <name>testmaven</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.mrunit</groupId>
<artifactId>mrunit</artifactId>
<version>1.1.</version>
<classifier>hadoop2</classifier>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.6.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-minicluster</artifactId>
<version>2.6.</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.</version>
<scope>provided</scope>
</dependency> </dependencies>
</project>
新建一个WordCountMapper类


package com.it19gong.testmaven; import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for(String word:words)
{
context.write(new Text(word), new IntWritable());
}
}
}
定义WordCountReducer类
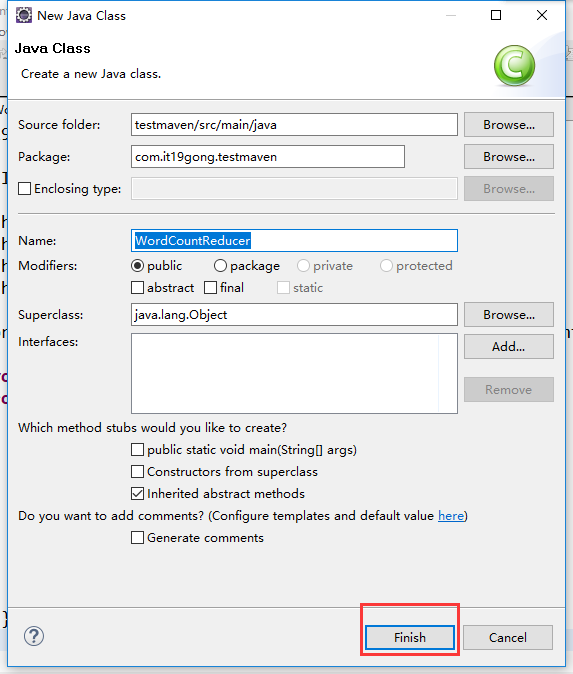
package com.it19gong.testmaven; import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = ;
//遍历这一组kv的所有v,累加到count中
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
定义WordCountRunner类
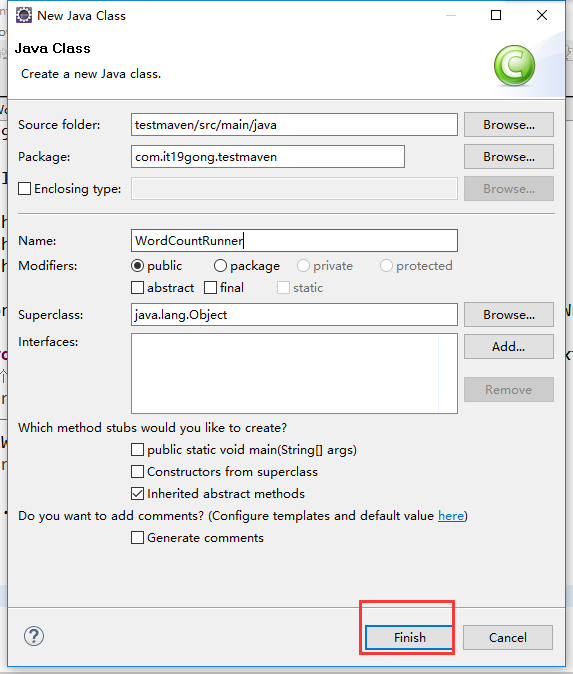
package com.it19gong.testmaven; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountRunner {
//把业务逻辑相关的信息(哪个是mapper,哪个是reducer,要处理的数据在哪里,输出的结果放哪里……)描述成一个job对象
//把这个描述好的job提交给集群去运行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
//指定我这个job所在的jar包
// wcjob.setJar("/home/hadoop/wordcount.jar");
wcjob.setJarByClass(WordCountRunner.class); wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
//设置我们的业务逻辑Mapper类的输出key和value的数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//设置我们的业务逻辑Reducer类的输出key和value的数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class); //指定要处理的数据所在的位置
// FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt");
FileInputFormat.setInputPaths(wcjob, new Path(args[]));
//指定处理完成之后的结果所保存的位置
// FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/"));
FileOutputFormat.setOutputPath(wcjob, new Path(args[])); //向yarn集群提交这个job
boolean res = wcjob.waitForCompletion(true);
System.exit(res?:);
}
}
打成架包
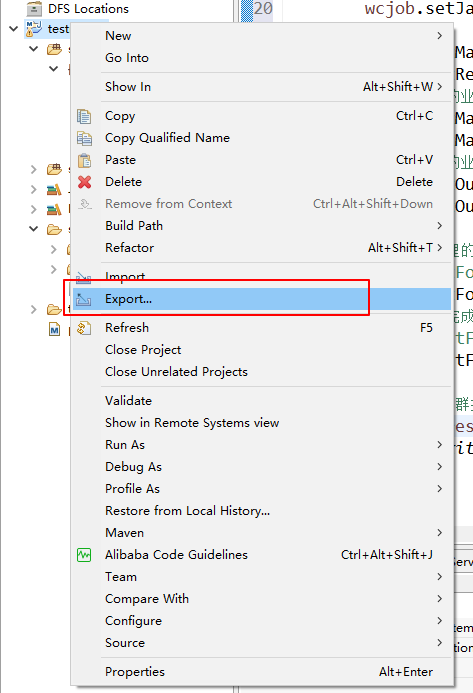
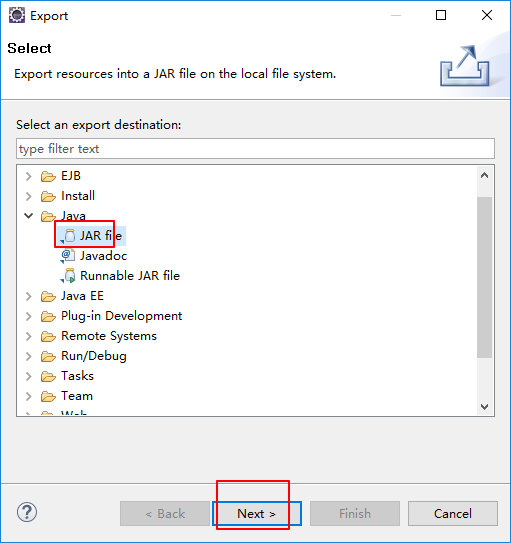
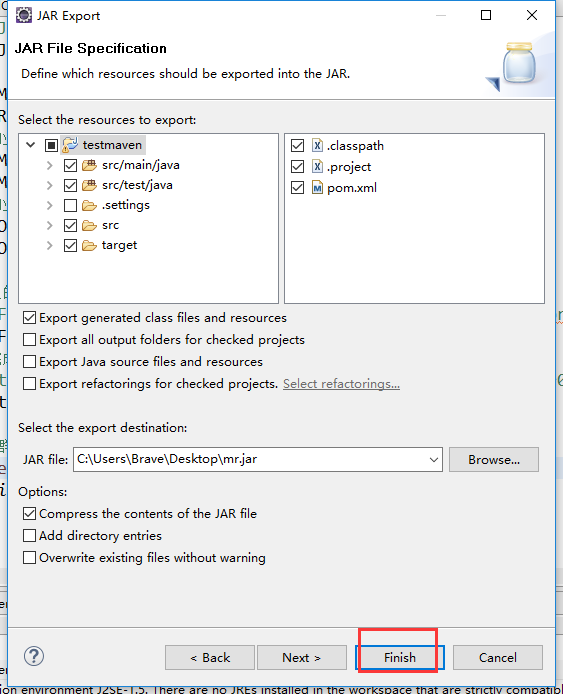
把打包好的架包上传到集群

然后在集群上运行一个wordcount小案例
hadoop jar mr.jar com.it19gong.testmaven.WordCountRunner /wc_input /wc_output



7.编写mapreduce案例的更多相关文章
- hive--构建于hadoop之上、让你像写SQL一样编写MapReduce程序
hive介绍 什么是hive? hive:由Facebook开源用于解决海量结构化日志的数据统计 hive是基于hadoop的一个数据仓库工具,可以将结构化的数据映射为数据库的一张表,并提供类SQL查 ...
- [Hadoop in Action] 第4章 编写MapReduce基础程序
基于hadoop的专利数据处理示例 MapReduce程序框架 用于计数统计的MapReduce基础程序 支持用脚本语言编写MapReduce程序的hadoop流式API 用于提升性能的Combine ...
- Hadoop:使用Mrjob框架编写MapReduce
Mrjob简介 Mrjob是一个编写MapReduce任务的开源Python框架,它实际上对Hadoop Streaming的命令行进行了封装,因此接粗不到Hadoop的数据流命令行,使我们可以更轻松 ...
- mapreduce案例:获取PI的值
mapreduce案例:获取PI的值 * content:核心思想是向以(0,0),(0,1),(1,0),(1,1)为顶点的正方形中投掷随机点. * 统计(0.5,0.5)为圆心的单位圆中落点占总落 ...
- 【Hadoop离线基础总结】MapReduce案例之自定义groupingComparator
MapReduce案例之自定义groupingComparator 求取Top 1的数据 需求 求出每一个订单中成交金额最大的一笔交易 订单id 商品id 成交金额 Order_0000005 Pdt ...
- MapReduce案例:统计共同好友+订单表多表合并+求每个订单中最贵的商品
案例三: 统计共同好友 任务需求: 如下的文本, A:B,C,D,F,E,OB:A,C,E,KC:F,A,D,ID:A,E,F,LE:B,C,D,M,LF:A,B,C,D,E,O,MG:A,C,D,E ...
- Hadoop Mapreduce 案例 wordcount+统计手机流量使用情况
mapreduce设计思想 概念:它是一个分布式并行计算的应用框架它提供相应简单的api模型,我们只需按照这些模型规则编写程序,即可实现"分布式并行计算"的功能. 案例一:word ...
- Hadoop:使用原生python编写MapReduce
功能实现 功能:统计文本文件中所有单词出现的频率功能. 下面是要统计的文本文件 [/root/hadooptest/input.txt] foo foo quux labs foo bar quux ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
随机推荐
- Linq to XML - C#生成XML
1.System.Xml.XmlDocument XML file转成字符串 string path3 = @"C:\Users\test.xml"; XmlDocument ...
- 洛谷P2110 欢总喊楼记
洛谷题目链接 乱搞qwq 我们其实可以找规律,对于每个数$x$,我们先求出从$1$~$x$中有多少符合条件的,记为$sum[x]$,那么类似于前缀和,答案自然就是$sum[r]-sum[l-1]$了 ...
- 洛谷P2787 语文1(chin1)- 理理思维
洛谷题目链接 珂朵莉树吼啊!!! 对于操作$1$,直接普通查询即可 对于操作$2$,直接区间赋值即可 对于操作$3$,其实也并不难,来一次计数排序后,依次插入即可,(注意初始化计数器数组)具体实现看代 ...
- hdu 3555 Bomb(数位dp入门)
Bomb Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/65536 K (Java/Others) Total Subm ...
- assert 笔记
目录 什么是assert? assert使用 assert错误使用 什么是assert? Python 的 assert 语句是一个 debug 的好工具,主要用于测试一个条件是否满足.如果测试的条件 ...
- Java中jdk代理和cglib代理
代理模式 给某一个对象提供一个代理,并由代理对象控制对原对象的引用.在一些情况下,一个客户不想或者不能够直接引用一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用. 在Java中代理模式从实 ...
- Druid数据源监控配置
在web.xml中添加如下代码 <!-- druid监控 --> <servlet> <servlet-name>DruidStatView</servlet ...
- 消息中间件RabbitMQ的使用
原理场景 MQ在所有项目里面都很常见, 1.减少非紧急性任务对整个业务流程造成的延时: 2.减少高并发对系统所造成的性能上的影响: 举例几个场景: 1.给注册完成的用户派发优惠券.加积分.发消息等(派 ...
- LeetCode 200. 岛屿的个数(Number of Islands)
题目描述 给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量.一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的.你可以假设网格的四个边均被水包围. 示例 1 ...
- POJ3009-Curling 2.0(WA)
POJ3009-Curling 2.0 题意: 要求把一个冰壶从起点“2”用最少的步数移动到终点“3” 其中0为移动区域,1为石头区域,冰壶一旦想着某个方向运动就不会停止,也不会改变方向(想想冰壶在冰 ...