05.网站点击流数据分析项目_模块开发_ETL
项目的数据分析过程在hadoop集群上实现,主要应用hive数据仓库工具,因此,采集并经过预处理后的数据,需
要加载到hive数据仓库中,以进行后续的挖掘分析。
ETL:用来描述将数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程
6.1创建原始数据表
--在hive仓库中建贴源数据表
drop table if exists shizhan.ods_weblog_origin;
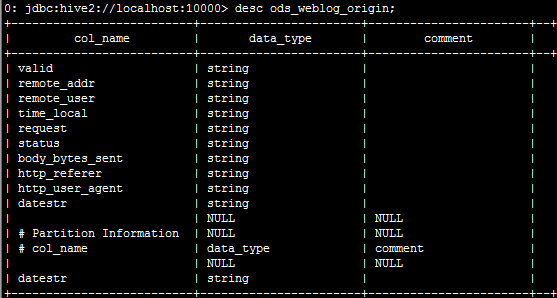
create table shizhan.ods_weblog_origin(
valid string,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
--点击流模型pageviews表
drop table if exists ods_click_pageviews;
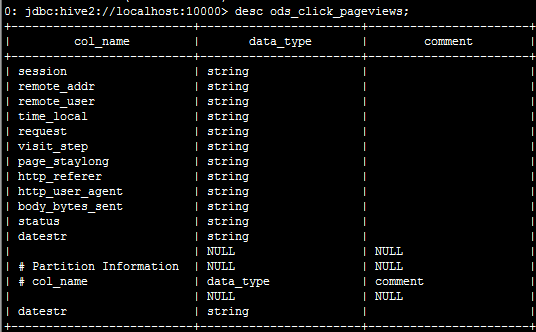
create table ods_click_pageviews(
Session string,
remote_addr string,
remote_user string,
time_local string,
request string,
visit_step string,
page_staylong string,
http_referer string,
http_user_agent string,
body_bytes_sent string,
status string)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
--点击流visit模型表
drop table if exist click_stream_visit;
create table click_stream_visit(
session string,
remote_addr string,
inTime string,
outTime string,
inPage string,
outPage string,
referal string,
pageVisits int)
partitioned by (datestr string);
6.2 导入数据
1.首先将日志文件上传至服务器,原则上是在HDFS上的(wash_part-m-00000、pageview_part-r-00000、visiout_part-r-00000)
2.导入清洗结果数据到贴源数据表:ods_weblog_origin
load data local inpath '/data/wash_part-m-00000' into table ods_weblog_origin partition(datestr='2013-09-18');
3.导入点击流模型pageviews数据到:ods_click_pageviews
load data local inpath '/data/pageview_part-r-00000' into table ods_click_pageviews partition(datestr='2013-09-18');
4.导入点击流模型visit数据到:click_stream_visit
load data local inpath '/data/visiout_part-r-00000' into table click_stream_visit partition(datestr='2013-09-18');
6.3 生成ODS层明细宽表
6.3.1 需求概述
整个数据分析的过程是按照数据仓库的层次分层进行的,总体来说,是从操作数据存储ODS原始数据中整理出一
些中间表(比如,为后续分析方便,将原始数据中的时间、url等非结构化数据作结构化抽取,将各种字段信息进行细化,
形成明细表),然后再在中间表的基础之上统计出各种指标数据
6.3.2 ETL实现:
建表——明细表ods_weblog_detail (源:ods_weblog_origin) (目标:ods_weblog_detail)
drop table ods_weblog_detail;
create table ods_weblog_detail(
valid string, --有效标识
remote_addr string, --来源IP
remote_user string, --用户标识
time_local string, --访问完整时间
daystr string, --访问日期
timestr string, --访问时间
month string, --访问月
day string, --访问日
hour string, --访问时
request string, --请求的url
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源url
ref_host string, --来源的host
ref_path string, --来源的路径
ref_query string, --来源参数query
ref_query_id string, --来源参数query的值
http_user_agent string --客户终端标识
)
partitioned by(datestr string);
抽取refer_url,将来访url分离出host path query query id,抽取转换time_local字段
insert into table ods_weblog_detail partition(datestr='2013-09-18')
select c.valid,c.remote_addr,c.remote_user,c.time_local,
substring(c.time_local,0,10) as daystr,
substring(c.time_local,12) as tmstr,
substring(c.time_local,6,2) as month,
substring(c.time_local,9,2) as day,
substring(c.time_local,11,3) as hour,
c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent
from
(SELECT
a.valid,a.remote_addr,a.remote_user,a.time_local,
a.request,a.status,a.body_bytes_sent,a.http_referer,a.http_user_agent,b.ref_host,b.ref_path,b.ref_query,b.ref_query_id
FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as ref_host, ref_path, ref_query, ref_query_id) c
操作数据存储ODS
05.网站点击流数据分析项目_模块开发_ETL的更多相关文章
- python-django框架-电商项目-订单模块开发_20191125
python-django框架-电商项目-订单模块开发 提交订单页面: 在购物车中点击提交订单,就应该到达提交订单页面了, 显示: 1,收获地址, 2,支付方式 3,用户购买的商品信息,数量,小计, ...
- python-django框架-电商项目-购物车模块开发_20191125
python-django框架-电商项目-购物车模块开发 商品详情页js代码: 在商品详情页,有加入购物车按钮, 点击加减号可以增加减少,手动输入也可以, 点击加入购物车,就要加过去, 先实现加减的操 ...
- 第1节 网站点击流项目(上):4、网站的数据采集,使用flume的taildir实现多个文件的监控采集
一. 模块开发----数据采集 1. 需求 在网站web流量日志分析这种场景中,对数据采集部分的可靠性.容错能力要求通常不会非常严苛,因此使用通用的flume日志采集框架完全可以满足需求. 2. Fl ...
- 第2节 网站点击流项目(下):6、访客visit分析
0: jdbc:hive2://node03:10000> select * from ods_click_stream_visit limit 2;+--------------------- ...
- 第2节 网站点击流项目(下):7、hive的级联求和
一.hive级联求和的简单例子: create table t_salary_detail(username string,month string,salary int)row format del ...
- 第2节 网站点击流项目(下):3、流量统计分析,分组求topN
四. 模块开发----统计分析 select * from ods_weblog_detail limit 2;+--------------------------+---------------- ...
- 05传智_jbpm与OA项目_部门模块中增加部门的jsp页面增加一个在线编辑器功能
这篇文章讲的是在线编辑器功能,之前的部门模块中,增加部门的功能jsp页面起先是这么做的.
- 大数据学习——SparkStreaming整合Kafka完成网站点击流实时统计
1.安装并配置zk 2.安装并配置Kafka 3.启动zk 4.启动Kafka 5.创建topic [root@mini3 kafka]# bin/kafka-console-producer. -- ...
- python-django框架-电商项目-用户模块开发_20191117
实现注册的基本逻辑: 1,注册页面 注意:注册页面需要静态文件的支持,另外注册页面是基础基类的, 1,url,路由系统, 2,views,视图系统,还是使用类视图,里面有很多的函数, 2,views. ...
随机推荐
- PowerDesigner的安装和数据库创建
PowerDesigner安装方法: http://dev.firnow.com/course/3_program/java/javajs/20090908/174375.html 安装完这2个软件 ...
- iOS-宏定义
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAnoAAAPCCAYAAADvRHWgAAAAAXNSR0IArs4c6QAAAZ1pVFh0WE1MOm ...
- 【c# 学习笔记】c#中的类
1.什么是类: 在c#中类是一种数据结构,它可以包括数据成员.函数成员(方法.属性.事件.索引器.索引符.实例构造函数.静态构造函数和析构函数.及嵌套类型). 属性是,类中字段和方法的结合体,通过定义 ...
- 斑马打印机和欧姆龙CP1H串口通信打印
欧姆龙CP1HPLC和斑马打印机通信 1. PLC 1.1PLC型号 CP1H 1.2通信方式 232通信,使用232扩展卡槽CP1W-CIF01. CP1W-CIF01是RS232选件板,通信距离最 ...
- 最新 字节跳动java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.字节跳动等10家互联网公司的校招Offer,因为某些自身原因最终选择了字节跳动.6.7月主要是做系统复习.项目复盘.Leet ...
- Win10下 jdk的安装
jdk 的下载地址 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 在 D 盘 ...
- 1024多人激情在线聊天室---select函数的使用
效果展示 step1.服务器启动!端口号3006 step2.1号客户端启动!jack加入了群聊 step3.2号客户端启动!kelly加入了群聊 step4.3号客户端启动!zwj加入了群聊 ste ...
- socket通信时如何判断当前连接是否断开--select函数,心跳线程,QsocketNotifier监控socket
client与server建立socket连接之后,如果突然关闭server,此时,如果不在客户端close(socket_fd),会有不好的影响: QsocketNotifier监控socket的槽 ...
- C++ 编译错误 jump to case label [-fpermissive]
<花的微笑>--- 钢琴曲,石进 今天再用C++写代码时,出现了编译错误 jump to case label [-fpermissive] 原因:使用switch语句时,再case中定义 ...
- mysql中char和varchar区别
char是一种固定长度的类型,varchar则是一种可变长度的类型 char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足.(在检索操作中那些 ...